Learn more about Search Results A - Page 688

- You may be interested
- 「生成AIはその環境への足跡に値するのか?」
- 初心者のための畳込みニューラルネットワーク
- 見逃せない7つの機械学習アルゴリズム
- 昇進しました! (Shōshin shimashita!)
- 「LLMのパラメータ効率的なファインチュー...
- 「DeepOntoに会ってください 深層学習を用...
- PROsに対する推論
- 研究者たちは、AIシステムを取り巻くガー...
- マイクロソフトリサーチとジョージア工科...
- 「言葉から世界へ:AIマルチモーダルによ...
- 「衛星画像のための基礎モデル」
- 「AIが絶滅の危機に瀕するピンクイルカの...
- イーロン・マスク氏とXAiチームがGrokを発...
- 人工知能の無料コース「”Train & Fine...
- 合成データは、機械学習のパフォーマンス...

2023年の練習のためのトップ18のPower BIプロジェクトアイデア
Power BIは、生データを情報豊かな視覚化とレポートに変換する影響力のあるツールです。使いやすいインターフェースと強力な機能を備えたPower BIは、実践的なプロジェクトを通じてスキルを磨くための貴重なプラットフォームです。Power BIのプロジェクトに取り組むことで、初心者からエキスパートまで、能力を大幅に向上させることができます。この記事では、2023年に実践するための主要な18のPower BIプロジェクトのアイデアを、さまざまな熟練レベルに合わせて紹介します。 なぜPower BIプロジェクトを解決するのか? Power BIのプロジェクトに取り組むことには、いくつかの利点があります。理論的な知識を実世界のシナリオに適用することで、実践的なスキルを向上させることができます。これらのプロジェクトは、データの視覚化、分析、レポート作成といった、重要なデータ分析とビジネスインテリジェンスのスキルを身に付けるための実践的な経験を提供します。さらに、Power BIのプロジェクトに取り組むことで、潜在的な雇用主に自身の能力をアピールするポートフォリオを構築することができます。さらに、生データから洞察に富んだ視覚化やレポートを作成することで、問題解決能力が向上し、Power BIツールの効果的な使用に対する自信が高まります。 以下は、トップ18のPower BIプロジェクトです: 売上データの視覚化 顧客セグメンテーション分析 在庫管理ダッシュボード 従業員のパフォーマンス指標 ウェブサイトのトラフィック分析 予測販売予測 顧客生涯価値分析 ソーシャルメディアの感情分析 マーケットバスケット分析 電子商取引の変換フレンネル エネルギー消費パターン…

