Learn more about Search Results A - Page 659

- You may be interested
- 「エンタープライズ環境におけるゼロトラ...
- 「より良いデータセットが新しいSOTAモデ...
- 「VirtuSwapがAmazon SageMaker Studioの...
- 分岐と限定法 -アルゴリズムをスクラッチ...
- AIOpsの力を解き放つ:最適化されたITオペ...
- 「SuperDuperDBを活用して簡単にシンプル...
- エクスラマV2:LLMを実行するための最速の...
- 「Googleのトレイルブレイザーのインスピ...
- メタのラマ2:商業利用のためのオープンソ...
- 「Google Bard vs. ChatGPT ビジネスにお...
- UC San Diegoの研究者がTD-MPC2を発表:多...
- オープンAIのファンクションコーリング入門
- 線形回帰と勾配降下法
- 複雑な生成型AIユースケースにおいて、Hug...
- 「人工知能と人間の知能の相互作用の探求」

テキストから音声へ – 大規模な言語モデルのトレーニング
はじめに 音楽家の声コマンドをAIが受け取り、美しいメロディックなギターサウンドに変換する世界を想像してみてください。これはSFではありません。オープンソースコミュニティでの画期的な研究「The Sound of AI」の成果です。本記事では、「テキストからサウンドへ」というジェネレーティブAIギターサウンドの範囲内で、「ミュージシャンの意図認識」のための大規模言語モデル(LLM)の作成の道のりを探求します。このビジョンを実現するために直面した課題と革新的な解決策についても議論します。 学習目標: 「テキストからサウンド」のドメインでの大規模言語モデルの作成における課題と革新的な解決策を理解する。 声コマンドに基づいてギターサウンドを生成するAIモデルの開発において直面する主な課題を探求する。 ChatGPTやQLoRAモデルなどのAIの進歩を活用した将来のアプローチについて、ジェネレーティブAIの改善に関する洞察を得る。 問題の明確化:ミュージシャンの意図認識 問題は、AIが音楽家の声コマンドに基づいてギターサウンドを生成できるようにすることでした。例えば、音楽家が「明るいギターサウンドを出してください」と言った場合、ジェネレーティブAIモデルは明るいギターサウンドを生成する意図を理解する必要があります。これには文脈とドメイン特有の理解が必要であり、一般的な言語では「明るい」という言葉には異なる意味がありますが、音楽のドメインでは特定の音色の品質を表します。 データセットの課題と解決策 大規模言語モデルのトレーニングには、モデルの入力と望ましい出力に一致するデータセットが必要です。