Learn more about Search Results リポジトリ - Page 66

- You may be interested
- TensorFlowモデルのハイパーパラメータ調...
- マサチューセッツ大学アマースト校のコン...
- 「GPT-4が怠け者です:OpenAIが認める」
- 「松ぼっくりベクトルデータベースとAmazo...
- AlphaTensorを使用して新しいアルゴリズム...
- 紛争のトレンドとパターンの探索:マニプ...
- 「RAGを忘れて、未来はRAG-Fusionです」
- 単一のマシンで複数のCUDAバージョンを管...
- 「Amazon Personalizeと生成AIでマーケテ...
- トランザクション分析:情報を解放し、貸...
- 「研究者がオンラインプライバシーについ...
- 統計分析入門ガイド | 5つのステップと例
- デルタレイク – パーティショニング...
- 『Talent.com』において
- このAI論文は、オープンエンドのシナリオ...

「2023年のトップデータウェアハウジングツール」
データウェアハウスは、データの報告、分析、および保存のためのデータ管理システムです。それはエンタープライズデータウェアハウスであり、ビジネスインテリジェンスの一部です。データウェアハウスには、1つ以上の異なるソースからのデータが保存されます。データウェアハウスは中央のリポジトリであり、複数の部門にわたる報告ユーザーが意思決定を支援するために設計された分析ツールです。データウェアハウスは、ビジネスや組織の歴史的なデータを収集し、それを評価して洞察を得ることができます。これにより、組織全体の統一された真実のシステムを構築するのに役立ちます。 クラウドコンピューティング技術のおかげで、ビジネスのためのデータウェアハウジングのコストと難しさは劇的に低下しました。以前は、企業はインフラに多額の投資をしなければなりませんでした。物理的なデータセンターは、クラウドベースのデータウェアハウスとそのツールに取って代わられています。多くの大企業はまだ古いデータウェアハウジングの方法を使用していますが、データウェアハウスが将来機能するのはクラウドであることは明らかです。使用料金ベースのクラウドベースのデータウェアハウジング技術は、迅速で効果的で非常にスケーラブルです。 データウェアハウスの重要性 現代のデータウェアハウジングソリューションは、データウェアハウスアーキテクチャの設計、開発、および導入の繰り返しのタスクを自動化することで、ビジネスの絶えず変化するニーズに対応しています。そのため、多くの企業がデータウェアハウスツールを使用して徹底的な洞察を獲得しています。 以上から、データウェアハウジングが大規模でボイジーサイズの企業にとって重要であることがわかります。データウェアハウスは、チームがデータにアクセスし、情報から結論を導き、さまざまなソースからデータを統合するのを支援します。その結果、企業はデータウェアハウスツールを以下の目標のために使用しています: 運用上および戦略上の問題について学ぶ。 意思決定とサポートのためのシステムを高速化する。 マーケティングイニシアチブの結果を分析し評価する。 従業員のパフォーマンスを分析する。 消費者のトレンドを把握し、次のビジネスサイクルを予測する。 市場で最も人気のあるデータウェアハウスツールは以下の通りです。 Amazon Redshift ビジネス向けのクラウドベースのデータウェアハウジングツールであるRedshiftです。完全に管理されたプラットフォームでペタバイト単位のデータを高速に処理できます。したがって、高速なデータ分析に適しています。さらに、自動の並列スケーリングがサポートされています。この自動化により、クエリ処理のリソースがワークロード要件に合わせて変更されます。オペレーションのオーバーヘッドがないため、同時に数百のクエリを実行できます。Redshiftはまた、クラスタをスケールアップしたりノードタイプを変更したりすることも可能です。その結果、データウェアハウスのパフォーマンスを向上させ、運用費用を節約することができます。 Microsoft Azure MicrosoftのAzure SQL Data Warehouseは、クラウドでホストされる関係データベースです。リアルタイムのレポート作成やペタバイト規模のデータの読み込みと処理に最適化されています。このプラットフォームは、大規模並列処理とノードベースのアーキテクチャ(MPP)を使用しています。このアーキテクチャは、並列処理のためのクエリの最適化に適しています。その結果、ビジネスインサイトの抽出と可視化が大幅に高速化されます。 データウェアハウスには数百のMS Azureリソースが互換性があります。たとえば、プラットフォームの機械学習技術を使用してスマートなアプリを作成することができます。さらに、IoTデバイスやオンプレミスのSQLデータベースなど、さまざまな種類の構造化および非構造化データをフォーラムに保存することができます。 Google BigQuery…

