Learn more about Search Results リポジトリ - Page 67

- You may be interested
- 初期段階の企業や初めての創業者が経済的...
- 「マイクロソフトが、自社の新しい人工知...
- カルテックとETHチューリッヒの研究者が画...
- 「知っておくべき3つの一般的な時系列モデ...
- 「依存関係の解明と因果推論および因果検...
- 「ChatGPTにおける適切なプロンプト設計の...
- 「データ駆動型ストーリーテリングにおけ...
- 「機械学習が間違いを comitte たとき、そ...
- 「APIガバナンスによるAIインフラストラク...
- 「なんでもセグメント:任意のオブジェク...
- 「エンティティ抽出、SQLクエリ、およびAm...
- デザインスピードがリードを取る:Trek Bi...
- CMUの研究者たちは、視覚的な先行知識をロ...
- 「多言語AIは本当に安全なのか?低リソー...
- 「xTuringに会ってください:たった3行の...
「OpenAI(Python)APIを解説する」
「これは、実践において大規模な言語モデル(LLM)を使用するシリーズの2番目の記事ですここでは、OpenAI APIの初心者向けの紹介を行いますこれにより、制約のあるチャットを超えることができます...」
1時間以内に初めてのディープラーニングアプリを作成しましょう
私はもう10年近くデータ分析をしています時折、データから洞察を得るために機械学習の技術を使用しており、クラシックな機械学習を使うことにも慣れています

「Flowise AI:LLMフローを構築するためのドラッグアンドドロップUI」
プログラミングの経験がない?心配しないでください自分自身のカスタマイズされたLLMフローを作成するのに役立つドラッグアンドドロップツールをチェックしてくださいしかも、テックのプロである必要はありません!
類似検索、パート6:LSHフォレストによるランダム射影
「類似検索」とは、クエリが与えられた場合に、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目指す問題ですデータサイエンスにおいては、類似検索はしばしばNLP(自然言語処理)で現れます...

Google AIがSimPerを導入:データ内の周期情報を学習するための自己教示対照フレームワーク
近年、周期的なデータの認識と理解は、気象パターンのモニタリングから医療設定での重要なバイタルサインの検出まで、さまざまな現実世界のアプリケーションにおいて重要となっています。周期学習は、環境遠隔センシングなどの分野で不可欠な役割を果たしており、天気の変化や地表温度の変動の正確な現在予測を可能にしています。同様に、医療分野では、ビデオ測定からの周期学習は、心房細動や睡眠時無呼吸のエピソードなどの重要な医療状態の特定において有望な結果を示しています。 周期学習の力を利用するための取り組みは、単一のビデオ内の繰り返し活動を特定できるRepNetなどの教師ありアプローチの開発につながりました。しかし、これらの方法は大量のラベル付きデータを必要とするため、リソースが多くかつ困難です。この制約は、SimCLRやMoCo v2などの教師なし学習(SSL)手法を活用して大量のラベルなしデータを利用し、データの周期的または準周期的な時間動態を捉えるという研究者の試みを促しました。これらの手法は分類タスクの解決に成功していますが、データに存在する固有の周期性を完全に理解し、周期的または周波数属性に対して堅牢な表現を作成することには苦労しています。 これらの課題に対処するために、Googleの研究者はSimPerを紹介し、データ内の周期情報を学習するために特に設計された革新的な自己教師対比フレームワークを提案しています。このフレームワークは、周期性に対して不変な変換と周期性に対して変化する変換の同じ入力インスタンスから派生した正例と負例を使用して、周期性の時間特性を活用して学習を行います。 周期学習の文脈での類似性の測定を明示的に定義するために、SimPerは独自の周期特徴類似性構築を提案しています。この定式化により、ラベル付きデータなしでモデルのトレーニングが可能になり、学習された特徴を特定の周波数値にマッピングするための微調整も可能になります。研究者は、オリジナルの周波数が不明であっても、ラベルのない入力に対して擬似的な速度または周波数ラベルを考案し、SimPerを現実世界のさまざまなアプリケーションに対して非常に汎用性の高いものにしました。 コサイン類似度などの従来の類似性尺度は、特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴、逆転した特徴、および周波数が変化した特徴に対して感度が高くなります。しかし、周期的な特徴類似性は、特徴の周波数が異なる場合でも、わずかな時間シフトや逆転したインデックスを持つサンプルに対して高い類似性を維持し、特徴の周波数が変化するときの連続的な類似性の変化を捉えることに重点を置いています。これは、2つのフーリエ変換間の距離など、周波数領域での類似性尺度によって実現されます。 さらに、フレームワークの性能を向上させるために、研究者は一般化された対比損失を設計し、クラシックなInfoNCE損失をソフト回帰バリアントに拡張しました。これにより、連続的なラベル(周波数)に対する対比が可能になり、SimPerは心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerの評価では、人間の行動分析、環境遠隔センシング、および医療のさまざまな現実世界のタスクをカバーする6つの異なる周期学習データセットにおいて、SimCLR、MoCo v2、BYOL、CVRLなどの最新のSSL手法と比較して優れた性能を発揮しました。SimPerは既存の手法を上回り、驚異的なデータ効率性、偽の相関への堅牢性、および未知のターゲットへの汎用性を示しました。 周期信号の強力な特徴表現を効率的かつ柔軟に学習するSimPerは、環境遠隔センシングから医療まで、さまざまな分野で有望な応用が期待されます。ラベル付きデータを大量に必要とせずに周期的なパターンを正確に捉える能力は、さまざまなドメインでの複雑な課題に対処するための魅力的な解決策となります。 結論として、SimPerの自己教師対比フレームワークは、周期学習の重要な課題に対する画期的な解決策を提供しています。SimPerは、時間的な自己教師対比学習を活用し、革新的な周期特徴類似性および一般化された対比損失を導入することにより、現実世界での効率的で正確かつ堅牢な周期学習アプリケーションの道を開拓しています。SimPerのコードリポジトリが研究コミュニティに提供されるにつれて、さらなる進展とさまざまなドメインでの応用範囲の拡大が期待されます。

