Learn more about Search Results リポジトリ - Page 64

- You may be interested
- なぜ私たちはニューラルネットワークを持...
- アルゴリズムのバイアスの理解:タイプ、...
- Sudowriteのレビュー:AIが人間らしい小説...
- Apple AirTagsは失われたスーツケースを追...
- 「LLMを使用して、会話型のFAQ機能を搭載...
- パーキンソン病を抱える男性が、脊髄イン...
- AIの進歩を促進するための医療データのラ...
- 「TR0Nに会ってください:事前学習済み生...
- デブセコプス:セキュリティをデブオプス...
- データロボットとAWS Hackathon 2023でGen...
- Google AI Researchは、大規模言語モデル...
- 「ジェネレーティブAI(2024)の10の重要...
- Googleの安全なAIフレームワークを紹介します
- フィリップスは、Amazon SageMakerをベー...
- 「プロンプトエンジニアリングの興亡:一...

AWS Inferentia2を使用して、安定したディフュージョンのパフォーマンスを最大化し、推論コストを低減します
生成型AIモデルは、最近の数ヶ月間で急速に成長しており、リアルなテキスト、画像、コード、音声の作成能力において印象的な能力を持っていますこれらのモデルの中でも、Stable Diffusionモデルは、テキストのプロンプトに基づいて高品質な画像を作成するというユニークな強みを持っていますStable Diffusionは、[…]を含む様々な高品質な画像を生成することができます

AI ポリシー @🤗 EU AI Act におけるオープンな機械学習の考慮事項
機械学習の皆様と同様に、Hugging FaceでもEU AI Actに注目しています。これは画期的な法律であり、民主的な要素がAI技術開発との相互作用をどのように形成するかを世界中に広めるものです。また、社会のさまざまな要素を代表する組織との広範な協議と作業の結果でもあります。私たちはコミュニティ主導の企業として、このプロセスに特に敏感に取り組んでいます。このポジションペーパーでは、Creative Commons、Eleuther AI、GitHub、LAION、Open Futureとの連携により、オープンなML開発の必要性が法律の目標をサポートする方法についての私たちの経験を共有し、逆に、規制がオープンでモジュラーで協力的なML開発のニーズをより適切に考慮するための具体的な方法を示すことを目指しています。 Hugging Faceは、開発者コミュニティのおかげで今日の地位にあります。そのため、オープンな開発がもたらす効果を直接目にしてきました。より堅牢なイノベーションをサポートし、より多様でコンテキストに応じたユースケースを可能にする場所です。開発者は革新的な新しい技術を簡単に共有し、自分のニーズに合わせてMLコンポーネントを組み合わせ、スタック全体について完全な可視性を持って信頼性のある作業ができます。また、技術の透明性がより責任ある取り組みと包括性をサポートする上での必要な役割にも痛感しており、MLアーティファクトの文書化とアクセシビリティの改善、教育活動、大規模な多学科のコラボレーションのホスティングなどを通じてこれを促進してきました。そのため、EU AI Actが最終段階に向かうにつれて、MLシステムのオープンかつオープンソースな開発の特定のニーズと強みを考慮することが、その長期的な目標をサポートする上で重要になると考えています。共同署名したパートナー組織と共に、以下の5つの推奨事項を提案します: AIコンポーネントを明確に定義すること オープンソースのAIコンポーネントの共同開発とパブリックリポジトリでの公開は、開発者をAI Actの要件の対象としないことを明確にすること(パーラメントの文章のRecitals 12a-cとArticle 2(5e)を基に改善すること) AIオフィスの調整と包括的なガバナンスをオープンソースエコシステムと連携させること(パーラメントの文章を基に改善すること) 研究開発の例外が実用的かつ効果的であることを確保すること。現実世界の条件での限定的なテストを許可し、理事会の取り組みの一部とパーラメントのArticle 2(5d)の改訂版を組み合わせること 「基礎モデル」に対して比例の要件を設定すること。異なる使用方法と開発モダリティを明確に区別し、オープンソースアプローチを含めること。パーラメントのArticle 28bを適用すること これらについての詳細と文脈は、こちらの全文をご覧ください!

