Learn more about Search Results メール - Page 64

- You may be interested
- 「Auto-GPT&GPT-Engineer:今日の主要なA...
- このAI論文では、ディープラーニングモデ...
- モジラのコモンボイスでの音声言語認識 — ...
- 「データと分析について非データの人々と...
- 水中ロボットが科学者に南極の氷の融解を...
- Loguru プリントのようにシンプル、ログの...
- 「特異値分解(SVD)を解説」
- 「スローリー・チェンジング・ディメンシ...
- DSPyの内部:知っておく必要のある新しい...
- 私の博士号入学への道 – 人工知能
- 「二つの頭を持つ分類器の使用例」
- 研究者たちは、より優れた熱管理のために...
- Google Cloud上のサーバーレストランスフ...
- Google AI研究のTranslatotron 3:革新的...
- 機械学習モデルの説明可能性:AIシステム...
私の博士号入学への道 – 人工知能
大学の出願書類を取り組んで、日々をカウントダウンして過ごした6ヶ月間の後、2023年秋に人工知能の博士号を取得することになりました以下の内容をまとめてみました…
チャットGPTの潜在能力を引き出すためのプロンプトエンジニアリングのマスタリング
プロンプトエンジニアリングは、ChatGPTやその他の大規模言語モデルのおかげで、風のように私たちの生活の一部にすぐになりました完全に新しい分野ではありませんが、現在...

GPTとBERT:どちらが優れているのか?
生成AIの人気の高まりに伴い、大規模言語モデルの数も増加していますこの記事では、GPTとBERTの2つのモデルを比較しますGPT(Generative...

このAI論文は、自律走行車のデータセットを対象とし、コンピュータビジョンモデルのトレーニングの匿名化の影響を研究しています
画像匿名化とは、プライバシー保護のために画像から機密情報を変更または削除することです。プライバシー規制に準拠するために重要ですが、匿名化はしばしばデータ品質を低下させ、コンピュータビジョンの開発を妨げます。データ劣化、プライバシーとユーティリティのバランス、効率的なアルゴリズムの作成、モラルと法的問題の調整など、いくつかの課題が存在します。プライバシーを確保しながらコンピュータビジョンの研究とアプリケーションを改善するために、適切な妥協点を見つける必要があります。 画像の匿名化に関する以前のアプローチには、ぼかし、マスキング、暗号化、クラスタリングなどの従来の方法が含まれています。最近の研究では、生成モデルを使用してアイデンティティを置き換えることにより、現実的な匿名化に焦点が当てられています。しかし、多くの方法には匿名性の正式な保証がなく、画像の他の手がかりでアイデンティティが明らかになることがあります。さまざまな影響を持つタスクによって、コンピュータビジョンモデルに与える影響を探究した限られた研究が行われています。公開された匿名化されたデータセットはまれです。 最近の研究では、ノルウェー科学技術大学の研究者が、自律型車両の文脈での重要なコンピュータビジョンタスク、特にインスタンスセグメンテーションおよび人物姿勢推定に注目しました。彼らはDeepPrivacy2に実装されたフルボディと顔の匿名化モデルの性能を評価し、現実的な匿名化アプローチと従来の方法の効果を比較することを目的としました。 記事で評価された匿名化の影響を評価するために提案された手順は次のとおりです。 一般的なコンピュータビジョンデータセットの匿名化。 匿名化されたデータを使用してさまざまなモデルをトレーニングする。 元の検証データセットでモデルを評価する。 著者らは、ぼかし、マスクアウト、現実的な匿名化の3つのフルボディと顔の匿名化テクニックを提案しています。インスタンスセグメンテーション注釈に基づいて匿名化領域を定義します。従来の方法にはマスキングアウトとガウスぼかしがあり、現実的な匿名化にはDeepPrivacy2からの事前トレーニング済みモデルが使用されます。著者らはまた、ヒストグラム均等化と潜在最適化を介してフルボディ合成のグローバルコンテキストの問題にも取り組んでいます。 著者らは、COCOポーズ推定、Cityscapesインスタンスセグメンテーション、BDD100Kインスタンスセグメンテーションの3つのデータセットを使用して匿名化されたデータでトレーニングされたモデルを評価する実験を実施しました。顔の匿名化技術はCityscapesとBDD100Kデータセットにおいてほとんど性能に差がありませんでした。しかし、COCOポーズ推定において、マスクアウトとぼかしの両方が人体との相関関係により性能の大幅な低下を引き起こしました。フルボディの匿名化は、従来の方法でも現実的な方法でも、元のデータセットと比較して性能が低下しました。現実的な匿名化はより優れていましたが、キーポイント検出のエラー、合成の制限、グローバルコンテキストの不一致により、結果が低下しました。著者らはまた、モデルサイズの影響を探究し、COCOデータセットの顔の匿名化において、大きなモデルほど性能が低下することがわかりました。フルボディの匿名化においては、標準的および多変量切り捨て法の両方が性能の向上につながりました。 結論として、この研究は、自律型車両のデータセットを使用してコンピュータビジョンモデルをトレーニングする際に匿名化が及ぼす影響を調査しました。顔の匿名化はインスタンスセグメンテーションにほとんど影響を与えず、フルボディの匿名化は性能を大幅に低下させました。現実的な匿名化は従来の方法よりも優れていましたが、本物のデータの完全な代替品ではありません。モデルのパフォーマンスを損なわずにプライバシーを保護することが重要であることが示されました。この研究は注釈に依存しており、モデルアーキテクチャに制限があるため、匿名化技術を改善し、合成の制限に対処するためのさらなる研究が求められています。自律型車両での人物の合成における課題も指摘されました。 論文をチェックしてください。最新のAI研究ニュース、クールなAIプロジェクトなどを共有する、25k以上のML SubReddit、Discordチャンネル、およびメールニュースレターに参加することをお忘れなく。上記の記事に関する質問や、何か見落としていることがある場合は、[email protected]までメールでお問い合わせください。