「Amazon SageMakerを使用して、効率的にカスタムアンサンブルをトレーニング、チューニング、デプロイする」
「人工知能(AI)は、テクノロジーコミュニティで重要かつ人気のあるトピックとなっていますAIが進化するにつれて、さまざまなタイプの機械学習(ML)モデルが登場してきましたアンサンブルモデリングとして知られるアプローチは、データサイエンティストや実践者の間で急速に注目を集めていますこの記事では、アンサンブルモデルとは何かについて議論します...」
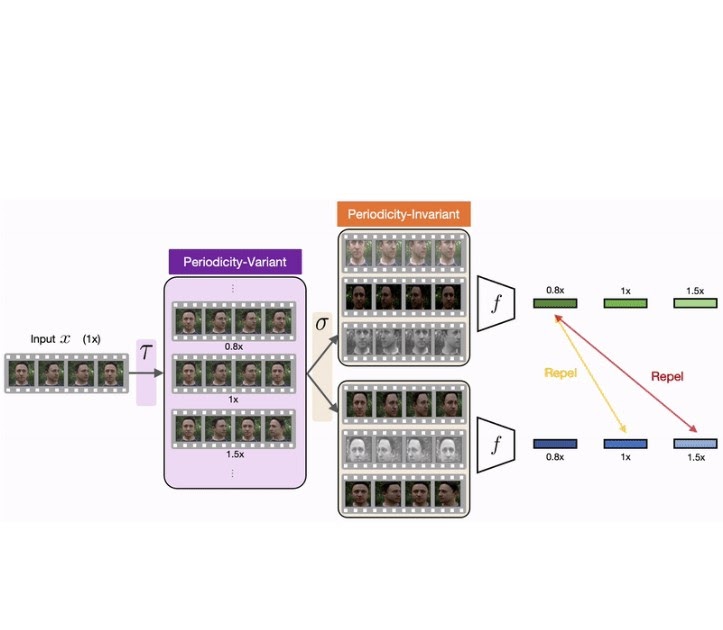
SimPer:周期的なターゲットの簡単な自己教示学習
Googleのスタッフ研究者であるDaniel McDuffと学生研究者のYuzhe Yangによって投稿されました。 周期的なデータ(心拍や地球表面の日々の気温変化など、繰り返される信号)から学ぶことは、天候システムの監視から生体徴候の検出まで、多くの実世界のアプリケーションにとって重要です。例えば、環境遠隔検出の領域では、降水パターンや地表温度などの環境変化のナウキャスティングを可能にするために周期的な学習がしばしば必要です。健康領域では、ビデオ測定から学んだ結果、心房細動や睡眠時無呼吸などの(準)周期的な生体徴候を抽出することが示されています。 RepNetなどのアプローチは、これらのタスクの重要性を強調し、単一のビデオ内で繰り返されるアクティビティを認識する解決策を提供しています。ただし、これらは教師ありのアプローチであり、繰り返されるアクティビティを捉えるために大量のデータと、アクションが繰り返された回数を示すラベルが必要です。このようなデータのラベリングは、しばしば難しくリソースを消費するため、研究者は興味の対象のモダリティ(ビデオや衛星画像など)と同期したゴールドスタンダードの時間的計測を手動でキャプチャする必要があります。 代わりに、自己教師あり学習(SSL)の手法(SimCLRやMoCo v2など)は、周期的または準周期的な時間的ダイナミクスを捉える表現を学習するためにラベルの付いていない大量のデータを活用することで、分類タスクの解決に成功しています。しかし、これらの手法は、データの固有の周期性(つまり、フレームが周期的なプロセスの一部であるかどうかを識別する能力)を見落とし、周期的な属性や周波数属性を捉える堅牢な表現を学習することができません。これは、周期的な学習が一般的な学習タスクとは異なる特性を持つためです。 周期的表現の文脈での特徴の類似性は、静的な特徴(例えば画像)とは異なります。例えば、短い時間遅れでオフセットされたビデオや反転されたビデオは、元のサンプルと類似しているべきです。一方、ビデオのアップサンプリングやダウンサンプリングは、元のサンプルから因子xで異なるはずです。 これらの課題に対処するために、私たちは「SimPer: Simple Self-Supervised Learning of Periodic Targets」という論文で、データ内の周期的な情報を学習するための自己教師ありの対照的なフレームワークを紹介しました。具体的には、SimPerは周期性不変および周期性変動の拡張によって、同じ入力インスタンスから正例と負例のサンプルを取得することで、周期性のあるターゲットの時間的特性を活用します。周期的な特徴の類似性を提案し、周期的な学習の文脈で類似性を測定する方法を明示的に定義します。さらに、古典的なInfoNCE損失をソフト回帰バリアントに拡張した汎用の対照的な損失を設計し、連続したラベル(周波数)を対照することを可能にします。