ミュージシャンのコマンドを理解し、適切なギターサウンドで応答するために、適切なデータセットを見つける際にいくつかの問題が発生しました。以下に、これらの問題の対処方法を示します。 課題1:ギターミュージックドメインのデータセットの準備 最初の大きな課題は、ギターミュージックに特化したデータセットが容易に入手できないことでした。これを克服するために、チームは独自のデータセットを作成する必要がありました。このデータセットには、音楽家がギターサウンドについて話し合う会話が含まれる必要がありました。Redditの議論などのソースを利用しましたが、データプールを拡大する必要があると判断しました。データ拡張、BiLSTMディープラーニングモデルの使用、コンテキストベースの拡張データセットの生成などの技術を使用しました。 課題2:データの注釈付けとラベル付きデータセットの作成 2番目の課題は、データの注釈付けを行い、ラベル付きのデータセットを作成することでした。ChatGPTなどの大規模言語モデルは一般的なデータセットでトレーニングされることが多く、ドメイン固有のタスクに対してファインチューニングが必要です。例えば、「明るい」という言葉は、光や音楽の品質を指す場合があります。チームは、正しい文脈をモデルに教えるために、Doccanoという注釈付けツールを使用しました。ミュージシャンは楽器や音色の品質に関するラベルをデータに注釈付けしました。ドメインの専門知識が必要であるため、注釈付けは困難でしたが、チームはデータを自動的にラベル付けするためにアクティブラーニングの手法を一部適用し、これに対処しました。 課題3:MLタスクとしてのモデリング – NERアプローチ 適切なモデリングアプローチを決定することもまた、別のハードルでした。トピックまたはエンティティの識別として見るべきでしょうか?チームは、モデルが音楽に関連するエンティティを識別して抽出できるNamed Entity Recognition(NER)を採用しました。spaCyの自然言語処理パイプライン、HuggingFaceのRoBERTaなどのトランスフォーマーモデルを活用しました。このアプローチにより、ジェネレーティブAIは音楽のドメインにおける「明るい」や「ギター」といった単語の文脈を認識できるようになりました。 モデルトレーニングの課題と解決策…
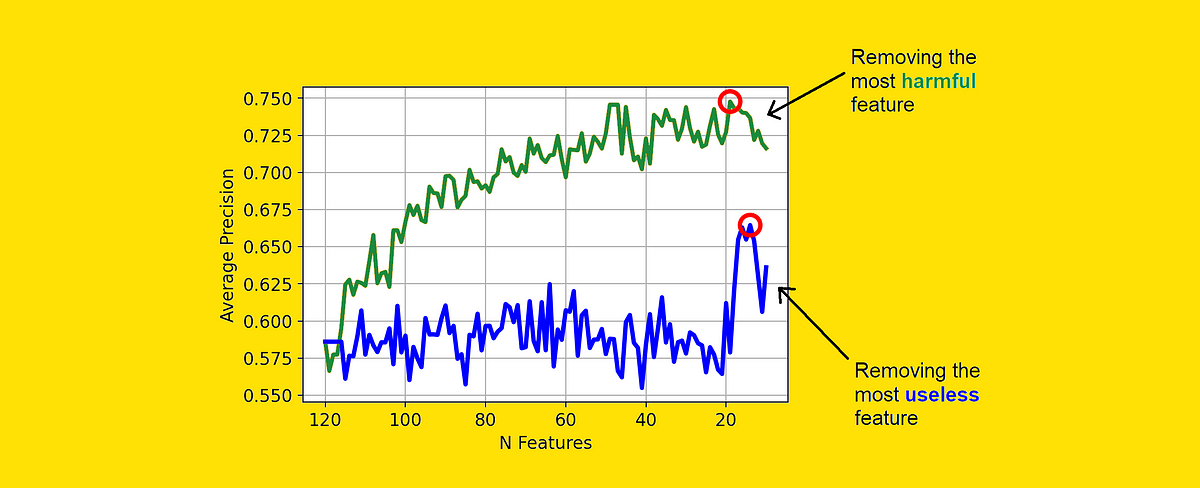
「あなたの分類モデルにとって有害な特徴はどれですか?」
特徴の重要性は、機械学習モデルを説明するための最も一般的なツールですそれは非常に人気があり、多くのデータサイエンティストが特徴の重要性と特徴の良さが等しいと信じ込むことになるほどです