「GPTモデルの信頼性に関する詳細な分析」
最近のグローバルな世論調査では、半数以上の回答者が、この新興技術を金融計画や医療ガイダンスなどの機密性の高い分野に利用すると回答しました。しかし、幻覚、ディスインフォメーション、バイアスなどの問題があるという懸念もあります。機械学習の最近の発展により、特に大規模言語モデル(LLMs)は、チャットボットや医療診断からロボットまで、さまざまな分野で利用されています。言語モデルの評価とその能力と限界をより良く理解するために、異なるベンチマークが開発されています。例えば、GLUEやSuperGLUEのような、全般的な言語理解を評価するための標準化されたテストが開発されています。 最近では、HELMが多様なユースケースと指標でLLMsの包括的なテストとして発表されました。LLMsがますます多くの分野で使用されるにつれて、その信頼性についての疑念が高まっています。既存のLLMの信頼性評価は、主に頑健性や過信などの要素に焦点を当てた狭義の評価です。 さらに、大規模言語モデルの能力の向上は、LLMsの信頼性の問題を悪化させる可能性があります。特に、GPT-3.5とGPT-4は、対話向けに最適化された特殊な最適化手法により、指示に従う能力が向上しています。これにより、ユーザーはトーンや役割などの適応や個別化の変数をカスタマイズすることができます。テキストの埋め込みにしか適していなかった古いモデルと比較して、改善された機能により、質問応答やディスカッション中の短いデモンストレーションを通じた文脈学習などの機能が追加されます。 GPTモデルの信頼性を徹底的に評価するために、一部の研究者グループは、さまざまなシナリオ、タスク、メトリック、データセットを用いて、8つの信頼性視点に絞り込み評価を行いました。グループの最も重要な目標は、GPTモデルの頑健性を困難な状況で測定し、さまざまな信頼性の文脈でのパフォーマンスを評価することです。このレビューでは、一貫性を確認し複製可能な結果を得るために、GPT-3.5とGPT-4モデルに焦点を当てています。 GPT-3.5とGPT-4について話しましょう GPT-3の後継であるGPT-3.5とGPT-4により、新しい形の相互作用が可能になりました。これらの最先端モデルは、スケーラビリティと効率性の向上、およびトレーニング手法の改善を経ています。 GPT-3.5やGPT-4のような事前学習済みの自己回帰(デコーダのみ)トランスフォーマーは、先行モデルと同様に、左から右にトークンごとにテキストトークンを生成し、それらのトークンに対して行った予測をフィードバックします。GPT-3に比べて改善されたものの、GPT-3.5のモデルパラメータの数は1750億のままです。GPT-4のパラメータセットの正確なサイズや事前トレーニングコーパスの詳細は不明ですが、GPT-3.5よりも大きな財務投資がトレーニングに必要です。 GPT-3.5とGPT-4は、次のトークンの確率を最大化するために従来の自己回帰事前トレーニング損失を使用します。さらに、LLMsが指示に従い、人間の理想と一致する結果を生成することを確認するために、GPT-3.5とGPT-4は人間のフィードバックからの強化学習を使用します。 これらのモデルは、OpenAI APIクエリングシステムを使用してアクセスすることができます。APIコールを介して温度や最大トークンを調整することで、出力を制御することが可能です。科学者たちはまた、これらのモデルが静的ではなく変化することを指摘しています。実験では、安定したバリアントのモデルを使用して信頼性の結果を保証しています。 毒性、ステレオタイプに対するバイアス、敵対的攻撃に対する頑健性、OODインスタンスに対する頑健性、敵対的なデモンストレーションに対する頑健性、プライバシー、倫理、公平性の観点から、研究者はGPT-4とGPT-3.5の信頼性に関する詳細な評価を行っています。一般的に、GPT-4は全般的にGPT-3.5よりも優れた性能を示しています。ただし、GPT-4は指示により忠実に従うため、操作が容易になる可能性があり、ジェイルブレイキングや誤解を招く(敵対的な)システムのプロンプトやデモンストレーションに対して新しいセキュリティ上の懸念が生じます。さらに、これらの例は、モデルの信頼性に影響を与えるさまざまな特性や入力のプロパティがあることを示しており、追加の調査が必要です。 これらの評価に基づいて、GPTモデルを使用してLLMsを保護するために、次の研究の方向性が検討される可能性があります。より多くの共同評価。GPTモデルのさまざまな信頼性の視点を検討するために、1-2回のディスカッションなどの静的なデータセットを主に使用しています。巨大な言語モデルが進化するにつれ、これらの脆弱性がより深刻になるかどうかを判断するために、対話型ディスカッションでLLMsを調査することが重要です。 文脈による学習の誤認は、偽のデモンストレーションやシステムプロンプト以外にも大きな問題です。これらは、モデルの弱点をテストし、最悪のケースでのパフォーマンスを把握するために、さまざまなジェイルブレイキングシステムプロンプトや偽(敵対的な)デモを提供します。対話に偽の情報を意図的に注入することで、モデルの出力を操作することができます(いわゆる「ハニーポット会話」)。さまざまなバイアスの形式に対するモデルの感受性を観察することは魅力的です。 関連する敵を考慮した評価。ほとんどの研究は、各シナリオで1つの敵のみを考慮に入れていますが、実際には、経済的なインセンティブが十分にあれば、様々なライバルが結託してモデルを騙すことが可能です。そのため、協調的かつ秘密裏な敵対的行動に対するモデルの潜在的な感受性を調査することは重要です。 特定の設定での信頼性の評価。感情分類やNLIタスクなどの標準的なタスクは、ここで提示された評価においてGPTモデルの一般的な脆弱性を示しています。法律や教育などの分野でGPTモデルが広く使用されていることを考慮して、これら特定のアプリケーションにおける弱点を評価することは重要です。 GPTモデルの信頼性を確認する。LLMの経験的な評価は重要ですが、特に安全性の重要なセクターでは、保証が欠けることがしばしばあります。さらに、その不連続な構造により、GPTモデルの厳密な検証が困難になります。具体的な機能に基づいた保証と検証を提供したり、モデルの抽象化に基づいた検証を提供したり、ディスクリートな空間を対応する連続的な空間(意味の保持を持つ埋め込み空間など)にマッピングして検証を行うなど、難しい問題をより管理しやすいサブ問題に分割することができます。 GPTモデルを保護するための追加情報と推論分析の組み込み。統計のみに基づいているGPTモデルは改善する必要があり、複雑な問題を論理的に推論することはできません。モデルの結果の信頼性を保証するために、ドメイン知識と論理的推論の能力を言語モデルに提供し、基本的なドメイン知識や論理を満たすように結果を保護することが必要かもしれません。 ゲーム理論に基づいたGPTモデルの安全性を確保する。作成時に使用される「役割プレイ」のシステムプロンプトは、モデルが役割を切り替えたり操作したりするだけで簡単に騙されることを示しています。これは、GPTモデルの対話中にさまざまな役割を作り出して、モデルの応答の一貫性を保証し、モデルが自己矛盾に陥ることを防ぐためのものです。特定のタスクを割り当てて、モデルが状況を徹底的に理解し、信頼性のある結果を提供することが可能です。 特定のガイドラインと条件に基づいてGPTのバージョンをテストする。モデルは一般的な適用性に基づいて評価されますが、ユーザーにはセキュリティや信頼性のニーズがあり、それを考慮する必要があります。したがって、ユーザーのニーズや指示を特定の論理空間や設計コンテキストにマッピングし、出力がこれらの基準を満たしているかどうかを評価することは、モデルの監査をより効率的かつ効果的に行うために不可欠です。