次に、SimPerが最新のSSL手法と比較して効果的に周期的な特徴表現を学習することを示し、データの効率性、誤った相関に対する堅牢性、分布のシフトに対する一般化能力など、その興味深い特性を強調します。最後に、私たちはSimPerのコードリポジトリを研究コミュニティと共有することを楽しみにしています。 SimPerフレームワーク SimPerは、時間的な自己対照的学習フレームワークを導入します。正例と負例のサンプルは、周期性不変および周期性変動の拡張によって同じ入力インスタンスから取得されます。時間的なビデオの例では、周期性不変の変更にはトリミング、回転、反転があり、周期性変動の変更にはビデオの速度の増減が含まれます。 周期的な学習の文脈で類似性を測定する方法を明示的に定義するために、SimPerは周期的な特徴の類似性を提案します。この構成により、トレーニングを対照的な学習タスクとして定式化することができます。モデルはラベルのないデータでトレーニングされ、必要に応じて学習された特徴を特定の周波数値にマッピングするために微調整されることができます。 入力シーケンスxが与えられた場合、関連する周期的な信号が存在することがわかります。そして、xを変換して速度や周波数が変化したサンプルのシリーズを作成し、基になる周期的なターゲットを変更し、異なる負のビューを作成します。元の周波数は不明ですが、ラベルのない入力xに対して擬似的な速度や周波数のラベルを効果的に考案します。 従来の類似性尺度(例:コサイン類似度)は、2つの特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴(異なるタイムスタンプを表す)、逆転した特徴、および周波数が変化した特徴に対して敏感です。一方、周期的な特徴類似性は、時間的なシフトが小さく、または逆転したインデックスがあるサンプルに対して高くなるべきであり、特徴の周波数が変化する際に連続的な類似性の変化を捉えるべきです。これは、フーリエ変換間の距離など、周波数領域の類似度尺度によって実現できます。 周波数領域で増強されたサンプルの固有の連続性を活用するために、SimPerは一般化された対照的損失を設計します。この損失は、古典的なInfoNCE損失をソフト回帰のバリアントに拡張し、連続的なラベル(周波数)に対して対比を可能にします。これにより、心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerは、周波数領域でデータのネガティブビューを構築することによって、データの変換を行います。入力シーケンスxには、関連する周期的な信号があります。SimPerは、xを変換して速度や周波数が変化したサンプルのシリーズを作成します。これにより、基礎となる周期的なターゲットが変わり、異なるネガティブビューが作成されます。元の周波数は不明ですが、未ラベルの入力xに対して疑似的な速度や周波数ラベル(周期性変数の増強τ)を効果的に設計します。SimPerは、入力の識別を変更しない変換を取り、これらを周期性に関して不変な増強σと定義し、サンプルの異なるポジティブビューを作成します。そして、これらの増強ビューをエンコーダfに送り、対応する特徴を抽出します。 結果 SimPerの性能を評価するために、人間の行動分析、環境リモートセンシング、および医療の共通の実世界タスクに対して、SimPerを最新のSSLスキーム(例:SimCLR、MoCo…