マルコフとビネメ・シェビシェフの不等式
「2つの境界の意味と、その発見につながる魅力的で風変わりな出来事を理解する」
大規模言語モデル:SBERT
「トランスフォーマーが自然言語処理(NLP)において進化的な進歩を遂げたことは秘密ではありませんトランスフォーマーを基に、他の多くの機械学習モデルも進化していますその中の一つがBERTであり、主にいくつかの要素から構成されています...」

マイクロソフトの研究者がPromptTTS 2を発表:声の変動性と費用対効果の向上によるテキスト読み上げの革新
合成音声の理解度と自然さは、最近のテキスト読み上げシステムの進歩により向上しています。大規模なTTSシステムは、複数の話者の設定に対応するために作成され、一部のTTSシステムは単一の話者の録音と同等の品質に達しています。これらの進歩にもかかわらず、声の変動性をモデル化することはまだ困難です。同じフレーズを言う方法が異なる場合、感情やトーンなどの追加情報を伝えることができます。従来のTTS技術は、スピーカー情報や音声プロンプトに頼ることが多く、声の変動性をシミュレートするために使用されます。しかし、これらの技術はユーザーフレンドリーではありません。スピーカーIDが事前に定義されており、適切な音声プロンプトを見つけることが困難または存在しないためです。 声の変動性をモデル化するより有望なアプローチは、音声生成の意図を伝えるために自然言語を使用するテキストプロンプトを利用することです。この戦略により、テキストプロンプトを使用して簡単に声を作成することができます。テキストプロンプトに基づくTTSシステムは、通常、音声データセットとそれに対応するテキストプロンプトを使用してトレーニングされます。音声の変動性やスタイルを説明するテキストプロンプトを使用して、モデルが音声を生成する方法を制御します。 テキストプロンプトに基づくTTSシステムは、次の2つの主な課題に直面しています: • 一対多の課題:声の品質は人によって異なるため、書かれた指示ではすべての音声の側面を正確に表現することは困難です。異なる音声サンプルは不可避的に同じプロンプトに関連付けられる場合があります。一対多の現象は、TTSモデルのトレーニングをより困難にし、過学習やモードの崩壊を引き起こす可能性があります。彼らの知る限り、テキストプロンプトに基づくTTSシステムにおいて一対多の問題を解決するために明示的に作成された手順は存在していません。 • データスケールの課題:テキストプロンプトはインターネット上では一般的ではないため、声を定義するテキストプロンプトのデータセットを作成することは容易ではありません。 その結果、ベンダーにテキストプロンプトを作成するために雇われることがあり、これは費用と時間のかかる作業です。プロンプトデータセットは通常小さく、またはプライベートであり、プロンプトベースのTTSシステムに関するさらなる研究を行うことが困難です。彼らの研究では、PromptTTS 2を提供し、プロンプトでは捉えることのできない音声の変動情報をモデル化するためのバリエーションネットワークの提案を行っています。大規模な言語モデルを使用して高品質のプロンプトを生成し、上記の課題に取り組んでいます。彼らはバリエーションネットワークを提案し、テキストプロンプトから音声の変動に関する欠落した情報を予測するためにトレーニングに参加する参照音声を使用します。 PromptTTS 2のTTSモデルは、テキストプロンプトエンコーダ、参照音声エンコーダ、テキストプロンプトエンコーダと参照音声エンコーダによって取得された表現に基づいて音声を合成するTTSモジュールから構成されます。テキストプロンプトエンコーダ3からの即時表現に基づいて、バリエーションネットワークは参照音声エンコーダからの参照表現を予測するためにトレーニングされます。テキストプロンプトに条件付けられたガウスノイズから多様な音声の変動性に関する情報を選択するために、バリエーションネットワーク内の拡散モデルを使用して合成音声の品質を変更することができます。 マイクロソフトの研究者は、音声理解モデルを使用して音声から声の特徴を認識し、大規模な言語モデルを使用して認識結果に基づいてテキストプロンプトを構築することで、音声のためのテキストプロンプトを自動的に作成するためのパイプラインを提案しています。具体的には、音声理解モデルを使用して、音声データセット内の各音声サンプルの属性値を識別し、さまざまな特徴から声を説明します。次に、これらのフレーズを組み合わせてテキストプロンプトを作成します。以前の研究では、ベンダーによるフレーズの構築と組み合わせに頼っていましたが、PromptTTS 2では、さまざまなタスクを人と同等のレベルで実行することが証明されている大規模な言語モデルを使用しています。 彼らは、優れたプロンプトを作成するためのLLMの指示を提供します。完全に自動化されたワークフローのおかげで、プロンプトの作成にはもはや人間の介入は必要ありません。以下は、この論文の貢献の要約です: • テキストプロンプトに基づくTTSシステムにおける一対多の問題を解決するために、拡散モデルに基づくバリエーションネットワークを構築し、テキストプロンプトではカバーされていない音声の変動性を説明します。音声の変動性は、推論中にテキストプロンプトに条件付けられたガウスノイズからのサンプルを選択することによって管理することができます。 • テキストプロンプトの作成パイプラインと大規模な言語モデルによって生成されたテキストプロンプトデータセットを構築し、高品質なプロンプトを提供します。このパイプラインにより、ベンダーへの依存が軽減されます。 • 44000時間の音声データを使用して、彼らはPromptTTS 2を大規模な音声データセットでテストします。実験の結果、PromptTTS 2は、ガウスノイズからサンプリングすることで音声の変動を制限する一方で、テキストのプロンプトにより近い声を生成するという以前の研究を上回っています。