「トップの音声からテキストへのAIツール(2023年)」
インテリジェントな音声認識ソフトウェアは、AIとMLによって可能にされた最も価値のある機能の一つであり、自動的にオーディオやビデオのソースをテキストに翻訳します。これにより、ポッドキャスト、映画、会議、オンラインコースなどの転写が可能になり、さまざまな可能性が広がります。 コンピュータが人間の言語を処理、分析、解釈、推論するためには、自然言語処理(NLP)として知られるAIのサブフィールドが必要です。このサブフィールドは、AIの転写ソフトウェアとサービスの基礎となっています。自然言語処理(NLP)は、言語学やコンピュータ科学など、さまざまな学問からの手法を組み合わせた学際的な分野です。 AIの転写ソフトウェアとサービスは、製品のプロモーションなど、ビジネスの運営に大きく役立ちます。これにより、新規のクライアントを獲得することも支援されます。 優れた人工知能の転写ツールとサービスは、現在では簡単に利用できます。 Speak AI Speakは、重要な音声やビデオデータの記録と保存に複数のオプションを提供するため、AI転写サービスとして優れた選択肢です。Speakでは、埋め込み可能なレコーダーを作成したり、アプリ内で音声やビデオを録音したり、デバイスのストレージからコンテンツを簡単かつ迅速にアップロードしたりすることができます。バルクの音声/ビデオ/テキストデータのキャプチャに加えて、Speakはダッシュボードレポートの生成機能も提供します。この技術により、インタビューや通話、ビデオで議論された重要な詳細が失われないことを信頼できます。AIシステムは即座に超越し、関連する用語、テーマ、感情的ニュアンスを抽出します。Speakは、発見の共有とデータの隔離の解消も容易にします。トランスクリプト、AI分析、視覚化データはすべて1つの便利な場所にあり、包括的なデータリポジトリを構築し、ユニークで共有可能な素材を作成できます。 Trint TrintのAI転写により、オーディオやビデオファイルをテキストに迅速に変換し、他のドキュメントと同様に編集、検索、共有することができます。非構造化データを有用な情報に迅速に変換します。このサービスの最も強力な機能の一つは、メディアファイルを迅速に転写したり、リアルタイムでコンテンツを録音したりすることができる速さです。トランスクリプトから関連する部分を選択し、再生を選択して引用を読み上げたり、ストーリーを活気づけたりすることができます。タグ、ハイライト、コメントの使用も簡単で、共同作業を容易にします。一緒に魅力的なナレーションを作成し、承認のために同僚と簡単に共有することができます。Trintを使用すると、30以上の言語で情報を素早く簡単に転写し、他の50以上の言語に翻訳して国際的な観客に届けることができます。 Otter.ai Otterは、トップクラスの人工知能転写サービスです。このソフトウェアは、デスクトップ、Android、iOSデバイスで利用できるようになっています。同社はさまざまなパッケージを提供しており、それぞれ特別な利点があります。その中の一つでは、顧客が電話やコンピュータの会話を録音し、即座に転写することができます。二番目の機能では、話者を識別し区別することができます。Otterは、オーディオファイルの可変再生速度やトランスクリプトのアプリ内編集と管理を可能にします。音声やビデオファイルをインポートして転写することもでき、画像やその他のコンテンツを直接トランスクリプトに挿入することもできます。レイアウトはよく考えられており、使いやすく、録音ボタン、インポートボタン、最近のアクティビティの履歴などの便利な機能も備えています。初心者向けの有用なレッスンも含まれています。 Beey Beeyの助けを借りて、ビデオ、ポッドキャスト、会議議事録、ウェビナー、インタビュー、録音講義などをテキストに変換することができます。先進的な字幕システムにより、優れた字幕とキャプションを簡単に作成することができます。ビデオを組み込んだ機械翻訳ツールを使用して、ビデオを複数の言語に瞬時に翻訳して、より広い観客に簡単に届けることができます。自動音声認識ソフトウェアは、コンピュータ音声処理研究所が開発しました。このプラットフォームは、20以上の異なる言語に対応しており、真にグローバルな範囲を持っています。 NOVA AI NOVAは、映像のトリミング、編集、重ね合わせができる多目的なプログラムです。翻訳や字幕の追加も可能です。完全にWebベースであり、ダウンロードは必要ありません。