Learn more about Search Results モード - Page 64

- You may be interested
- 「包括的な革新:Amazon SageMakerでのHac...
- 「共通テーブル式を使ってSQLロジックを向...
- 大規模言語モデル、MirrorBERT — モデルを...
- 「クルーズ、サンフランシスコでの自動運...
- 「Databricks、MosaicMLおよびその他の最...
- Q-Learningの紹介 パート2/2
- AIと自動化
- 「LanguageChainを使用して大規模言語モデ...
- 重要なデータサイエンスのスキルを習得す...
- 「研究者がドメイン固有の科学チャットボ...
- 「Giskard の紹介 AI モデルのためのオー...
- 新しいAI論文で、CMUとGoogleの研究者が言...
- 「ハイブリッド検索を用いたRAGパイプライ...
- 「Pydeckでフラットマップにさようならを...
- 「このAI論文は、超人的な数学システムの...

マイクロソフトは、奇妙な新しい粒子が量子コンピュータを改善する可能性があると発表しています
マイクロソフトの研究者たちは、Majoranaゼロモードと呼ばれる難捉える準粒子を作成したと発表していますが、企業外の科学者たちは懐疑的です

エンジニアリングリーダーは何を気にしているのか?
私たちのエンジニアリングリーダーズフォーラム ラウンドテーブルのまとめと、VPたちがAI、ChatGPT、リモートワーク、DORAメトリックス、およびRIFについて考えていること
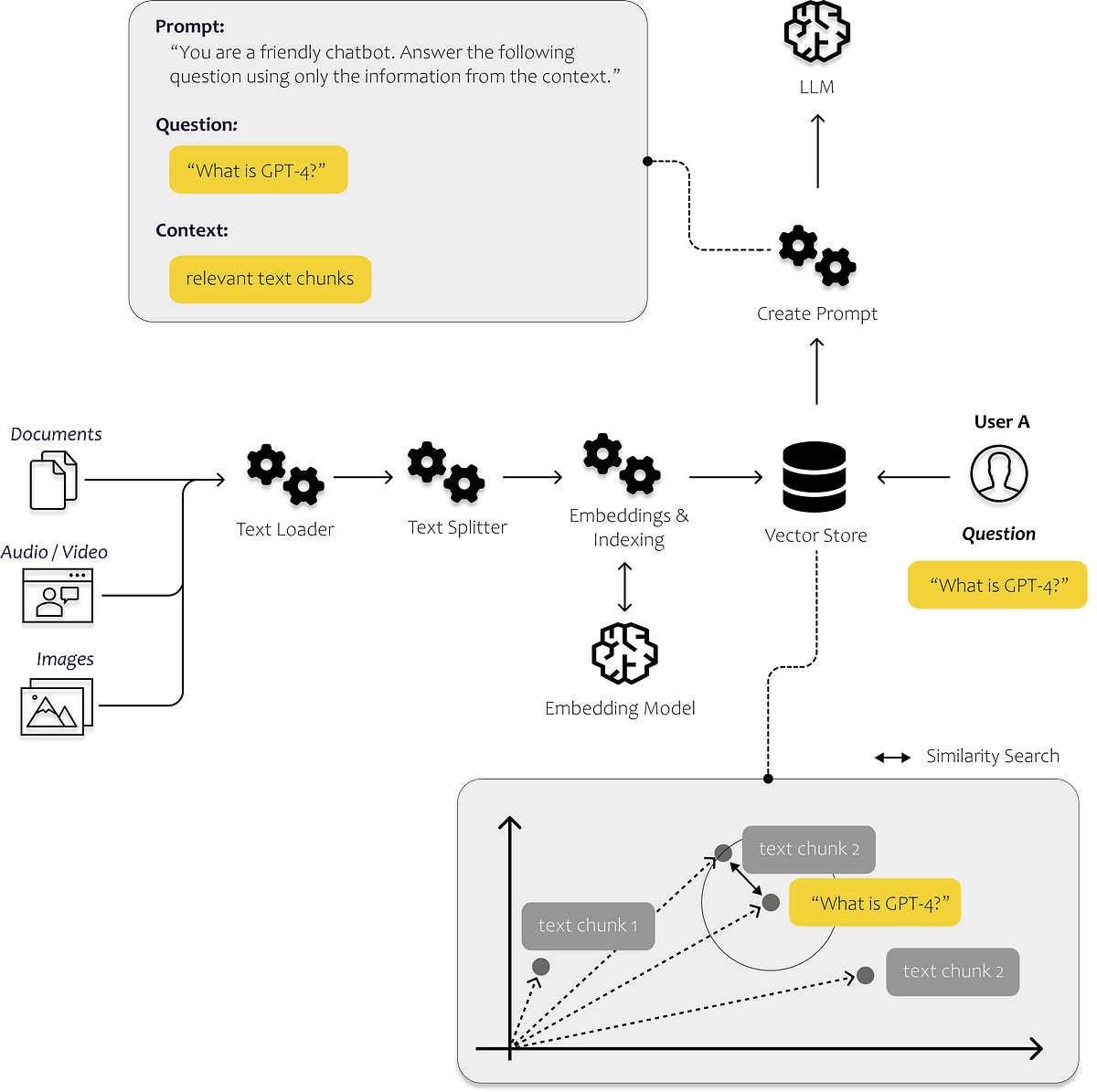
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