物体検出評価指標の概要
オブジェクト検出器の性能を評価する際には、主に2つの評価指標を使用しますネットワークの検出速度を測るためにFPS(1秒間のフレーム数)を使用し、平均平均精度(mAP)を測るために使用します...
「対数正規分布の簡単な説明」
正規分布は、特にデータサイエンスや機械学習の分野でよく知られていますしかし、ログ正規分布について聞いたことはありますか?これは幅広い応用があります...

線形代数の鳥瞰図:基礎
線形代数は数学でできるすべてのことの基礎的な学問です物理学から機械学習、確率論(例:マルコフ連鎖)まで、何でもあります何をやっているかに関係なく、…
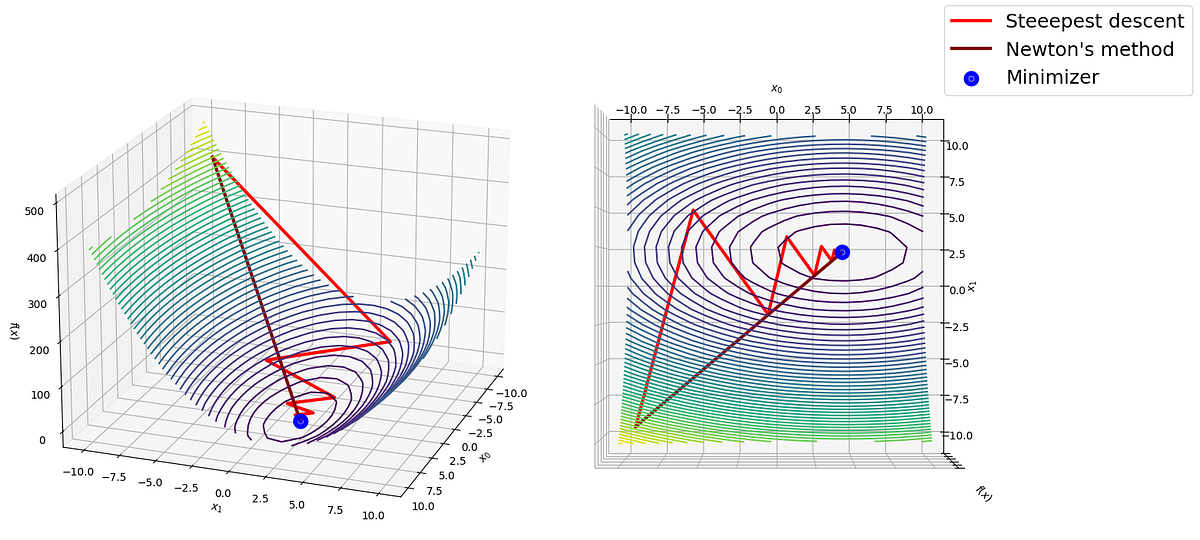
「スクラッチからのPythonにおける最急降下法とニュートン法:比較」
前回の投稿では、最適化のための人気のある最急降下法を探求し、Pythonでゼロから実装しましたこの記事では、ニュートン法を紹介し、...