ExcelとPower BI – 意思決定においてどちらが優れているか?
現代の急速なビジネス環境においては、組織の成功のためには情報をもとにした意思決定が不可欠です。人気のあるビジネスインテリジェンスツールとそのユニークな機能を理解することが、真のポテンシャルを引き出す上で重要です。MS ExcelとPower BIの両方は、データ分析と意思決定に関する印象的な機能を提供しています。ただし、最適な選択を決定するには、具体的な要件に応じて決定する必要があります。この記事では、MS ExcelとPower BIの強みと特定のユースケースについて掘り下げ、ビジネスニーズに合わせてどちらのツールを選択するかをお手伝いします。 MS Excelとは? Microsoft Excelは、データの整理、操作、分析、可視化が可能な強力かつ使いやすいツールです。データ処理、クリーニング、変換などの重要な機能を提供しています。データ分析と可視化には、データ分析ツール、ピボットテーブル、グラフなどの組み込み機能があります。また、Goal Seek、Solver、Decision Trees、Sensitivity analysisなどの機能により、要約されたデータに基づいて情報をもとにした意思決定が可能です。Power PivotやQueryは、データモデリングや変換を容易にすることで、意思決定に重要な役割を果たしています。Excelは、データを分析し、効果的な意思決定を行うための多目的なツールです。 Power BIとは? Power BIは、Excelと同等の性能を持ち、データ変換、意思決定、さまざまなデータソースへの接続、統合、可視化、プレゼンテーションなどの機能を提供するMicrosoftが提供する別の意思決定テーブルです。Power BIには、動的でインタラクティブなレポートやリアルタイムダッシュボードを作成する機能など、独自の特徴があります。また、データモデリング、異なるデータ間の関係の形成、データ内の依存関係の検索なども含まれます。 さらに、Power Queryを介したデータクエリは、直感的なグラフィカルインターフェースを使用して、クリーニング、整形、および変換などのデータ処理アクションを実行する興味深い機能です。Microsoftの製品として、包括的で使いやすいビジネスインテリジェンスツールとしてのコア機能とサービスを提供します。 Excelの最良の機能 1. データの整理に使用できるスプレッドシート ソートおよびフィルタリング:ソートおよびフィルタリング機能を使用して、データを簡単に整理できます。…