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…
グローバルデータバロメーター:世界のオープンデータの現状はどうなっていますか?
「最近、世界中の都市でオープンデータの政策採用に関する本を読みましたその本は『Beyond Transparency』というタイトルで、こちらのリンクで公開されていますこの本には、事例研究が含まれており、…」
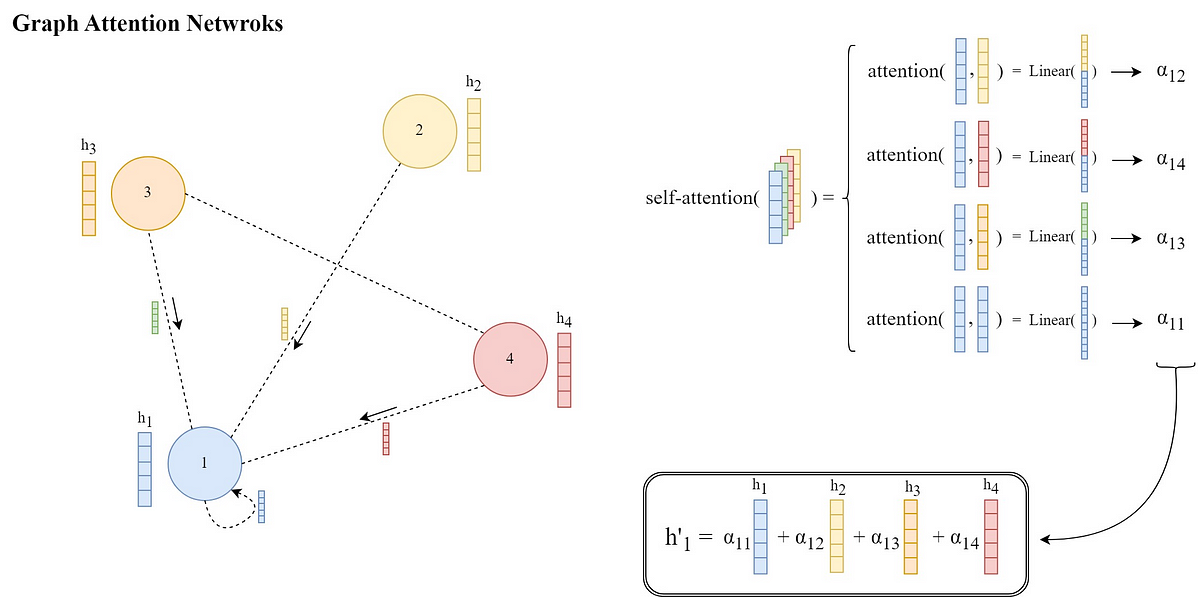
「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
グラフニューラルネットワーク(GNN)は、グラフ構造のデータに作用する強力なニューラルネットワークの一種ですノードのローカルな情報を集約することによって、ノードの表現(埋め込み)を学習します...
CleanLabを使用してデータセットのラベルエラーを自動的に検出する
数週間前、私は個人のプロジェクトを開発するためのデータセットを通常の検索している最中に、ブラジル下院オープンデータポータルに出会いましたこのポータルには多くのデータが含まれています

「OpenAIがオープンソースのGPTモデルのリリースを予告」
人工知能の先駆的な存在であるOpenAIは、オープンソースのGPTモデルを公開する可能性によってテックコミュニティで話題となっています。公式な発表はまだされていませんが、OpenAIの重要な人物であるAndrej Karpathy氏は、GPT-3.5を一般に公開する可能性について示唆しています。この記事では、この潜在的なリリースの興奮を取り上げ、その開発と意義について掘り下げます。 また読む: OpenAIがGPT-4にアクセスを提供 OpenAIの計画の一部を覗いてみる Llama実験に関する話題の中で、OpenAIの重要な人物であるAndrej Karpathy氏は、モデルの重みの公開が近い将来に行われるかもしれないと示唆しました。会社はまだ何も確認していませんが、この議論はテックコミュニティの間でかなりの興奮を引き起こしています。 OpenAIの潜在的なオープンソースの試み ディープラーニングの専門家として知られるAndrej Karpathy氏は、GPT-3.5モデルがオープンソースのプロジェクトとして公開されるかもしれないと示唆しました。この動きは、高度なAI技術の利用可能性と民主化に大きな影響を与える可能性があります。OpenAIのオープンソース計画に関する憶測は、ユーザーがKarpathy氏に対してTwitterのスレッドで、なぜ彼がLlama 2を使って実験しているのか、OpenAIのためにJarvisを構築するのではないかと尋ねたことから始まりました。Karpathy氏の興味深い回答が、GPT-3.5の潜在的なオープンソース化についての好奇心を引き起こしました。 また読む: Metaが有望なプロジェクトをすべてオープンソース化 | その理由を知る Baby Llamaが注目を集める 最近リリースされたBaby Llama(またはllama.cとも呼ばれる)は、テック愛好家の注目を集めました。MetaのLlama 2に触発されて大規模な言語モデル(LLM)を単一のコンピュータ上で実行するKarpathy氏の実験は、GPT-3.5の未来についての憶測をさらに盛り上げました。 また読む: OpenAIがBaby Llamaを開発 –…

