Learn more about Search Results A - Page 685

- You may be interested
- 「人工知能による在庫管理の革命:包括的...
- StackOverflowの転機:破壊から機会への転換
- 大規模言語モデルにおける推論力の向上:...
- print()の使用をやめる
- 『BOSSと出会ってください:新しい環境で...
- 「AIとの会話の仕方」 翻訳結果は:
- コンピュータ芸術の先駆者、ヴェラ・モル...
- コンピュータ科学の研究者たちは、モジュ...
- 「HeyGenレビュー:ビジネス向けの最高のA...
- 『RAPとLLM Reasonersに会いましょう:LLM...
- 「17/7から23/7までのトップコンピュータ...
- パーセプトロンからアダラインまで –...
- 「マーケティングにおける人工知能の短い...
- ライトオンAIは、Falcon-40Bをベースにし...
- 「Javaアプリケーションのレイテンシー削減」

「季節変動をマスターし、ビジネス結果を向上させる究極のガイド」
この投稿では、メディアミックスモデリングの重要性と、広告のビジネスへの影響を最大化するための活用方法について説明しますまた、季節性がメディア広告に与える影響と、メディアミックスモデリングがビジネスの結果に与える季節性の影響を最小限に抑えるためにどのように活用できるかについても議論します

MSSQL vs MySQL データベースのパワーハウスを比較する
イントロダクション データベース管理システムの賑やかな競技場には、2つの重量級のライバルが現れます。1つはエンタープライズレベルの優れた能力を持つ洗練されたMicrosoft SQL Server (MSSQL)で、もう1つはコミュニティ主導の柔軟性を備えた開放的なMySQLです。それでは、MSSQLとMySQLが提供する機能を比較し、どちらがより適しているか見てみましょう。 MSSQL vs MySQL – 概要 要素 Microsoft SQL Server (MSSQL) MySQL ライセンス プロプライエタリでさまざまなエディションとライセンス オープンソースでコミュニティおよびエンタープライズエディション パフォーマンス 大企業と複雑なクエリに最適化されています 小規模から中規模のアプリケーションに適しています スケーラビリティ 堅牢なスケーラビリティオプションとクラスタリングサポート…

効果的なコーディングルーティンを開発するための5つの重要なステップ
コーディングの習慣を築くのに苦労していますか?そんな方に、モチベーションを高め、コーディングの道程に実際に影響を与える心理学的な洞察を共有します