ツールの使用方法を言語モデルに教える
私たちが彼らについてもっと学ぶにつれて、大規模言語モデル(LLM)はますます興味深くなりますこれらのモデルは、さまざまな複雑なタスクを正確に解決することができますしかし、同時に、彼らは...と苦労しています
「生データから洗練されたデータへ:データの前処理の旅 — パート3:重複データ」
データ内の重複した値の存在は、多くのプログラマーによってしばしば無視されますしかし、データ内の重複したレコードに対処することは非常に重要です例えば、置き換えるとどうなるかなど、重複したレコードの扱いは重要です

銀行の苦情に関する架空のデータ
この記事は、架空の顧客クレームを模倣した新しい架空のデータセットを紹介しています一般的な消費者銀行で顧客サービスマネージャーとして働いていると想像してください
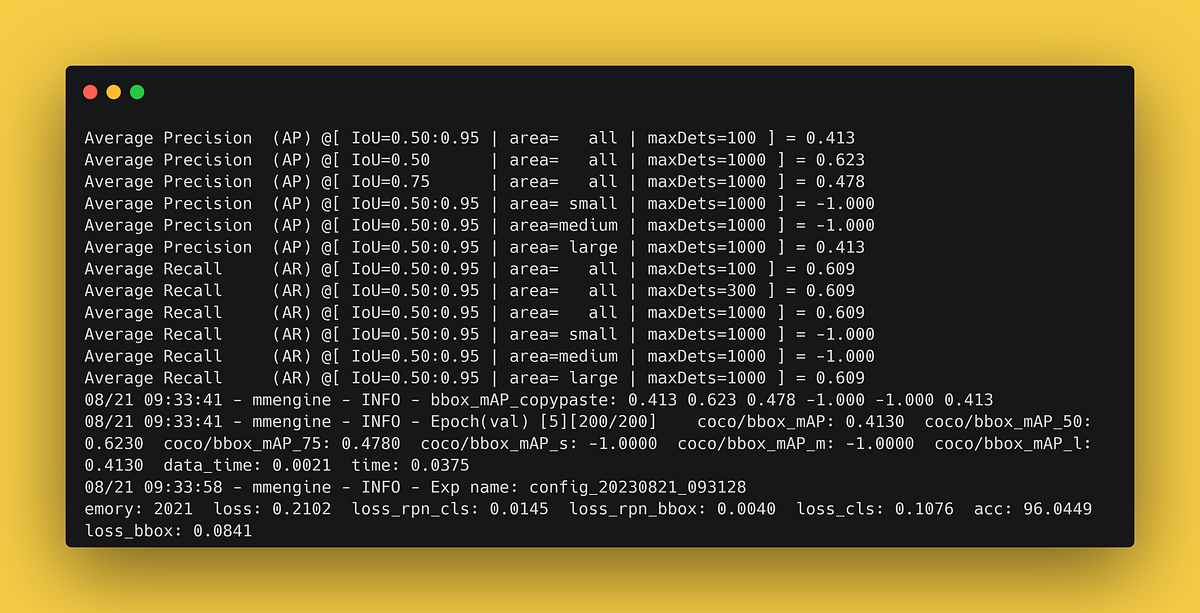
「MMDetectionを使用して物体検出モデルのトレーニング方法を学びましょう」
MMDetection 3を使用してディープラーニングモデルをトレーニングし、CVATで画像にラベルを付け、TensorBoardでトレーニングを監視する方法についてのステップバイステップチュートリアル
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.