現実世界における機械学習エンジニアリング
「機械学習、分析、関連分野で働く私たちの大多数は、さまざまな組織のために働いていますこれらは、営利企業、非営利団体、チャリティ団体、政府や大学などの公的部門のいずれかかもしれませんほとんどの場合、私たちは...」

「PhysObjectsに会いましょう:一般的な家庭用品の36.9K個のクラウドソーシングと417K個の自動物理的概念アノテーションを含むオブジェクト中心のデータセット」
現実世界では、情報はしばしばテキスト、画像、または動画の組み合わせによって伝えられます。この情報を効果的に理解し、対話するためには、AIシステムは両方のモダリティを処理できる必要があります。ビジュアル言語モデルは、自然言語理解とコンピュータビジョンの間のギャップを埋め、より包括的な世界の理解を可能にします。 これらのモデルは、テキストとビジュアル要素を組み込んだ豊かで文脈に即した説明、ストーリー、または説明を生成することができます。これは、マーケティング、エンターテイメント、教育など、さまざまな目的のコンテンツを作成するために役立ちます。 ビジュアル言語モデルの主なタスクには、ビジュアルクエスチョンアンサリングと画像キャプションがあります。ビジュアルクエスチョンアンサリングでは、AIモデルに画像とその画像に関するテキストベースの質問が提示されます。モデルはまずコンピュータビジョンの技術を使用して画像の内容を理解し、NLPを使用してテキストの質問を処理します。回答は理想的には画像の内容を反映し、質問に含まれる特定のクエリに対応する必要があります。一方、画像キャプションでは、画像の内容を説明する記述的なテキストキャプションや文を自動生成することが含まれます。 現在のビジュアル言語モデルは、一般的なオブジェクトの物質の種類や壊れやすさなどの物理的な概念を捉えることを改善する必要があります。これにより、物体の物理的な推論を必要とするロボットの識別タスクが非常に困難になります。この問題を解決するために、スタンフォード大学、プリンストン大学、Google DeepMindの研究者らはPhysObjectsを提案しています。これは、一般的な家庭用品の36.9Kのクラウドソースおよび417Kの自動物理的概念アノテーションのオブジェクト中心のデータセットです。クラウドソースのアノテーションは、分散グループの個人を使用して大量のデータを収集し、ラベル付けする方法です。 彼らは、PhysObjectsでファインチューンされたVLMが物理的な推論能力を大幅に向上させることを示しました。物理的に基礎づけられたVLMは、保持データセットの例において予測精度が向上しています。彼らはこの物理的に基礎づけられたVLMをLLMベースのロボットプランナーと組み合わせてその利点をテストしました。LLMはシーン内のオブジェクトの物理的な概念についてVLMにクエリを行います。 研究者は、EgoObjectsデータセットを画像ソースとして使用しました。これは、PhysObjectsを構築する際に公開された最大の実オブジェクト中心のデータセットでした。リアルな家庭の配置のビデオで構成されているため、家庭用ロボティクスのトレーニングに関連しています。平均して、117,424枚の画像、225,466個のオブジェクト、4,203個のオブジェクトインスタンスIDが含まれています。 彼らの結果は、物理的に基礎づけられたVLMを使用しないベースラインと比較して、物理的な推論を必要とするタスクの計画パフォーマンスが向上したことを示しています。彼らの今後の研究では、幾何学的な推論や社会的な推論など、物理的な推論を超えて拡大する予定です。彼らの手法とデータセットは、VLMを用いたより洗練された推論のための第一歩です。

どのようにして、どんなチームサイズにも適したデータサイエンスの戦略を構築するか
「多くの自由と少ない指示で「データサイエンスの戦略を構築してください」という依頼を受けたデータサイエンスのリーダーであるならば、この記事はあなたの助けになるでしょう以下をカバーします:その間、私たちは借用します...」

数学者たちは、三体問題に対して12,000の解を見つけました
「数学者たちは、アイザック・ニュートンの運動の法則、いわゆる三体問題によって許容される3つの物体の安定した軌道配置として、12,392個の新しい軌道配置を特定しました」

「ニューロン、ホタル、そしてナットブッシュを踊ることには何の共通点があるのでしょうか?」
コンピュータ科学者や数学者は、同期現象を評価するためのフレームワークを設計しました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.