ウィスコンシン大学マディソン校の研究者たちは、「エベントフルトランスフォーマー:最小限の精度損失でコスト効果のあるビデオ認識手法」というタイトルで、イベントフルトランスフォーマーに基づくビデオ認識の費用対効果の高い手法を提案しています
最近、言語モデリングを目的としたTransformerは、ビジョン関連のタスクのアーキテクチャとしても研究されています。オブジェクトの識別、画像の分類、ビデオの分類などのアプリケーションにおいて最先端のパフォーマンスを発揮し、さまざまな視覚認識の問題において優れた精度を示しています。ビジョンTransformerの主な欠点の1つは、高い処理コストです。ビジョンTransformerは、通常の畳み込みニューラルネットワーク(CNN)に比べて、数百GFlopsの処理が1枚の画像に対して必要となることもあります。ビデオ処理にかかるデータ量の多さは、これらの費用をさらに増加させます。この興味深い技術の潜在能力は、リソースが少ないデバイスや低遅延が必要なデバイスで使用することを妨げる高い計算要件によって制約されています。 ビデオデータと一緒に使用する場合、ビジョンTransformerのコストを削減するために、連続する入力間の時間的冗長性を活用する最初の手法の1つが、ウィスコンシン大学マディソン校の研究者によって提案されました。フレームごとまたはクリップごとにビデオシーケンスに適用されるビジョンTransformerを考えてみてください。このTransformerは、フレームごとのモデル(オブジェクト検出など)や時空間モデルの過渡的なステージ(初期の因子分解モデルなど)のようなものかもしれません。彼らは、時間を超えて複数の異なる入力(フレームまたはクリップ)にTransformerが適用されると考えています。これは、言語処理とは異なり、1つのTransformer入力が完全なシーケンスを表すものです。自然な動画は高い程度の時間的冗長性を持ち、フレーム間の変動が少ない傾向があります。しかし、これにもかかわらず、このような状況でも、Transformerなどの深層ネットワークは各フレームで頻繁に「ゼロから」計算されます。 この方法は効率的ではありません。なぜなら、それによって以前の結論からの潜在的に有用なデータが捨てられてしまうからです。彼らの主な洞察は、以前のタイムステップの中間計算を再利用することで冗長なシーケンスをより良く活用できるということです。知的推論。ビジョンTransformer(および深層ネットワーク全般)の推論コストは、設計によって決まることがよくあります。ただし、実際のアプリケーションでは、利用可能なリソースは時間とともに変化する可能性があります(たとえば、競合するプロセスや電源の変更など)。そのため、計算コストをリアルタイムに変更できるモデルが必要です。本研究では、適応性が主な設計目標の1つであり、計算コストに対してリアルタイムの制御を提供するためにアプローチが作成されています。映画の中で計算予算をどのように変更するかの例については、図1(下部)を参照してください。 図1:この戦略は、連続するモデル入力間の時間的なオーバーラップを利用しています。(上)各Transformerブロック内で、時間の経過に伴って大幅な変更が加えられたトークンのみを検出および更新します。 (下)このソリューションは、効率性を向上させるだけでなく、実行時に計算コストを細かく制御することも可能です。 以前の研究では、CNNの時間的冗長性と適応性に関して調査されてきました。しかし、TransformerとCNNの間には重要なアーキテクチャの違いがあるため、これらのアプローチは通常、Transformerのビジョンには互換性がありません。特に、Transformerは複数のCNNベースの手法から逸脱した、新しい基本的な手法である自己注意を導入しています。しかし、このような障害にもかかわらず、ビジョンTransformerには大きな可能性があります。特に、時空間的な冗長性を考慮に入れることで獲得されるCNNのスパース性を実際の高速化に転送することは難しいです。これを行うには、スパース構造に大きな制約を課すか、特別な計算カーネルを使用する必要があります。一方、トークンベクトルの操作に焦点を当てたTransformerの性質により、スパース性をより短い実行時間に転送することはより簡単です。イベントを持つTransformer。 効果的で適応性のある推論を可能にするために、彼らはイベントフルTransformerという新しいタイプのTransformerを提案しています。イベントフルという言葉は、シーンの変化に応じて疎な出力を生成するセンサーであるイベントカメラを指すために作られました。イベントフルTransformerは、時間の経過に伴うトークンレベルの変化を追跡するために、各タイムステップでトークンの表現と自己注意マップを選択的に更新します。ゲーティングモジュールは、更新されるトークンの量をランタイムで制御するためのイベントフルTransformerのブロックです。彼らのアプローチは、さまざまなビデオ処理アプリケーションと共に動作し、再トレーニングなしで既存のモデルに使用することができます。彼らの研究は、最先端のモデルから作成されたイベントフルTransformerが、計算コストを大幅に削減しながら元のモデルの精度をほぼ保持することを示しています。 彼らのソースコードは、イベントフルトランスフォーマーを作成するためのPyTorchモジュールが公開されています。Wisionlabのプロジェクトページは、wisionlab.com/project/eventful-transformersにあります。CPUとGPUでは、壁時計の速度向上が示されています。彼らのアプローチは、標準的なPyTorchオペレータに基づいているため、技術的な観点からは最適とは言えないかもしれません。彼らは、オーバーヘッドを減らすための作業(ゲーティングロジックのための融合CUDAカーネルの構築など)を行うことで、速度向上比率がさらに高まる可能性があると確信しています。さらに、彼らのアプローチには、ある程度避けられないメモリオーバーヘッドが生じます。当然のことながら、一部のテンソルをメモリ上に保持することは、以前の時間ステップからの計算の再利用に必要です。 論文をチェックしてください。この研究に関する全てのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュースや素敵なAIプロジェクトなどを共有している2.9万人以上のML SubReddit、4万人以上のFacebookコミュニティ、Discordチャンネル、およびメールニュースレターにも参加するのを忘れないでください。 私たちの活動が気に入ったなら、ニュースレターも気に入るはずです。 この投稿は、「ミニマルな精度損失を伴うコスト効果的なビデオ認識手法であるイベントフルトランスフォーマーについて、ウィスコンシン大学マディソン校の研究者が提案しました」という記事です。 (翻訳元:MarkTechPost)

LLM Fine-Tuningの初心者ガイド
この記事では、効率的な技術とクラウドベースのGPUサービスを使用して、(Code) Llamaモデルの微調整方法を示します
「LLMガイド、パート1:BERT」 LLMガイド、パート1:BERTについてのガイドです
2017年は、Transformerモデルが初めて登場した機械学習の歴史的な年でした多くのベンチマークで驚くべきパフォーマンスを発揮し、さまざまな用途に適しているようです...