AutoML – 機械学習モデルを構築するための No Code ソリューション
はじめに AutoMLは自動機械学習としても知られています。2018年、GoogleはクラウドAutoMLを発表し、大きな関心を集め、機械学習と人工知能の分野で最も重要なツールの1つとなりました。この記事では、「Google Cloud AutoML」を使った機械学習モデルを構築するためのノーコードソリューションである「AutoML」について学びます。 AutoMLは、Google Cloud Platform上のVertex AIの一部です。Vertex AIは、クラウド上で機械学習パイプラインを構築および作成するためのエンドツーエンドソリューションです。ただし、Vertex AIの詳細については、別の記事で説明します。AutoMLは、主に転移学習とニューラルサーチアーキテクチャに依存しています。データを提供するだけで、AutoMLはユースケースに最適なカスタムモデルを構築します。 この記事では、Pythonコードを使ったGoogle Cloud Platform上でのAutoMLの利点、使用方法、実践的な実装について説明します。 学習目標 コードを使ったAutoMLの使用方法を読者に知らせること AutoMLの利点を理解すること クライアントライブラリを使用してMLパイプラインを作成する方法 この記事は、Data Science Blogathonの一部として公開されました。 問題の説明 機械学習モデルを構築することは時間がかかり、プログラミング言語の熟練度、数学と統計の良い知識、および機械学習アルゴリズムの理解などの専門知識が必要です。過去には、技術的なスキルを持つ人々だけがデータサイエンスで働き、モデルを構築できました。非技術的な人々にとっては、機械学習モデルを構築することは最も困難なタスクでした。ただし、モデルを構築した技術的な人々にとっても道のりは容易ではありませんでした。モデルを構築した後、メンテナンス、展開、および自動スケーリングには追加の努力、労働時間、およびわずかに異なるスキルセットが必要です。これらの課題を克服するために、グローバル検索大手のGoogleは、2014年にAutoMLを発表しましたが、後に一般に公開されました。 AutoMLの利点 AutoMLは手動の介入を減らし、少しの機械学習の専門知識が必要となります。…

ジョン・イサザ弁護士、FAI氏によるAIとChatGPTの法的な土壌を航行する方法
私たちは、Rimon LawのパートナーであるJohn Isaza, Esq., FAIに感謝しています彼は、法的な景観の変化、プライバシー保護とイノベーションの微妙なバランス、そしてAIツールを統合する際に生じる独特の法的な意義など、多岐にわたる側面で自身の物語と貴重な洞察を共有してくれましたJohnは、AIに関連する課題や考慮事項について貴重な観点を提供しています...John Isaza, Esq., FAI がAIとChatGPTの法的景観を航海するための記事を読む»

