Learn more about Search Results MPT - Page 68

- You may be interested
- ChatGPTのコードインタプリター:知ってお...
- 「GPTモデルの信頼性に関する詳細な分析」
- Google AIは、Symbol Tuningを導入しまし...
- ウェアラブルフィットネストラッカー:早...
- 「AIコーディングツールが必要なエンジニ...
- 創造力の解放:生成AI芸術アプリケーショ...
- 「ゴリラ – API呼び出しの使用能力...
- 「スクラッチからのPythonにおける最急降...
- 「ODSC West Bootcamp Roadmapのご紹介 &#...
- 「データクリーニングと前処理の技術をマ...
- JAXを使用して研究を加速化する
- 「30/10から5/11までの週の、トップで重要...
- 「アマゾン、アントロピックへの40億ドル...
- 新たなAIツールは、より高度な天体生物学...
- 「ChatGPTにおける適切なプロンプト設計の...

「このように考えて私に答えてください:このAIアプローチは、大規模な言語モデルをガイドするためにアクティブなプロンプティングを使用します」
最近の数ヶ月で、ChatGPTの導入により私たちは大規模な言語モデル (LLM) によく馴染みました。それは私たちの日常生活で欠かせないツールとなりました。LLMは情報検索、チャットサポート、執筆補助などに有用です。 一般的に、LLMは強力な推論能力を持っており、与えられた情報に基づいて論理的な推論や演繹を行い、解決策にたどり着くことができます。彼らは推論を行い、結論を導き出し、情報の断片を論理的に結びつけることができます。例えば、「数列があるとします: 2, 4, 6, 8, 10, … 次の数は何ですか?」という質問に答えることができます。 推論タスクは、より単純な言語理解タスクよりも難しいとされており、より高いレベルの理解力と推論能力を必要とします。LLMはそれに長けていますが、複雑な推論タスクで優れたパフォーマンスを発揮するように求めると、事態は変わってきます。 LLMを導く一つの方法は、文脈に即した学習です。これは、メインの要求を送る前に、LLMに実際に尋ねたい内容を教えるために、一連の質問と回答の例を与えるものです。例えば、「数列があるとします: 2, 4, 6, 8, 10, … 次の数は何ですか?」というプロンプトを「Q: 数列があるとします: 2, 4, 6,…

「インテルCPU上での安定したディフューションモデルのファインチューニング」
拡散モデルは、テキストのプロンプトから写真のようなリアルな画像を生成するというその驚異的な能力によって、生成型AIの普及に貢献しました。これらのモデルは現在、合成データの生成やコンテンツ作成などの企業のユースケースに取り入れられています。Hugging Faceハブには、5,000以上の事前学習済みのテキストから画像へのモデルが含まれています。Diffusersライブラリと組み合わせることで、実験や画像生成ワークフローの構築がこれまで以上に簡単になりました。 Transformerモデルと同様に、Diffusionモデルをファインチューニングしてビジネスニーズに合ったコンテンツを生成することができます。初期のファインチューニングはGPUインフラストラクチャー上でのみ可能でしたが、状況は変わってきています!数か月前、インテルはSapphire Rapidsというコードネームの第4世代のXeon CPUを発売しました。Sapphire Rapidsは、ディープラーニングワークロードのための新しいハードウェアアクセラレータであるIntel Advanced Matrix Extensions (AMX)を導入しています。私たちはすでにいくつかのブログ記事でAMXの利点を実証しています:NLP Transformerのファインチューニング、NLP Transformerの推論、およびStable Diffusionモデルの推論。 この投稿では、Intel Sapphire Rapids CPUクラスター上でStable Diffusionモデルをファインチューニングする方法を紹介します。わずかな例の画像のみを必要とするテキスト反転という技術を使用します。たった5つの画像だけです! さあ、始めましょう。 クラスターのセットアップ Intelの友人たちが、最新のIntelプロセッサとパフォーマンス最適化されたソフトウェアスタックを使用したIntel®最適化デプロイメント環境でのワークロードの開発と実行を行うためのサービスプラットフォームであるIntel Developer Cloud(IDC)にホストされた4つのサーバーを提供してくれました。 各サーバーには、2つのIntel…