「ショートGPTと出会おう:コンテンツ作成の自動化とビデオ制作プロセスの効率化のためのパワフルなAIフレームワーク」
デジタルコンテンツ制作のスピードが速い世界では、効率性と創造性が重要です。ShortGPTは、コンテンツ制作を自動化し、ビデオ制作プロセスを効率化するために設計された堅牢なフレームワークです。Large Language Models(LLMs)と最先端の技術を活用し、ShortGPTはビデオ制作、映像ソーシング、音声合成、編集タスクを前例のない簡易化します。 自動編集フレームワーク ShortGPTの中核には、革新的なLLM指向のビデオ編集言語があります。この言語は、編集プロセスを管理可能かつカスタマイズ可能なブロックに分解し、Large Language Modelsが理解できるようにします。これにより、ShortGPTはさまざまな自動編集プロセスのスクリプトとプロンプトを効率的に生成し、クリエイターに即座に使用できるリソースを提供します。 マルチ言語の音声合成とコンテンツ制作 ShortGPTは、複数の言語をサポートするように設計されており、コンテンツクリエーターがグローバルにアクセスできるようにしています。ShortGPTの音声合成機能により、クリエーターは好みの言語でコンテンツを提供し、言語の壁を乗り越えて世界中の多様な観客に届けることができます。対応言語には、英語、スペイン語、アラビア語、フランス語、ポーランド語、ドイツ語、イタリア語、ポルトガル語などがあります。 自動字幕生成とアセットソーシング 字幕はビデオコンテンツの重要な要素であり、アクセシビリティとエンゲージメントを高めます。ShortGPTの自動字幕生成機能により、クリエーターは簡単にビデオに字幕を追加でき、時間と労力を節約することができます。さらに、ShortGPTはインターネットから画像や映像素材を取得し、WebとPexels APIを通じて高品質な視覚素材の広範なライブラリにアクセスします。この機能により、関連するアセットを見つけるプロセスが簡素化され、コンテンツ制作のワークフローがさらに迅速化されます。 メモリと永続性によるシームレスな編集 ShortGPTは、軽量なデータベースであるTinyDBを使用して、自動編集変数の長期的な永続性を確保します。この機能により、フレームワークはユーザーの好みや設定を記憶し、複数のセッションでシームレスかつ一貫した編集体験を提供します。 Google Colabでの簡単な実装 ShortGPTは、ローカルシステムに必要なプレリクイジットをインストールする必要がない、Google Colabノートブックのオプションを提供しています。このWebベースのインタフェースは無料で利用でき、インストール要件なしでShortGPTを実行できるようにします。 インストール手順とAPIの統合 ShortGPTの詳細なインストールガイドでは、ImageMagick、FFmpegのセットアップ手順やリポジトリのクローンについてのステップバイステップの手順が提供されています。さらに、フレームワークはOpenAIとElevenLabsのAPIと統合されており、タスクのスムーズな自動化のためにユーザーがAPIキーを入力する必要があります。 カスタマイズ可能かつ柔軟 ShortGPTの柔軟性は、ContentShortEngine、ContentVideoEngine、Automated EditingEngineなどのさまざまなエンジンを通じて発揮されます。クリエーターは、短いビデオや長いコンテンツを作成するか、カスタマイズ可能な編集オプションが必要かに応じて、最適なエンジンを選択することができます。 オープンソースで進化中…