生成AIの時代にデータサイエンティストはまだ必要ですか?
ChatGPTの台頭
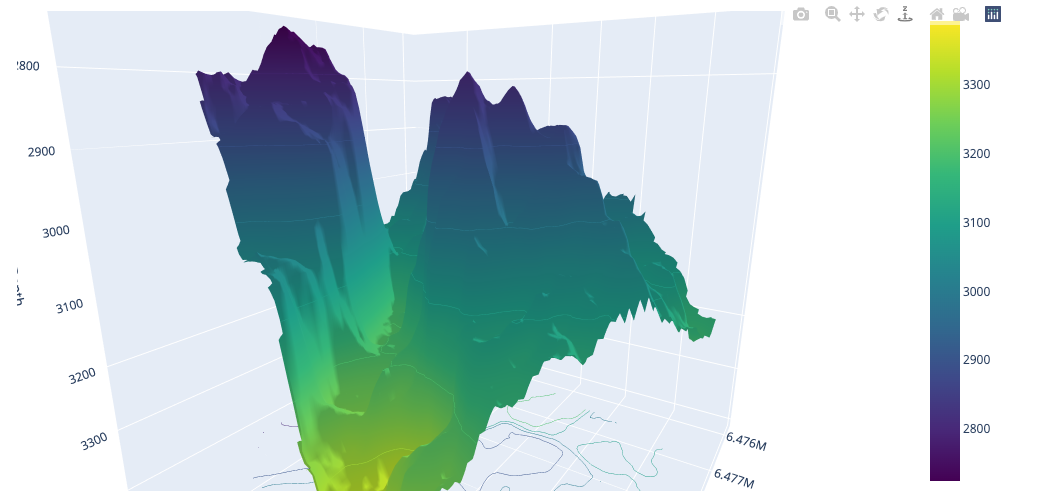
Plotlyの3Dサーフェスプロットを使用して、地質表面を視覚化する
地球科学の分野においては、地下に存在する地質層の完全な理解が不可欠です層の正確な位置と形状を知ることで、...
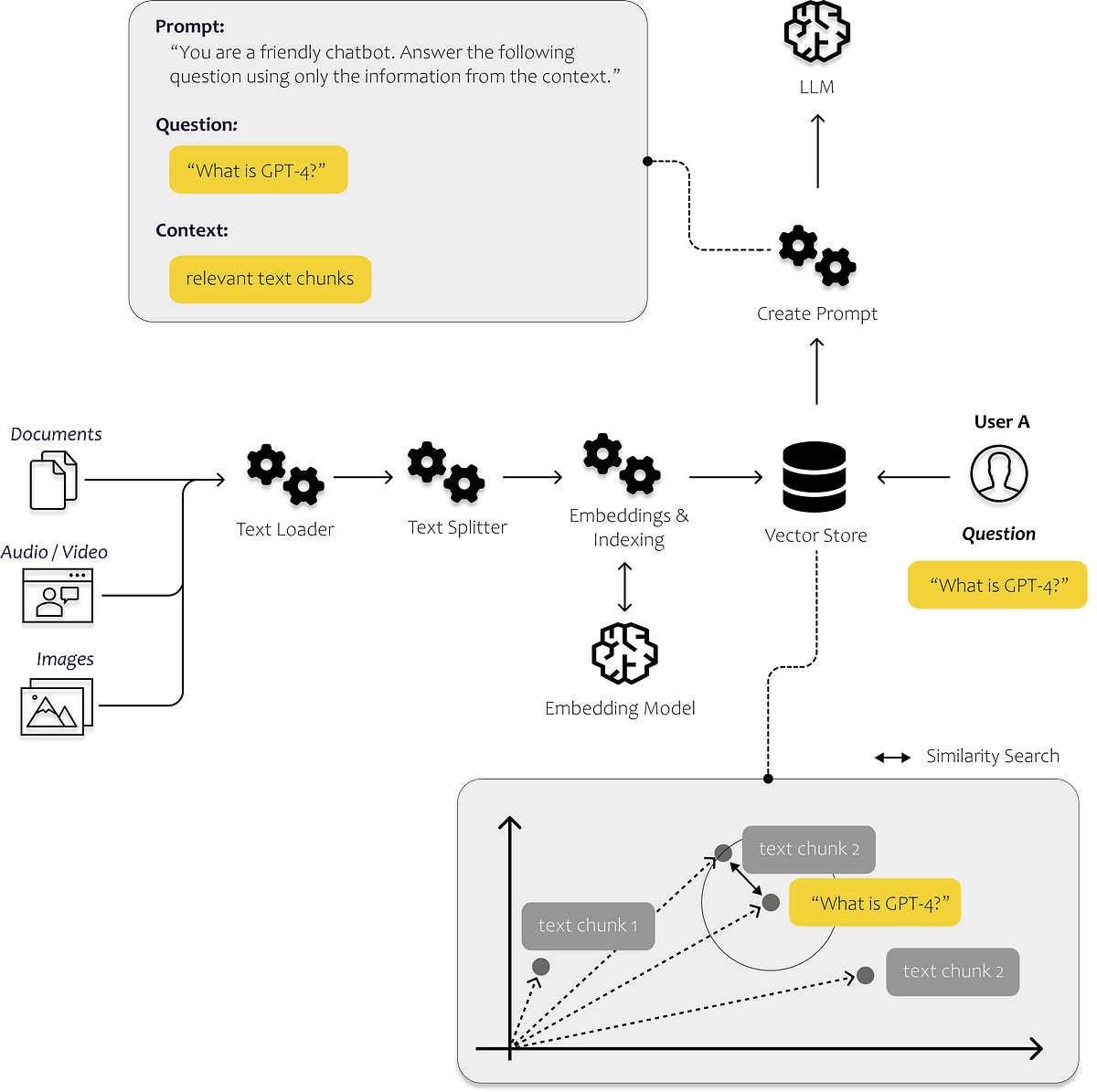
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.