「完璧なPythonデータ可視化のためのAIプロンプトエンジニアリングの5つの習慣」
データの可視化はデータ分析の基盤であり、Pythonはこのタスクにおける選ばれたツールですChatGPTとのモジュラープロンプトエンジニアリングの使用能力により、一部のエントリー障壁が取り除かれました…

「50 ミッドジャーニーノーリングのヒント(フラットレイ写真)」
「Midjourneyを使用してノーリング(フラットレイ)の写真を作成できることを知っていましたか?ここには始めるための50のプロンプトがあります」
「LLMsの実践的な導入」
「これは、実践で Large Language Models (LLMs) を使用するシリーズの最初の記事ですここでは、LLMs の紹介とそれらとの作業の3つのレベルを紹介します将来の記事では...」

Jasper AI レビュー(2023年7月):最高のAIライティングジェネレーター?
「このJasper AIのレビューで最高のAIライティングジェネレーターを発見しましょう!このパワフルなツールで創造性と生産性を解き放ってください」
「OpenAI APIを使用して、大規模な言語モデルを用いた表データ予測の改善」
最近では、大規模な言語モデルやそのアプリケーションやツールがニュースやソーシャルメディアで話題になっていますGitHubのトレンディングページには、広範なリポジトリが大量に掲載されています...
「データの中で最も異常なセグメントを特定する」
「アナリストはしばしば、「興味深い」と思われるセグメントを見つけるというタスクがありますつまり、最大の潜在的な影響を得るために私たちの努力を集中させることができるセグメントです例えば、次のようなことを判断することは興味深いかもしれません...」
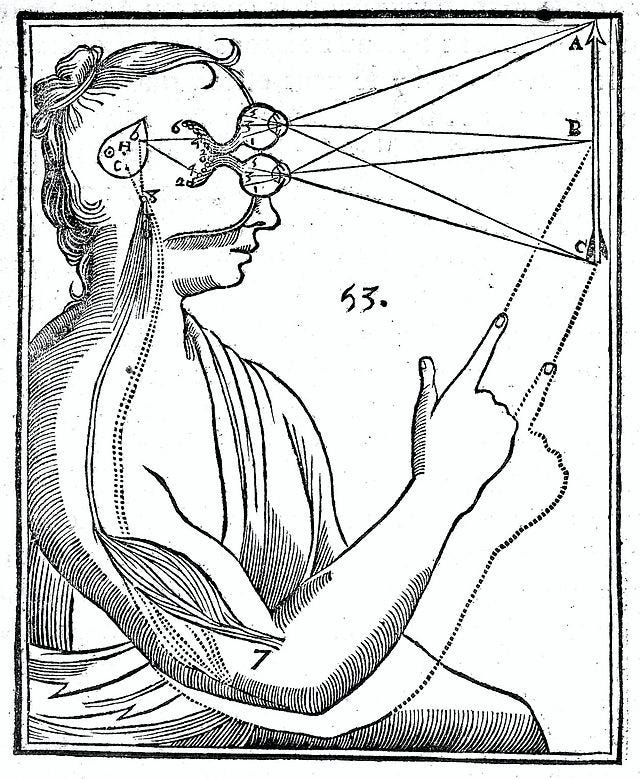
「先天性とは何か、そしてそれは人工知能にとって重要なのか?(パート1)」
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの概念とその応用についての二部構成の詳細な解説は、状況を明確にするのに役立つかもしれません...」

「私はChatGPTのコードインタプリタに乱雑なデータセットと望ましいクリーンなバージョンを示しました」
それでは、私は散らかったデータセットをきれいな形式に変換できる魔法のステッキが欲しいと思いますChatGPT Code Interpreterはその魔法のステッキです実際には、それはもっと良いですCode Interpreter...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.