Learn more about Search Results A - Page 657

- You may be interested
- 高パフォーマンスなリアルタイムデータモ...
- Google AIは、オーディオ、ビデオ、テキス...
- パスワードを使用したGit認証の非推奨化
- 3Dアーティストのヌルハン・イスマイルは...
- QLoRAを使用して、Amazon SageMaker Studi...
- 「セマンティック-SAMに会ってください:...
- 「AIセキュリティへの6つのステップ」
- 「トランスフォーマーとサポートベクター...
- 「NYUの研究者たちはゲノミクスのためのニ...
- 「Pythonでリンゴとオレンジを比較する」
- 「GPU インスタンスに裏打ちされた SageMa...
- インデータベース分析:SQLの解析関数の活用
- パフォーマンスの向上と最適化されたリソ...
- より一般化されたAIツールを使用してコン...
- 「GPT-4を超えて 新機能は何ですか?」
「社会教育指数は学校卒業者の結果にどのような影響を与えるのか? – Rとbrmsを用いたベイズ分析」
前回の記事が非常に好評を得たため、学校の部門と大学進学後の結果の間に比例的な違いがあるかを理解しようとするこの記事の続きをご紹介します

「密度プロンプトのチェーンを通じたGPT-4要約の強化」
大規模言語モデル(LLMs)は、その優れた能力のために最近注目を集めています。LLMsは、質問応答やコンテンツ生成から言語翻訳やテキスト要約まで、あらゆることが可能です。自動要約の最近の進展は、ラベル付きのデータセットでの教師あり微調整から、OpenAI開発のGPT-4のような大規模言語モデルのゼロショットプロンプティングを利用した戦略の変更に大いに貢献しています。この変更により、追加のトレーニングを必要とせずに、長さ、テーマ、スタイルなど、さまざまな要約の特性をカスタマイズするための慎重なプロンプティングが可能となります。 自動要約では、要約に含める情報の量を決定することは困難な課題です。優れた要約は、包括性とエンティティ中心性のバランスを慎重に取りながら、読者にとって混乱を招く可能性のある過度に密な言語を避けるべきです。最近の研究では、一連の研究者が、トレードオフをよりよく理解するために、よく知られたGPT-4を使用してChain of Density(CoD)プロンプトを使用して要約を作成する研究を行いました。 この研究の主な目標は、GPT-4によって生成された要約の一連のバージョンのうち、ますます密度の高いものに対する人間の好みを収集することで、限界を見つけることでした。CoDプロンプトはいくつかのステップで構成され、GPT-4は最初に一部のリスト化されたエンティティを含む要約を生成しました。そして、欠落している重要な要素を含めることで要約を徐々に長くしました。従来のGPT-4プロンプトによって生成された要約と比較して、これらのCoD生成要約は、抽象化の向上、情報の統合、つまり情報の融合のより高いレベル、およびソーステキストの始まりに対するバイアスの減少という特徴を持っていました。 人間の好みの研究にはCNN DailyMailから100のアイテムが使用され、CoDプロンプトによって生成された要約の効果を評価しました。研究の結果、CoDプロンプトで生成されたGPT-4の要約は、バニラプロンプトで生成される要約よりも密度が高く、人間が書いた要約の密度に近づいているため、人間の評価者によって好まれました。これは、要約の中の情報量と読みやすさの理想的なバランスを達成することが重要であることを意味しています。研究者はまた、人間の好みの研究に加えて、5,000の未注釈のCoD要約を公開しました。これらの要約はすべて、HuggingFaceのウェブサイトで一般に利用できます。 チームは次のように主要な貢献をまとめています。 Chain of Density(CoD)メソッドを導入しました。これは、GPT-4によって生成された要約のエンティティの密度を段階的に向上させる反復的なプロンプトベースの戦略です。 包括的な評価:この研究では、手動および自動評価を含む、ますます密度の高いCoD要約を徹底的に評価しています。この評価では、エンティティの数を減らし、要約の明瞭さと情報量を重視することで、2つのバランスの微妙な関係を理解しようとしています。 オープンソースのリソース:この研究では、5,000の未注釈のCoD要約、注釈、およびGPT-4によって生成された要約へのオープンソースのアクセスを提供しています。これらのツールは、分析、評価、または教育のために利用できるようになっており、自動要約部門の持続的な開発を促進しています。 結論として、この研究は、人間の好みによって決定される自動要約のコンパクトさと情報量の理想的なバランスを強調し、自動要約プロセスが人間が生成した要約の密度に近いレベルを達成することが望ましいと主張しています。