動画のキャプションを作成する方法を学ぶ場所をお探しの場合、それを見つけました。Nova A.I.を使用すると、数回のクリックで動画の自動キャプションを生成し、視聴者の注意をより簡単に引きつけることができます。Nova A.I.は、オープンキャプションと閉じたキャプションを自動的に生成するために作られています。キャプションをビデオのソースコードに含めることで、視聴者がそれらを無効にすることができなくなります。また、字幕をSRT、VTT、TXTなどのさまざまな形式でコンピュータに保存することもできます。 Fireflies.ai Firefliesは、会議中の謄写、メモ作成、アクションを容易にするAI音声アシスタントであり、AI謄写ソフトウェアの優れた選択肢の1つです。このアプリケーションでは、他の人をセッションに招待してトークを録音して共有することができ、どのWeb会議サービスでも使用できます。ライブ会議やオーディオファイルは、簡単なアップロードで謄写することができます。トランスクリプトを素早くスキャンしながらオーディオを聴くことができます。Firefliesの強力な機能の1つは、コメントで通話を注釈付けたり、特定のセクションにフラグを立てたりすることができることです。トランスクリプトを使用すると、1時間の通話を5分で読むことができます。ツールを使用してボード全体で特定のアイテムやキーワードを検索することもできます。Firefliesには使いやすいダッシュボード、Chromeプラグイン、API/統合も備わっています。 Sonix Sonixは、多言語に対応した自動謄写サービスの中でもトップクラスです。Sonixを使用すると、ビジネスはオーディオやビデオコンテンツの謄写、カタログ化、検索を容易に行うことができます。この先進的なソフトウェアは、30分のビデオやオーディオをわずか3〜4分で謄写することができるため、迅速かつ正確な謄写が必要な企業に非常に役立ちます。コンピュータ生成のトランスクリプトでは単語が飛ばされることがあるため、Sonixではトランスクリプトを確認して編集することができます。ソフトウェアに含まれるオンラインエディタを使用すると、リアルタイムでトランスクリプトを変更することができます。最も自信のない用語がハイライトされ、さらなる研究のために示される単語信頼度も提供されます。これらの便利なツールに加えて、トランスクリプトでは後で詳しく調べるために重要なパッセージをハイライトや取り消し線で表示することもできます。話者のラベリングも簡単に行えるため、誰が何を言ったかを簡単に特定することができます。また、自動ダイアリゼーションも可能であり、Sonixは話者を自動的にタグ付けし、会話を段落ごとに分割します。 Rev.com 人工知能の謄写サービスに関して、Revは最高の1つです。大きな会社でも小さな会社でも、Revを使用してコンテンツのROIを向上させることができます。Revを使用することで、顧客層を拡大し、会社の露出を増やすことができます。Spotifyなどの多くの業界リーダーがRevを採用しています。Revは、5.6万時間以上の謄写データでスピーチモデルをトレーニングしたため、最も正確な音声認識エンジンを持っています。このソフトウェアは31の言語に対応しており、世界中の顧客にアプローチすることができます。Revは、人間と機械の両方の謄写、ビデオのクローズドキャプションや字幕など、さまざまなサービスを提供しています。ユーザーは、使いやすいドキュメンテーションと包括的なAPIを称賛しています。手続きの簡単さも称賛されており、誰でも使用できるとユーザーが指摘しています。…

「ミット、ハーバード、ノースイースタン大学による『山に針を見つける』イニシアチブは、Sparse Probingを用いてニューロンを見つける」
ニューラルネットワークは、初期の生の入力から適切な表現を徐々に洗練して学習する、適応型の「特徴抽出器」として考えられることが一般的です。そのため、次の疑問が生じます:どのような特性が表現され、どのように表現されているのでしょうか?高レベルで人間に解釈可能な特徴がLLM(Large Language Models)のニューロン活性化にどのように記述されているのかをよりよく理解するために、マサチューセッツ工科大学(MIT)、ハーバード大学(HU)、ノースイースタン大学(NEU)の研究チームは、スパースプロービングという技術を提案しています。 通常、研究者は、モデルの内部活性化を用いて基本的な分類器(プローブ)をトレーニングし、入力の特性を予測してから、ネットワークを調べて、質問された特徴がどこでどのように表現されているかを確認します。提案されたスパースプロービング法は、100以上の変数をプローブして関連するニューロンを特定するための手法です。この手法は、従来のプロービング手法の制約を克服し、LLMの複雑な構造に光を当てます。