Learn more about Search Results リポジトリ - Page 65

- You may be interested
- 「UCLA研究者がGedankenNetを紹介:物理法...
- Pd.Get_Dummiesの良い面、悪い面、そして...
- 「AIはオーディオブック制作をどのように...
- 『ランチェーンでチェーンを使用するため...
- 27/11から03/12までの週の主要なコンピュ...
- 「MITとAdobeの研究者が、一つのステップ...
- 私が初めての#30DayChartChallengeを使っ...
- 「時間管理のための15の最高のChatGPTプロ...
- このAIの論文は、FELM:大規模な言語モデ...
- 「PyrOSM Open Street Mapデータとの作業」
- 「あなたのMLアプリケーションを際立たせ...
- PyTorchを使用して畳み込みニューラルネッ...
- GPTを使用した、OpenAIのパーソナルAIアプ...
- 「2024年に試してみるべき5つの最高のベク...
- VoAGIニュース、10月27日:データサイエン...
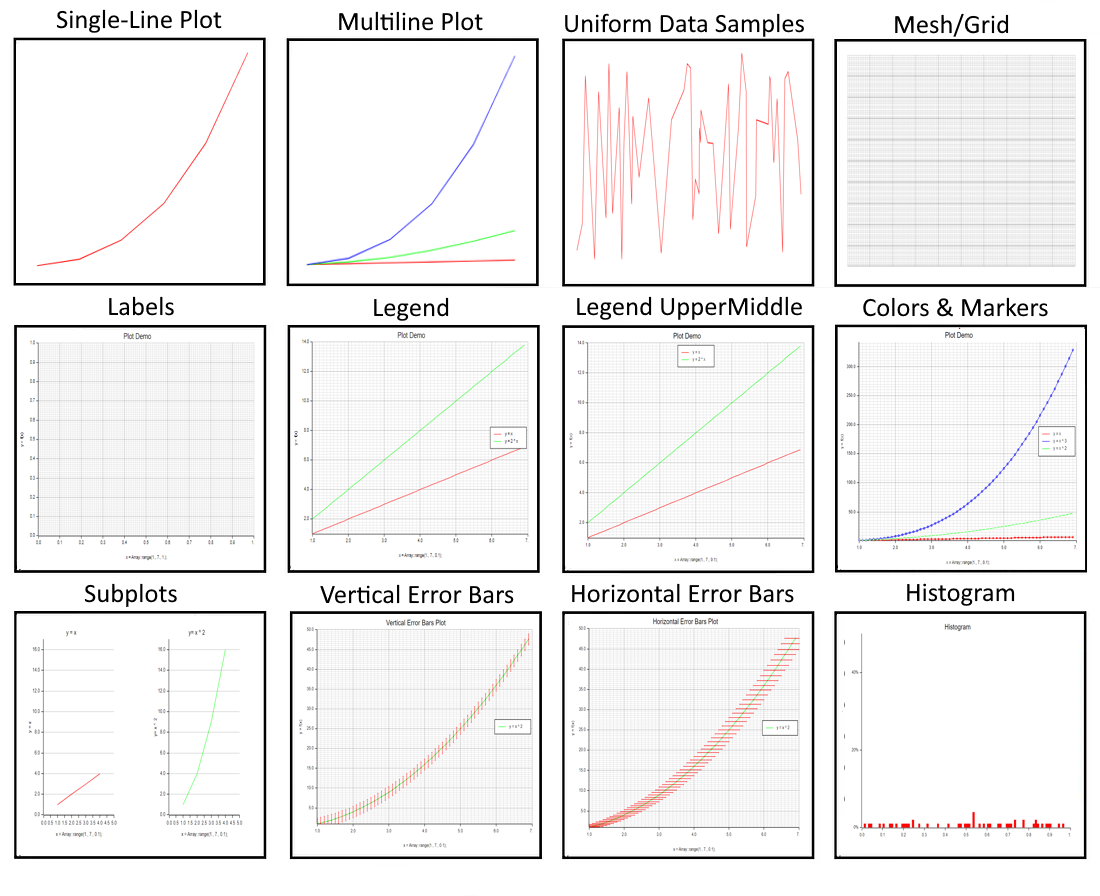
「ラスティックデータ:Plottersを使用したデータの可視化ー第1部」
プロッターは、データの視覚化のための人気のあるRustライブラリです高品質のグラフ、チャート、およびその他の視覚化を作成するためのさまざまなツールと機能を提供していますこれは...