「ロボットに対するより柔らかいアプローチ」
「ソフトロボットは研究室から現実世界へと移行しています」

「3Dプリントされた『生物性材料』が汚染された水を浄化することができる」
カリフォルニア大学サンディエゴ校の科学者たちは、「エンジニアリングされた生体材料」を作り出し、水中の汚染物質を除去するためのものです

「研究者たちが、数千の変形可能な結び目を発見」
研究者は、ランダムな空間サンプリングと物理モデリングを組み合わせた計算パイプラインを通じて、数千の新しい変形可能な結び目を発見しました

「マイクロソフトに韻を踏む事件」
「マイクロソフト事件の教訓として、反トラスト弁護士たちは、ワシントンからの監視がなんら重大なペナルティがなかったとしても、企業の成長を遅らせることがあると指摘しています」
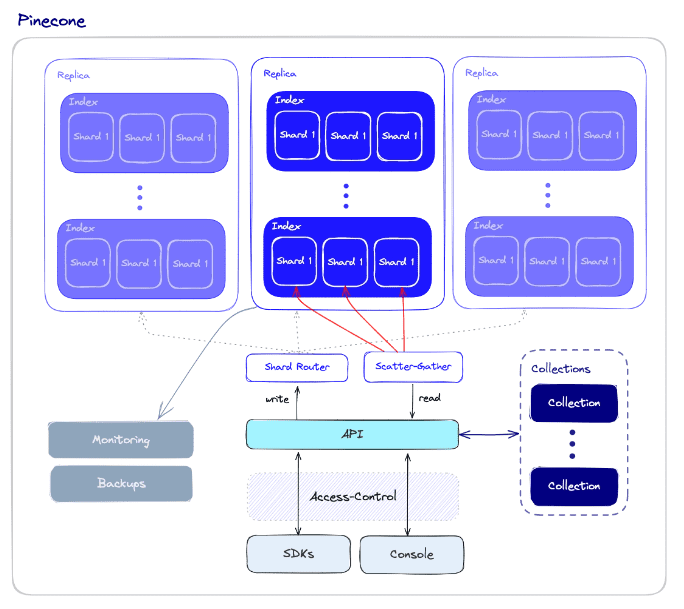
「パインコーンベクトルデータベースの包括的なガイド」
このブログでは、ベクトルデータベース、具体的にはパイナコーンベクトルデータベースについて説明しますベクトルデータベースは、特徴や属性を表す数学的ベクトルとしてデータを格納するタイプのデータベースですこれらのベクトルは複数の次元を持ち、複雑なデータの関係を捉えますこれにより、類似性や距離の計算を効率的に行うことができ、タスクに役立ちます...

「私たちはデータサイエンスシステムを仮想化すべきでしょうか – それともしないべきでしょうか?」
「ビッグデータ」を活用することが、あらゆる産業における問題解決にますます重要になるにつれて、ホームラボやデータレイクのようなデータリポジトリは、より並列化された計算能力を必要とします
ベクトルデータベース:それは何か、そしてなぜそんなに話題なのか?
「過去数ヶ月間、ベクトルデータベースは注目を浴びており、10以上の企業がベクトルデータベースアーキテクチャのいくつかの種類を提供していますなぜそんなに多くの種類が存在するのでしょうか?ベクトルとは何でしょうか…」

「プロンプトエンジニアであるということの体験」
「プロンプトエンジニアは、大規模な言語モデルまたはLLM(Large Language Models)のコードの開発とメンテナンスを担当していますほとんどの人がChatGPTについて知っているかもしれませんが、LLMは急速にさまざまな産業に展開され、ドメイン固有のトレーニングが行われているため、彼らは人間の効果的なツールになることが期待されています...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.