AIの仕事を見つけるための最高のプラットフォーム
あなたのキャリアの目標、好みの仕事スタイル、およびAIの専門分野に依存するAIの仕事に最適なプラットフォームについてもっと学びましょう

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。
METAのHiera:複雑さを減らして精度を高める
畳み込みニューラルネットワークは、20年以上にわたってコンピュータビジョンの分野を支配してきましたトランスフォーマーの登場により、それらは放棄されると考えられていましたしかし、多くの実践者は…

データアナリストは良いキャリアですか?
労働統計局(BLS)によると、データアナリストを含む研究アナリストの雇用は、2021年から2031年までに23%増加すると予想されています。データ分析のキャリアが著しく成長することは、有望な候補者にとっても重要な展望を示しています。それは一般に提供されるサービスや製品に深い影響を与えます。データアナリストとして、コンピュータサイエンス、統計学、数学の技術的な知識と問題解決能力および分析能力を持つ必要があります。この分野は、最先端のテクノロジーを使用する機会が豊富であり、個人的および職業的な成長のための機会を提供します。しかし、この興味深いキャリアパスには、どのような期待が置かれているのでしょうか。企業にデータ分析サービスを提供する理想的な候補者に課せられる期待について探ってみましょう。 データアナリストとは何ですか? データ分析とは、ビジネスの利益に活用するために、データから情報を得ることまたは分析することを指します。この仕事の役割と責任には、以下が含まれます。 分析のためのデータ収集。これには、さまざまな方法を通じてさまざまなタイプのデータを発見または収集することが含まれます。例としては、調査、投票、アンケート、およびウェブサイトの訪問者特性の追跡が挙げられます。必要に応じて、データセットを購入することもできます。 プログラミング言語を使用して、前のステップで生成されたデータ、つまり生データをクリーニングすることが必要です。名前は、処理が必要な外れ値、エラー、重複などの不要な情報の存在を示しています。クリーニングプロセスは、データの品質を向上させて利用可能にすることを目的としています。 データは、今後モデル化する必要があります。これには、データに構造と表現を与えて整理することが含まれます。また、データの分類およびその他の関連プロセスを行うことも必要です。 したがって、形成されたデータは複数の目的に役立ちます。使用法は問題文によって異なり、解釈方法も問題文によって異なります。データの解釈は主に、データ内のトレンドやパターンを見つけることに関係しています。 データのプレゼンテーションも同様に重要なタスクであり、情報が意図した通りに閲覧者や関係者に届くようにすることが最も重要な要件です。これには、プレゼンテーションおよびコミュニケーションスキルが必要です。データアナリストは、グラフやチャートを使用し、報告書の作成や情報のプレゼンテーションを行うことがあります。 データアナリストになる理由 データアナリストになるためには、複数の理由があります。以下は、最も重要な5つの理由です。 高い需要: データの生成が増加したことにより、未処理のデータが大量に存在しています。それには、企業が活用できる多くの秘密が含まれます。このタスクを実行できる個人の要件は急速に増加しており、標準的な要件は年間3000ポジションです。 ダイナミックなフィールド: データアナリストの仕事は、課題に対処し、問題を解決することに喜びを感じる場合、多くのものを提供します。毎日興味深く、新しい課題があり、分析思考とブレストストーミングが必要な場所です。また、旅の中で多くを学ぶこともでき、自己改善に貢献します。 高い報酬: データアナリストのポジションの報酬は高く、キャリアを追求する価値があります。給与の増加は、業界によって異なり、一部の分野ではボーナスを含む高い収入が約束されています。 普遍性: データアナリストの要件は、特定の分野に限定されるものではありません。すべての業界が多くのデータを生成し、情報に基づく論理的な意思決定が必要です。したがって、背景や興味に関係なく、すべての専門分野に開かれています。 キャリアの選択をリード: 熟練したデータアナリストは、ポジションと会社に価値をもたらすことができます。成長、昇進、追加の福利厚生の可能性はどこでも開かれています。グループをリードしたり、教えたり、競争したり、ワークフォースの文化を形成することができるように、キャリアの選択をリードすることができます。 需要と将来の仕事のトレンド 現在、データアナリストの需要は高く、良い報酬が期待できます。現在のデータ生成の速度に基づいて、将来的には需要がさらに高まると予想されています。新しいテクノロジーの生成とデータ収集の容易化により、将来的には才能に新しい機会が提供されるでしょう。将来のデータアナリストの予想される新しいジョブロールには、以下が含まれます。 AIの機能性と適合性を説明する。新しく開発された機能の品質分析。 ビジネスオペレーションとデータ処理のリアルタイム分析の組み合わせに取り組む。これにより、戦略に基づいた計画に向けて導かれます。…