新しい技術の詳細なコース:AWS上の生成AIの基礎
「AWS上の生成AIの基礎」は、AWSやその他のプラットフォーム上で最新の基礎モデルを事前トレーニング、微調整、展開するための概念的な基礎、実践的なアドバイス、ハンズオンガイダンスを提供する新しい技術的な詳細なコースですAWS生成AIの世界的な基礎リーダーであるエミリー・ウェバーが開発し、この無料のハンズオンコースとサポートするGitHubのソースコード[...]
このAIニュースレターは、あなたが必要とするすべてです #57
「AIの世界では、LLMモデルのパフォーマンス評価が注目の話題となりました特に、スタンフォードとバークレーの学生による最近の研究についての活発な議論がありました...」

OpenAIがBaby Llamaを発表 – 低電力デバイス向けのLLM!
人工知能の世界からの最新ニュース! OpenAIの有名な深層学習の専門家、Andrej Karpathy氏が、リソース制約のあるデバイス上で複雑なモデルを実行する方法を革新する可能性のあるエキサイティングな週末プロジェクトに取り組んでいます。彼の「Baby Llama」という作品は、Llama 2モデルの簡略化バージョンであり、純粋なCコードの力とその小さなマシンで高度にインタラクティブなレートを実現する可能性を示しています。この画期的な開発について詳しく見ていきましょう! また読む:OpenAI、AIモデルの公開を通じてオープンソース競争に参加 インタラクティブレートを目指して – ベビーラマの誕生 深層学習の分野でのパイオニアであるAndrej Karpathy氏は、新しい可能性を探求する好奇心に駆られ、オープンソースのLlama 2のポテンシャルを解き放つための使命に取り組みました。週末にGPT-5を構築する能力を持っていたにもかかわらず、Karpathy氏はAIの限界を押し広げる情熱を示すためにLlama 2の実験に時間を費やしました。 また読む:MetaのLlama 2:商業利用のためのオープンソース化 GPT-2からLlama 2への変換:週末の実験 GithubのリポジトリであるLlama2.cで、Karpathy氏は彼の創造的なプロセスについての洞察を共有しました。彼はnanoGPTフレームワークを使用し、Cプログラミング言語で書かれたLlama 2アーキテクチャに巧みに変換しました。その結果、彼のリポジトリは短期間で2.2K以上のスターを集めることができました。 リソース制約モデルでのインタラクティブレート Karpathy氏の実験の中で最も驚くべき成果の一つは、比較的小さいモデルで非常にインタラクティブなレートを実現できたことです。数百万のパラメータを含むモデルを使用しており、1500万のパラメータでトレーニングされたTinyStoriesデータセットを使用していますが、Karpathy氏のアプローチは驚くほど成功しました。 また読む:30BのパラメータでGPT-3を凌駕する新しいAIモデル 低電力デバイスでの驚異的な速度 Karpathy氏は自身のM1…

「Quivrに会ってください:第2の脳のように構造化されていない情報を保存し、取得するためのオープンソースプロジェクト」
過去数年間、OpenAIのドメインは持続的な成長を遂げてきました。多くの大学の研究者がオープンソースのプロジェクトを構築し、データサイエンスの発展に貢献しています。Stan Girarによって構築されたオープンソースプロジェクトの1つがQuivrです。それは第二の脳とも呼ばれ、現在のデータモデルやスキーマに従って整理されていないデータを格納し、従って伝統的な関係データベースやRDBMSに格納することはできません。テキストとマルチメディアは、非構造化コンテンツの2つの一般的なタイプです。 Quivrの公式ウェブサイトから、ボタン「試しにやってみる」をクリックしてQuivrのプレミアムバージョンにアクセスすることができます。制限なしでQuivrを使用したい場合は、デバイスにローカルにダウンロードすることもできます。Quivrのインストールには適切な手順があります。Quivrのリポジトリをローカルデバイスにクローンし、それをナビゲートする必要があります。また、仮想環境を作成し、デバイスでアクティベートする必要もあります。すべての依存関係をインストールし、Streamlitのシークレットをコピーし、重要な認証情報を追加する必要もあります。最後に、これらの手順を経てQuivrアプリを実行できるはずです。OpenAIの公式ウェブサイトからも参照できます。また、デバイスには公式で最新のPythonのバージョンが事前にインストールされている必要があります。Quivrをインストールするローカルデバイス上で仮想のPythonプログラミング環境を作成できる公式のツールも必要です。 QuivrのオープンAIソフトウェアには、非構造化データと情報を保存するためのさまざまな機能があります。Quivrは画像、テキスト、コードテンプレート、プレゼンテーション、ドキュメント、CSVおよびxlsxファイル、PDFドキュメントなど、任意のデータセットを保存できます。自然言語処理技術の助けを借りて、情報を生成し、より多くのデータを生成するのにも役立ちます。高度な人工知能の助けを借りて、失われた情報を取り戻すこともできます。Quivrは、データセットにできるだけ迅速にアクセスして出力を通じて提供するため、高速です。データはクラウドに適切に保存されているため、Quivrからデータを失うことはありません。 Quivrは情報検索の能力をクラウドシステムと統合したオープンソースのアプリケーションです。それは将来的にはほとんどの人々によって生産性を向上させるために使用されるソフトウェアになるでしょう。Quivrを使用する主な利点は、同時にさまざまなツールを処理できることです。これからのデータサイエンスや人工知能の分野で新興技術となることでしょう。