「LLMはナレッジグラフを取って代わるのか? メタリサーチャーが提案する『ヘッド・トゥ・テイル』:大規模言語モデルの事実知識を測るための新たな基準」
大規模言語モデルは、その超すばらしい能力によって多くの評価を集めています。彼らは人間を模倣し、人間のようにコンテンツを生成することができます。ChatGPTやLLaMAなどの事前学習済みの大規模言語モデル(LLM)は、素晴らしい能力を持っており、素材を理解し、頻繁なクエリに応答することができます。いくつかの研究では、彼らは知識を内面化し、問い合わせに応答する能力を示しています。しかし、LLMは大きく進化しているものの、特定のドメインの微妙なニュアンスを高度に理解することができず、幻覚として誤った情報を生成する傾向があります。これは、LLMの正確性を向上させ、幻覚的な応答の発生率を減らすための重要な障害を示しています。 LLMに関連する議論は、主に以下の3つの主要な領域に焦点を当てています。それは、LLMが生成した応答の幻覚を減らすこと、LLMの事実的な正確性を向上させること、そしてLLMが世界の知識を象徴的な形式で記憶する手段として知識グラフ(KG)をいずれ置き換える可能性についての推測です。最近、Meta Reality Labsの研究チームは、これらの問いに答える新しいアプローチを取り、LLMが実際にどれだけの情報を持っているかを判断しようと試みました。 知識に関してLLMがどれだけ精通しているかという問いには、2つの側面があります。まず第一に、LLM内に含まれる知識を直接的に問いかけることは困難かもしれません。モデルのパラメータに既に組み込まれている知識であっても、知識の不足や生成モデルの誤作動によって幻覚が引き起こされる可能性があります。この研究では、LLMの中に含まれる知識の程度をある基準として正確さを使用することを提案しています。これは、「バスケットボール選手のマイケル・ジョーダンはどこで生まれましたか?」のような明確で正確な質問に対するモデルの回答能力を評価するものです。LLMには簡潔な回答を提供するように求められ、自信が低い場合には「unsure」という言葉を使用して不確実性を認めるようにします。 第二に、ユーザーの関心の多様性や世界の情報の広がりを正確に反映する利用可能なベンチマークは存在しません。最も包括的な知識グラフでも、知識のギャップが存在し、特にあまり知られていない事実に関しては顕著です。LLMや検索エンジンのクエリログは一般に利用できません。 これらの制限に対処するために、チームは「Head-to-Tail」というベンチマークを作成しました。このベンチマークは、人気のある主題に基づいてヘッド、トルソー、テールの事実に分けられた18,000の質問と回答(QA)のセットで構成されています。これらのカテゴリには異なる一般的な認知レベルが反映されています。チームは、LLMが適切に吸収した知識の幅を密接に反映する評価方法と一連の尺度を作成し、LLMが保持する知識を評価するために使用しています。 研究の中心は、一般の人々に利用可能な14のLLMの評価です。その結果、既存のLLMは事実データの理解を完全に習得する点でまだ大幅な改善が必要であることが示されました。特に、トルソーからテールの領域に含まれる、あまり知られていない組織に関する情報については、これが当てはまります。 結論として、この研究は最近提案されたベンチマークと最新の評価技術を使用してLLMの事実的な知識を検証しています。この研究は、重要な研究課題を扱い、具体的な結果を示すことにより、大規模言語モデルが事実情報を組み込む上での信頼性と将来の進展に関する継続的な議論に重要な貢献をしています。
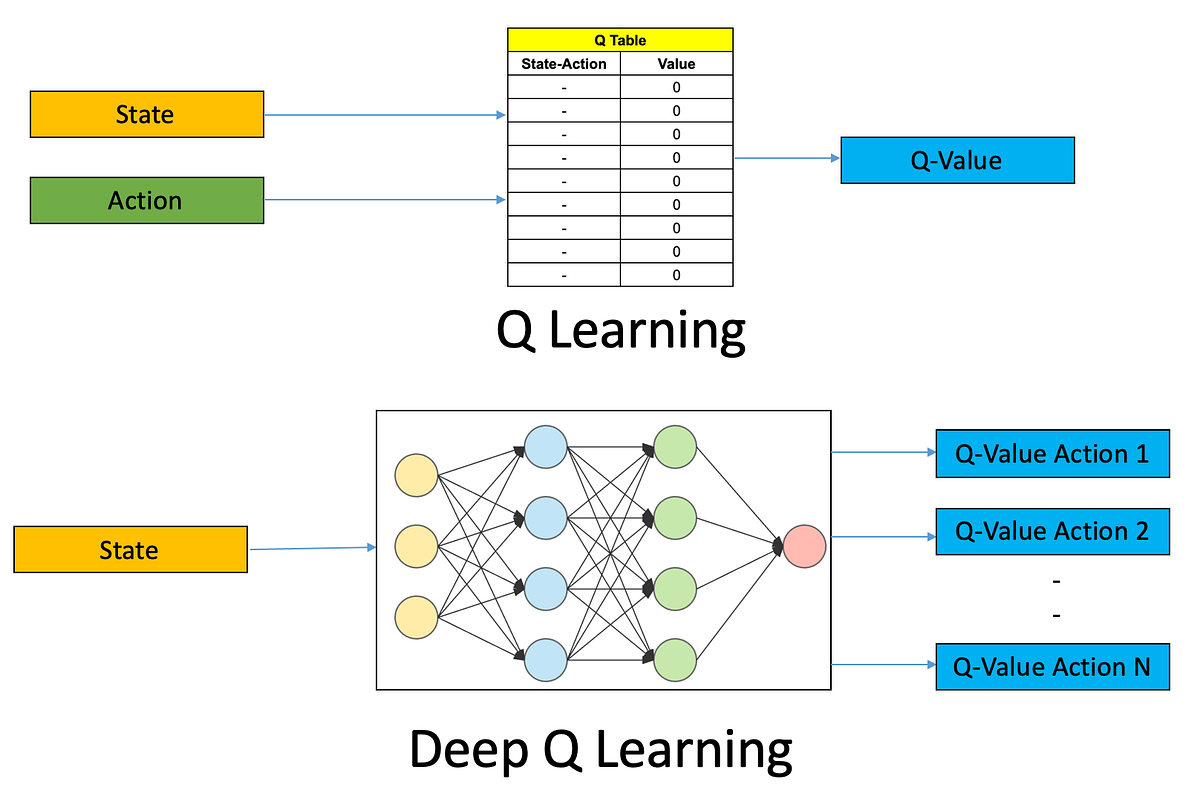
初めてのDeep Q学習ベースの強化学習エージェントをトレーニングする:ステップバイステップガイド
強化学習(RL)は、人工知能(AI)の魅力的な領域であり、機械が環境との相互作用を通じて学習し、意思決定を行うことができるようにしますRLエージェントを訓練する...