この手法では、プローブの予測にk個以下のニューロンしか使用しないように制限し、kの値は1から256の間で変動します。 研究チームは、最先端の最適スパース予測技術を使用して、kスパース特徴選択の副問題の小さなk最適性を実証し、ランキングと分類精度の混同を解決しています。彼らはスパース性を帰納バイアスとして使用し、プローブが強力な単純性の事前知識を保持し、詳細な検証のための重要なニューロンを特定できるようにしています。さらに、この手法は、興味のある特徴の相関パターンを記憶することを防ぐ容量不足により、特定の特性が明示的に表現され、後続で使用されているかどうかについて、より信頼性の高い信号を生成することができます。 研究グループは、自己回帰トランスフォーマーLLMsを実験に使用し、さまざまなk値でプローブをトレーニングした分類結果を報告しています。研究から以下のような結論を得ています: LLMsのニューロンは解釈可能な構造の豊富さを持ち、スパースプロービングはそれらを(重ね合わせでも)特定する効率的な方法であるが、厳密な結論を得るためには注意して使用し、分析を追加する必要がある。 初めのレイヤーの多くのニューロンが関連のないn-gramやローカルパターンのために活性化される場合、特徴は多義的なニューロンのスパースな線形組み合わせとしてエンコードされます。重みの統計やおもちゃのモデルから得られる洞察も、完全に接続されたレイヤーの最初の25%が重ね合わせを広範に使用していると結論付ける手がかりとなります。 一義性に関する決定的な結論は方法論的に到達できないが、特に中間層の一義的なニューロンは、より高いレベルの文脈的および言語的な特性(例:is_python_code)をエンコードする。 モデルが大きくなるにつれて表現のスパース性が上昇する傾向があるが、全体的には一貫していない。モデルが大きくなると、一部の特徴は専用のニューロンとして現れ、他の特徴はより細かい特徴に分割され、他の特徴は変化せずにランダムに到着する。 スパースプロービングのいくつかの利点 単一のニューロンを調査する際に、分類の品質とランキングの品質を混同するリスクをさらに軽減するために、最適性を保証するプローブが利用可能である。 また、スパースプローブは低いストレージ容量を持つように意図されているため、プローブがタスクを単独で学習できる可能性についての心配が少なくなります。 プローブには監視されたデータセットが必要ですが、一度構築すれば、任意のモデルを解釈するために使用できます。これにより、学習した回路の普遍性や自然な抽象化仮説などの研究の可能性が広がります。 主観的な評価に頼る代わりに、異なるアーキテクチャの選択が多義的な要素と重ね合わせの発生にどのように影響を与えるかを自動的に調べるために使用することができます。 スパースプロービングには制限があります プロービング実験データからの強力な推論は、特定のニューロンの同定の追加の二次的な調査とともに行われる必要があります。 プロービングは実装の詳細、異常、誤った指定、プロービングデータセットの誤解を受けることに対して感度があり、因果関係については限定的な洞察しか提供しません。 特に解釈性の観点からは、スパースプローブは複数のレイヤーを超えて構築された特徴を認識することができず、重ね合わせと多数の異なるより細かい特徴の和として表現される特徴を区別することもできません。 スパースプロービングがプロービングデータセットの冗長性により一部の重要なニューロンを見逃す場合、すべての有意なニューロンを特定するために反復的な剪定が必要になる場合があります。複数のトークン特性を使用するには、一般に集約を使用した特殊な処理が必要であり、その結果の特異性がさらに低下する可能性があります。 革命的な疎なプロービング技術を使用して、私たちの研究はLLM(Language Model)において、豊富で人間に理解しやすい構造を明らかにします。科学者たちは、AIの助けを借りて、バイアス、正義、安全性、高リスクの意思決定に特に関連する詳細を記録する、広範なプロービングデータセットのリポジトリを構築する予定です。彼らは他の研究者にもこの「野心的な解釈可能性」の探求に参加することを奨励し、自然科学に似た実証的なアプローチが通常の機械学習の実験ループよりも生産的であると主張しています。広範で多様な教師付きデータセットを持つことで、AIの進歩に遅れを取らないために必要な次世代の教師なし解釈可能性技術の改善評価が可能になるだけでなく、新しいモデルの評価を自動化することも可能になります。
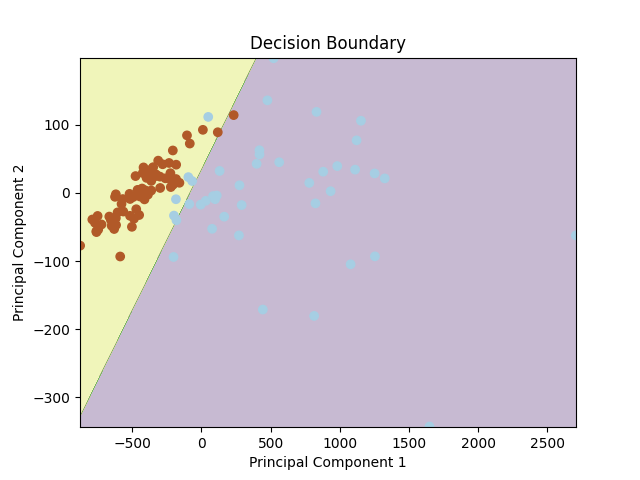
「ロジスティック回帰:直感と実装」
ロジスティック回帰は、2つの異なるデータ属性の間の決定境界を学習できる基本的な二値分類アルゴリズムですこの記事では、理論的な理解を深めるために、...