「Amazon EC2 Inf1&Inf2インスタンス上のFastAPIとPyTorchモデルを使用して、AWS Inferentiaの利用を最適化する」
「ディープラーニングモデルを大規模に展開する際には、パフォーマンスとコストのメリットを最大限に引き出すために、基盤となるハードウェアを効果的に活用することが重要です高スループットと低レイテンシーを必要とするプロダクションワークロードでは、Amazon Elastic Compute Cloud(EC2)インスタンス、モデルの提供スタック、展開アーキテクチャの選択が非常に重要です効率の悪いアーキテクチャは[…]」
「Polarsによるデータパイプライン:ステップバイステップガイド」
この投稿の目的は、Polarsを使用してデータパイプラインを構築する方法を説明し、示すことですこれは、このシリーズの前の2つのパートで得たすべての知識を組み合わせて使用するため、もしもあなたが...
相互に接続された複数ページのStreamlitアプリを作成する方法
注意:この記事はもともとStreamlitブログで紹介されていましたVoAGIコミュニティの皆様にご覧いただくために、こちらでも共有したいと思いますわぁ!私が初めてブログ記事を公開してから、なんとも信じられない3ヶ月です...

DPT(Depth Prediction Transformers)を使用した画像の深度推定
イントロダクション 画像の深度推定は、画像内のオブジェクトがどれだけ遠いかを把握することです。これは、3Dモデルの作成、拡張現実、自動運転などのコンピュータビジョンの重要な問題です。過去には、ステレオビジョンや特殊センサなどの技術を使用して深度を推定していました。しかし、今では、ディープラーニングを利用するDepth Prediction Transformers(DPT)と呼ばれる新しい方法があります。 DPTは、画像を見ることで深度を推定することができるモデルの一種です。この記事では、実際のコーディングを通じてDPTの動作原理、その有用性、およびさまざまなアプリケーションでの利用方法について詳しく学びます。 学習目標 密な予測トランスフォーマ(DPT)の概念と画像の深度推定における役割。 ビジョントランスフォーマとエンコーダーデコーダーフレームワークの組み合わせを含むDPTのアーキテクチャの探索。 Hugging Faceトランスフォーマライブラリを使用したDPTタスクの実装。 さまざまな領域でのDPTの潜在的な応用の認識。 この記事はData Science Blogathonの一部として公開されました。 深度推定トランスフォーマの理解 深度推定トランスフォーマ(DPT)は、画像内のオブジェクトの深度を推定するために特別に設計されたディープラーニングモデルの一種です。DPTは、元々言語データの処理に開発されたトランスフォーマと呼ばれる特殊なアーキテクチャを利用して、ビジュアルデータを処理するために適応し適用します。DPTの主な強みの1つは、画像のさまざまな部分間の複雑な関係をキャプチャし、長距離にわたる依存関係をモデル化する能力です。これにより、DPTは画像内のオブジェクトの深度や距離を正確に予測することができます。 深度推定トランスフォーマのアーキテクチャ 深度推定トランスフォーマ(DPT)は、ビジョントランスフォーマをエンコーダーデコーダーフレームワークと組み合わせて画像の深度を推定します。エンコーダーコンポーネントは、セルフアテンションメカニズムを使用して特徴をキャプチャしてエンコードし、画像のさまざまな部分間の関係を理解する能力を向上させます。これにより、細かい詳細を捉えることができます。デコーダーコンポーネントは、エンコードされた特徴を元の画像空間にマッピングすることで密な深度予測を再構築し、アップサンプリングや畳み込み層のような手法を利用します。DPTのアーキテクチャにより、モデルはシーンのグローバルなコンテキストを考慮し、異なる画像領域間の依存関係をモデル化することができます。これにより、正確な深度予測が可能になります。 要約すると、DPTはビジョントランスフォーマとエンコーダーデコーダーフレームワークを組み合わせて画像の深度を推定します。エンコーダーは特徴をキャプチャし、セルフアテンションメカニズムを使用してそれらをエンコードし、デコーダーは密な深度予測を再構築します。このアーキテクチャにより、DPTは細かい詳細を捉え、グローバルなコンテキストを考慮し、正確な深度予測を生成することができます。 Hugging Face Transformerを使用したDPTの実装 Hugging Faceパイプラインを使用してDPTの実践的な実装を見ていきます。コードの全体はこちらでご覧いただけます。…