「データエンジニアリング入門ガイド」
データエンジニアリングに参入したいのですか?今日からデータエンジニアリングと基本的な概念について学ぶことから始めましょう

ラミニAIに会ってください:開発者が簡単にChatGPTレベルの言語モデルをトレーニングすることができる、革命的なLLMエンジン
LLMをゼロから教えることは難しいです。なぜなら、微調整されたモデルがなぜ失敗するのかを理解するのには時間がかかり、小さなデータセットに対する微調整の反復サイクルは通常数ヶ月かかるからです。一方、プロンプトの調整の反復サイクルは数秒で行われますが、数時間後には性能が安定します。倉庫のギガバイトのデータはプロンプトのスペースに収まりません。 Laminiライブラリのわずか数行のコードを使うことで、機械学習に精通していない開発者でも、巨大なデータセット上でChatGPTと同等の高性能LLMをトレーニングすることができます。Lamini.aiによってリリースされたこのライブラリの最適化は、プログラマが現在利用できるものを超えており、RLHFなどの複雑な技術や幻想抑制などの簡単な技術も含まれています。OpenAIのモデルからHuggingFaceのオープンソースのモデルまで、Laminiは1行のコードでさまざまなベースモデルの比較を実行することを簡単にします。 LLMを開発するための手順: Laminiは、微調整されたプロンプトとテキストの出力が可能なライブラリです。 Laminiライブラリを使用して簡単に微調整やRLHFを行う これは、指示に従うLLMをトレーニングするために必要なデータを作成するために商業利用が承認された最初のホストされたデータジェネレータです。 上記のソフトウェアを使用して指示に従うためのデータを作成するための最小限のプログラミング作業で無料でオープンソースのLLMを使用できます。 ベースモデルの英語の理解力は、一般の使用には十分です。しかし、自分の業界の専門用語や標準を教える場合、プロンプトの調整だけでは不十分であり、ユーザーは独自のLLMを開発する必要があります。 LLMは、以下の手順に従うことでChatGPTのようなユーザーケースを処理できます: ChatGPTのプロンプトの調整または他のモデルの使用。 チームは使いやすさを最適化し、LaminiライブラリのAPIを使用してモデル間を素早くプロンプト調整し、1行のコードでOpenAIとオープンソースのモデルを切り替えることができます。 大量の入出力データを作成。 これにより、それが受け取ったデータにどのように反応すべきかを示します。Laminiライブラリを使用してわずか100個から50,000個のデータポイントを生成するための数行のコードを含むリポジトリをリリースしました。このリポジトリには、パブリックで利用可能な50,000のデータセットが含まれています。 豊富なデータを使用して開始モデルを調整。 データジェネレータに加えて、合成データでトレーニングされたLamini調整LLMも共有しています。 微調整済みモデルをRLHFに通す。 Laminiは、RLHFを操作するために大規模な機械学習(ML)および人間のラベリング(HL)スタッフを必要としなくなります。 クラウドに置く。 アプリケーションでAPIのエンドポイントを呼び出すだけです。 37,000個の生成された指示(70,000個のフィルタリング後)でPythia基本モデルをトレーニングした後、オープンソースの指示に従うLLMをリリースしました。Laminiは、従来の手間をかけずにRLHFと微調整の利点をすべて提供します。まもなく、手続き全体を管理するようになるでしょう。 チームは、エンジニアリングチームのトレーニングプロセスを簡素化し、LLMのパフォーマンスを大幅に向上させることに興奮しています。反復サイクルをより速く効率的に行うことができれば、より多くの人々がプロンプトの調整だけでなく、これらのモデルを構築できるようになることを願っています。

「ドキュメントQ&AのためにローカルでCPU推論を実行するLlama 2」
サードパーティの商用大規模言語モデル(LLM)プロバイダー(例:OpenAIのGPT4)は、シンプルなAPI呼び出しを介してLLMの利用を民主化しましたしかし、チームはまだセルフマネージドまたはプライベートな展開が必要な場合もあります
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.