アリババの研究者は、Qwen-VLシリーズを紹介しますこれは、テキストと画像の両方を認識し理解するために設計された大規模なビジョン・ランゲージ・モデルのセットです
最近、大規模言語モデル(LLM)は、強力なテキスト生成能力と理解能力を持つため、多くの関心を集めています。これらのモデルは相互作用能力があり、ユーザーの意図に合わせて指示をより一層的確にすることで、知的なアシスタントとして生産性を向上させる潜在的な能力を持っています。一方、ネイティブの大規模言語モデルは純粋なテキストの領域に限定されており、画像や音声、動画などの他の広く使用されるモダリティを扱うことができません。そのため、これらのモデルの応用範囲が制限されています。この制約を克服するために、大規模ビジョン言語モデル(LVLM)の系列が作成されました。 これらの広範なビジョン言語モデルは、実用的なビジョン中心の問題を解決するための大きな可能性を示しています。アリババグループの研究者たちは、オープンソースのQwenシリーズの最新メンバーであるQwen-VLシリーズモデルを紹介し、マルチモーダルなオープンソースコミュニティの成長を促進しています。Qwen-VLファミリーの大規模なビジョン言語モデルには、Qwen-VLとQwen-VL-Chatの2つのバリエーションがあります。事前学習済みモデルであるQwen-VLは、ビジュアルエンコーダをQwen-7B言語モデルに接続して、ビジュアルの能力を提供します。Qwen-VLは、訓練の3つの段階を経た後、マルチレベルのスケールでビジュアル情報を感知し、理解することができます。また、Qwen-VL-Chatは、Qwen-VLを基にした対話型のビジュアル言語モデルであり、アライメント手法を使用し、複数の画像入力、マルチラウンドのディスカッション、位置情報の能力など、より柔軟な対話を提供します。これは図1に示されています。 図1: Qwen-VL-Chatによって生成されたいくつかの定性的なサンプルが図1に示されています。複数の画像入力、ラウンドロビンの会話、多言語の会話、および位置情報の機能をQwen-VL-Chatはサポートしています。 以下は、Qwen-VL-Chatの特徴です。 ・高い性能:ゼロショットキャプショニング、VQA、DocVQA、およびグラウンディングなど、いくつかの評価ベンチマークで、現在のオープンソースの大規模ビジョン言語モデル(LVLM)を大幅に上回る性能を発揮します。 ・多言語LVLMによる中国語と英語のバイリンガルテキストと画像内のインスタンスのエンドツーエンド認識とアンカリングの促進:Qwen-VLは自然な形で英語、中国語、およびマルチリンガルな対話が可能です。 ・複数の画像の交互に挿入された会話:この機能により、複数の画像を比較し、画像に関する質問を指定し、複数の画像で物語を作成することができます。 ・正確な認識と理解:448×448の解像度により、細かいテキストの認識、ドキュメントの品質保証、バウンディングボックスの識別が、競合するオープンソースのLVLMが現在使用している224×224の解像度と比較して促進されます。
ビッグデータのための階層的クラスタリングのスケーリング
凝集型クラスタリングは、データサイエンスで最も優れたクラスタリングツールの一つですが、従来の実装は大規模なデータセットに対してスケーリングできませんこの記事では、背景について説明します...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.