個別のデータサイエンスのロードマップを作成する方法
はじめに 現在のデータ駆動の世界では、多くの人々がデータサイエンスのキャリアを選びますが、進め方がわかりません。キャリアの成功を保証してくれるのはどのキャリアパスでしょうか?パーソナライズされたデータサイエンスのロードマップが答えです! データサイエンスは、その分野の多様性と異なるキャリアパスの存在から、個別のキャリアロードマップが重要です。データサイエンスは、プログラミングや統計分析から機械学習やドメイン特化の専門知識まで、さまざまなスキルを必要とします。各データサイエンティストは、独自の強み、興味、キャリアの目標を持っており、一つのアプローチでは不十分です。この記事では、パーソナライズされたデータサイエンスのロードマップの重要性について説明します! データサイエンスのロードマップの必要性 データサイエンスは、学際的で広範な分野です。機械学習、データエンジニアリング、統計学、データ分析など、さまざまな分野が含まれています。これらを一つずつ学ぶだけでなく、時間の無駄です。データサイエンスのロードマップは、以下の利点を提供することで、候補者がスムーズにキャリアを進めるのに役立ちます: 方向性の明確化:学習と仕事の段階ごとに学ぶべきスキルや知識を決定するのに役立ちます。 効率的な学習:特定のトピックから学習の旅を始めるように指示し、試行錯誤を回避します。 目標設定:データサイエンティストのロードマップは、自分の分野に重要な目標を設定するのに役立ちます。 専門化:ビジネスアナリスト、データアナリスト、エンジニア、機械学習エンジニアなど、各職業についての情報を提供することで、キャリアパスの選択を容易にします。 パーソナライズされたデータサイエンスのロードマップとは? データサイエンスのロードマップは、個々の人々がデータサイエンスのキャリアを進めるための計画やガイドです。データサイエンスの広範さを考慮すると、データサイエンスのロードマップは、キャリアの選択、スキル、興味、バックグラウンド、インスピレーションに応じて個別に異なります。これにより、キャリアの目標を達成するために最も適したパスを選択することができ、より迅速で邪魔のない学習の旅につながります。データサイエンスのコースやスキルを選ぶ際に、ロードマップを手に入れることは、以下の理由から初めのステップであるべきです: データサイエンスのロードマップは、個々の強みと弱点に焦点を当てて、スキルと専門知識を構築します。 明確かつ現実的な目標を設定し、構造化されたアプローチを提供します。長期目標を短期目標に分割して簡単に達成し、達成感を得ることができます。 データサイエンスの特定のキャリアに適応するのに役立ちます。選択した分野のすべてのコンポーネントを学習に含みます。 インターネット上には圧倒的な情報がありますが、ロードマップはそれをフィルタリングして時間とリソースを節約します。スキルの実践的な応用に焦点を当てることで、仕事の獲得の可能性が高まります。 成功するデータサイエンスのロードマップを解き放つ! 以下の手順に従うことで、データサイエンスの夢のキャリアに向けて確実なプロセスを進めることができます: 機械学習のスキルを開発する データサイエンスでは、機械学習のスキルが重要です。データセットからの探索的データ分析やデータクリーニングにより、データの要約とエラーの除去が行われます。特徴選択とエンジニアリングによるデータの抽出の学習は、機械学習アルゴリズムのパフォーマンス向上に役立ちます。重要な一般的なモデルには、線形回帰、ロジスティック回帰、決定木、K最近傍法、ナイーブベイズ、K-means、勾配ブースティングマシン、XGBOOST、サポートベクターマシン(SVM)などがあります。これらの目的、機能、応用は、データサイエンスのプロジェクトにおいて異なります。 また、読んでみてください:トップ20の機械学習プロジェクト 問題解決スキルの開発 データサイエンスの仕事では、複雑なデータセットを分析する必要があります。革新的で費用対効果の高い解決策が必要な問題が数多く発生します。また、データの探索、モデルの選択、ハイパーパラメータのチューニング、モデルのパフォーマンスの最適化など、問題解決スキルが必要なタスクもあります。これらのスキルにより、創造性と洗練されたアプローチで課題に取り組むことができます。 ハッカソンとプロジェクトに取り組む ハッカソンやプロジェクトは、選んだ分野の実世界のシナリオでの実践的な経験を提供します。最新のトレンドや必要なスキルについて学ぶことで、特定のドメインの専門知識を持つポートフォリオを構築する機会があります。また、スキルを学習し適用するための自律性と適応能力を示すこともできます。…

「AWSは責任ある生成AIへの取り組みを再確認する」
人工知能(AI)や機械学習の先駆者として、AWSは責任を持って生成的AIの開発と展開に取り組んでいます生成的AIは、私たちの時代で最も革新的なイノベーションの一つであり、世界の想像力を捉え続けています私たちは引き続き、責任を持ってそれを活用することに全力を注いでいます専門の責任あるAIチームを持ち、[…]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.