AI チュートリアル Open AI と GitHub を使用して Streamlit で AI チャットアプリを起動する方法
この記事では、「Streamlit」というサービスについて話し合います私たちが必要とするものには最適ですPythonの初心者であっても、自分自身のAIチャットアプリを作成して共有するために使用することができました以下で説明します...
「Python Pre-Commitフックを使用して、コード品質を自動化する方法」
もしPythonの開発者であれば、チームメンバーが異なるコーディングスタイルを持っており、コードベースが一貫性を欠いている状況に頻繁に遭遇するかもしれませんその結果、バグが発生することがあります...

データスクレイピングが注目されています:言語モデルは皆のコンテンツをトレーニングすることで飛び越えているのでしょうか?
この記事の調査をまとめ、執筆を始めようとしたとき、OpenAIはそれにぴったりの発表を行いました彼らはChatGPTの「Browse with Bing」機能を一時的に無効にしているとのことです...

アマゾンセージメーカーの地理空間機能を使用して、齧歯類の被害を分析する
「ネズミやネズミなどのげっ歯類は、多くの健康リスクと関連しており、35以上の病気を広めることが知られています高いネズミの活動がある地域を特定することは、地方自治体や害虫駆除組織が効果的な介入計画を立て、ネズミを駆除するのに役立ちますこの記事では、どのように監視し、視覚化するかを紹介します...」

「データサイエンスの仕事を得る方法?[8つの簡単なステップで解説]」
データサイエンス分野での有望なキャリアは競争が激化しています。多くの候補者が役職を得るために激しく競い合っている中、機会はしばしば適切なスキルと経験を持つ人々に与えられます。データサイエンスの仕事を得るための前提条件や答えは、以下の8つの詳細なステップにあります。 データサイエンスの仕事を得るための8つのステップ 以下の8つのステップに従って、希望するデータサイエンスの仕事を得ることができます。 ステップ1:目標とパスを明確にする データサイエンスのキャリア目標を明確にする キャリアの目標を明確に定義し、経験レベルと専門知識に基づいてデータサイエンスのキャリア目標を明確に定義します。短期目標として、インターンシップや初級職のデータアナリストになることを考えてください。中期目標には、専門家としての知識を持ち、研究論文を発表することが含まれます。長期目標には、トップのデータサイエンティストになること、企業との協力、企業の立ち上げ、大学や学術誌への貢献などが含まれる場合があります。 さまざまなデータサイエンスの役割を調査し、自分の興味とスキルに合ったものを選ぶ さまざまなデータサイエンスの役割を調査し、興味とスキルに合った役割を選択します。データアナリストになる、機械学習をマスターする、自然言語処理に特化する、ビッグデータプロジェクトに取り組む、またはディープラーニングを進めるなどの選択肢があります。 希望する役割に必要なスキルと知識を特定し、学習計画を作成する データサイエンスに入る方法について考えていますか?学習計画を作成しましょう。これには、認定コースへの参加、YouTubeでの無料講義の受講、書籍からの情報収集、他の専門家との協力などが含まれます。さらに、新卒者としてデータアナリストの仕事を得る方法やデータサイエンスの仕事を得る方法についての回答をするために、以下の表にはさまざまなデータサイエンスの役割に必要なスキルと知識が示されています。 役割 スキル 知識 データアナリスト データの操作と可視化、Excel、SQL、データの可視化ライブラリ データのクリーニング、前処理、クエリ、可視化 機械学習 アルゴリズム、ハイパーパラメータの調整、モデルの選択、評価指標、TensorFlow、scikit-learn、PyTorch 教師あり学習と教師なし学習、クラスタリング、回帰、分類、アンサンブル法、ディープラーニングのアーキテクチャ 自然言語処理 NLPライブラリ、フレームワーク、spaCy、NLTK、transformers、分類、エンティティ認識、感情分析、言語モデルの微調整 単語の埋め込み、再帰型ニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)、テキストの前処理 ビッグデータ 大規模データ処理、分散環境でのストレージと処理…
Python プロジェクトの設定:パート VI
🐍 Pythonのベテラン開発者であろうと、始めたばかりの開発者であろうと、堅牢でメンテナンス性の高いプロジェクトの構築方法を知ることは重要ですこのチュートリアルでは、プロセスを案内します...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.