2023年の機械学習研究におけるトップのデータバージョン管理ツール
生産に使用されるすべてのシステムはバージョン管理する必要があります。ユーザーが最新のデータにアクセスできる単一の場所です。特に多くのユーザーが同時に変更を加えるリソースには監査トレイルを作成する必要があります。 チーム全員が同じページにいることを確保するために、バージョン管理システムが担当しています。それにより、チーム全員が同時に同じプロジェクトで協力し、ファイルの最新バージョンで作業していることが保証されます。適切なツールがあれば、このタスクを迅速に完了することができます! 信頼性のあるデータバージョン管理方法を採用すると、一貫性のあるデータセットとすべての研究の完全なアーカイブを持つことができます。データバージョニングソリューションは、再現性、トレーサビリティ、およびMLモデルの履歴に関心がある場合、ワークフローに必須です。 データセットやモデルのハッシュなどのオブジェクトのコピーを取得し、区別して比較するために使用できるデータバージョンが頻繁にメタデータ管理ソリューションに記録されるようにすると、モデルのトレーニングがバージョン管理され、繰り返し可能になります。 さあ、コードの各コンポーネントを追跡できる最高のデータバージョン管理ツールを調べてみましょう。 Git LFS Git LFSプロジェクトの使用は制限されていません。Gitは、GitHub.comやGitHub Enterpriseなどのリモートサーバーに大きなファイルの内容を保存し、大きなファイルをテキストポインターで置き換えます。音声サンプル、映画、データベース、写真など、置き換えられるファイルの種類には大きなファイルが含まれます。 Gitを使用して大規模なファイルリポジトリを迅速にクローンして取得したり、外部ストレージを使用してGitリポジトリでより多くのファイルをホストしたり、数GBの大きさの大きなファイルをバージョン管理することができます。データの取り扱いにおいては比較的シンプルな解決策です。他のツールキット、ストレージシステム、スクリプトは必要ありません。ダウンロードするデータ量を制限します。これにより、大きなファイルのコピーがリポジトリから取得するよりも速くなります。ポイントはLFSを指し、より軽い素材で作られています。 LakeFS LakeFSは、S3またはGCSにデータを格納するオープンソースのデータバージョニングソリューションであり、Gitに似たブランチングおよびコミット方法をスケーラブルに実装しています。このブランチング方法により、別々のブランチで変更を可能にし、アトミックかつ即座に作成、マージ、およびロールバックできるようにすることで、データレイクをACID準拠にします。 LakeFSを使用すると、繰り返し可能でアトミックなデータレイクの活動を開発することができます。これは新しいものですが、真剣に取り組む必要があります。Gitのようなブランチングとバージョン管理の方法を使用してデータレイクとやり取りし、ペタバイト単位のデータをスケーラブルにチェックできます。 DVC Data Version Controlは、データサイエンスや機械学習のアプリケーションに適したアクセス可能なデータバージョニングソリューションです。このアプリケーションを使用してパイプラインを任意の言語で定義することができます。 DVCは、その名前が示すように、データバージョニングに特化しているわけではありません。このツールは、大きなファイル、データセット、機械学習モデル、コードなどを管理することで、機械学習モデルを共有可能かつ再現可能にします。さらに、チームがパイプラインと機械学習モデルを管理しやすくします。このアプリケーションは、迅速に設定できる簡単なコマンドラインを提供することで、Gitの例にならっています。 最後に、DVCはチームのモデルの再現性と一貫性を向上させるのに役立ちます。コードの複雑なファイルの接尾辞やコメントではなく、Gitのブランチを使用して新しいアイデアをテストします。旅行中にペーパーや鉛筆ではなく、自動的なメトリックトラッキングを使用します。 プッシュ/プルコマンドを使用して機械学習モデル、データ、およびコードの一貫したバンドルを製品環境、リモートマシン、または同僚のデスクトップに転送するためのアドホックなスクリプトではなく使用します。 DeltaLake DeltaLakeというオープンソースのストレージレイヤーにより、データレイクの信頼性が向上します。Delta Lakeは、バッチおよびストリーミングデータ処理をサポートするだけでなく、スケーラブルなメタデータ管理も提供します。現在のデータレイクに基づいており、Apache…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.