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…

現代のデータエンジニアリングにおいてMAGE:効率的なデータ処理を可能にする
イントロダクション 今日のデータ駆動型の世界では、あらゆる業界の組織が膨大なデータ、複雑なパイプライン、そして効率的なデータ処理の必要性に直面しています。Apache Airflowなどの従来のデータエンジニアリングソリューションは、これらの困難に対処するためにデータ操作をオーケストレーションし、制御することで重要な役割を果たしてきました。しかし、技術の急速な進化により、データエンジニアリングの景観を再構築するMageという新しい競合者が登場しました。 学習目標 第3者のデータをシームレスに統合および同期化すること 変換のためのPython、SQL、およびRによるリアルタイムおよびバッチパイプラインの構築 データ検証で再利用可能かつテスト可能なモジュラーコード 寝ている間に複数のパイプラインを実行、監視、およびオーケストレーションすること クラウド上で協働し、Gitとバージョン管理を行い、利用可能な共有ステージング環境を待つことなくパイプラインをテストすること Terraformテンプレートを介してAWS、GCP、およびAzureなどのクラウドプロバイダーでの高速な展開 データウェアハウスで非常に大きなデータセットを直接変換するか、Sparkとのネイティブ統合を介して変換すること 直感的なUIを介して組み込みの監視、アラート、および観測性 まるで腕木式に簡単でしょうか?それならMageを絶対に試してみるべきです! この記事では、Mageの機能と機能性について説明し、これまでに学んだことやそれを使用して構築した最初のパイプラインを強調します。 この記事はData Science Blogathonの一部として公開されました。 Mageとは何ですか? Mageは、AIによって駆動され、機械学習モデル上に構築された現代的なデータオーケストレーションツールであり、かつてないほどのデータエンジニアリングプロセスを効率化し最適化することを目的としています。これは、データ変換と統合のための効果的でありながら簡単なオープンソースデータパイプラインツールであり、Airflowのような確立されたツールに対して強力な代替手段となる可能性があります。自動化と知能の力を組み合わせることで、Mageはデータ処理ワークフローを革新し、データの取り扱いと処理の方法を変革しています。Mageは、その無比の機能と使いやすいインターフェイスにより、これまでにないデータエンジニアリングプロセスの簡素化と最適化を目指しています。 ステップ1:クイックインストール Mageは、Docker、pip、およびcondaコマンドを使用してインストールでき、またはクラウドサービス上で仮想マシンとしてホストできます。 Dockerを使用する #Dockerを使用してMageをインストールするコマンドライン >docker…
PyTorchモデルのパフォーマンス分析と最適化—Part2
これは、GPU上で実行されるPyTorchモデルの分析と最適化に関する一連の投稿の第二部です最初の投稿では、プロセスとその重要な可能性を示しました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.