Learn more about Search Results A - Page 638

- You may be interested
- このAI論文は、ChatGPTを基にしたテキスト...
- 研究者たちは、肩越しに画面をのぞき見す...
- 「独立性の理解とその因果推論や因果検証...
- SaneBoxのレビュー:メールを整理して生産...
- 「PyTorchモデルのパフォーマンス分析と最...
- ゲーム開発のためのAI:5日間で農業ゲーム...
- LLM幻覚を軽減する方法
- スタビリティAIは、StableChatを紹介しま...
- 「Meer Pyrus Base RoboCupサッカーの二次...
- 第四次産業革命:AIと自動化
- データサイエンティストが生産性を10倍に...
- 「データの中で最も異常なセグメントを特...
- 「ETLにおける進化:変換の省略がデータ管...
- 「人間の労働が機械学習を可能にする方法」
- 勝利チームの構築:従業員のエンゲージメ...

MLflowを使用した機械学習実験のトラッキング
イントロダクション 機械学習(ML)の領域は急速に拡大し、さまざまなセクターで応用されています。MLflowを使用して機械学習の実験を追跡し、それらを構築するために必要なトライアルを管理することは、それらが複雑になるにつれてますます困難になります。これにより、データサイエンティストにとって多くの問題が生じる可能性があります。例えば: 実験の損失または重複:実施された多くの実験を追跡することは困難であり、実験の損失や重複のリスクを高めます。 結果の再現性:実験の結果を再現することは困難な場合があり、モデルのトラブルシューティングや改善が困難になります。 透明性の欠如:モデルの予測を信頼するのが難しくなる場合があります。モデルの作成方法がわかりにくいためです。 写真提供:CHUTTERSNAP(Unsplash) 上記の課題を考慮すると、MLの実験を追跡し、再現性を向上させるためのメトリックをログに記録し、協力を促進するツールを持つことが重要です。このブログでは、コード例を含め、オープンソースのML実験追跡とモデル管理ツールであるMLflowについて探求し学びます。 学習目標 本記事では、MLflowを使用した機械学習の実験追跡とモデルレジストリの理解を目指します。 さらに、再利用可能で再現性のある方法でMLプロジェクトを提供する方法を学びます。 最後に、LLMとは何か、なぜアプリケーション開発のためにLLMを追跡する必要があるのかを学びます。 MLflowとは何ですか? MLflowロゴ(出典:公式サイト) MLflowは、機械学習プロジェクトを簡単に扱うための機械学習実験追跡およびモデル管理ソフトウェアです。MLワークフローを簡素化するためのさまざまなツールと機能を提供します。ユーザーは結果を比較し、複製し、パラメータやメトリックをログに記録し、MLflowの実験を追跡することができます。また、モデルのパッケージ化と展開も簡単に行えます。 MLflowを使用すると、トレーニング実行中にパラメータとメトリックをログに記録することができます。 # mlflowライブラリをインポートする import mlflow # mlflowのトラッキングを開始する mlflow.start_run() mlflow.log_param("learning_rate", 0.01)…
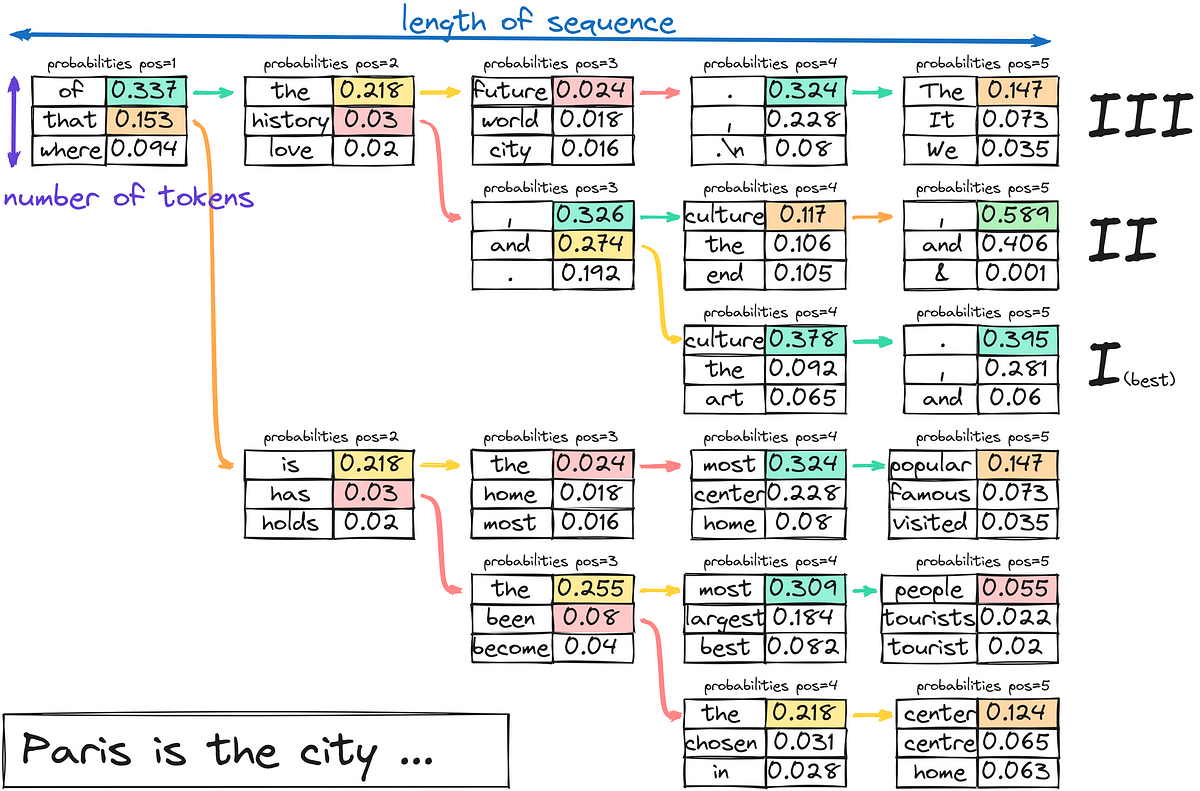
「LLMはどのようにテキストを生成するのか?」
今日は、3つ目のステップに集中します-テキストのデコードと生成最初の2つのステップに興味がある場合は、以下にコメントしてくださいそれらのトピックもカバーすることを検討しますさあ、少し潜りましょう...

「ニューラルネットワークの探索」
AIの力を解き放つ:ニューラルネットワークとその応用のガイド

「MITの新しい機械学習の研究では、階層的な計画(HiP)のための組成的な基礎モデルを提案しています:長期的な課題の解決のために言語、ビジョン、行動を統合する」
見知らぬ家でお茶を準備するという課題について考えてみましょう。このタスクを効率的に完了するための戦略は、抽象レベル(例えば、お茶を温めるために必要な高レベルの手順)、具体的な幾何学的レベル(例えば、彼らがどのように物理的に動き、キッチンを通り抜けるか)、および制御レベル(例えば、カップを持ち上げるために関節をどのように動かすか)を含む、複数のレベルで階層的に推論することです。茶ポットを探すための抽象的なプランは、幾何学的レベルで物理的に考えられ、彼らが行える行動に基づいて実行可能でなければなりません。そのため、各レベルでの推論が互いに整合性を持つことが重要です。本研究では、階層的な推論を用いることができる、ユニークな長期的なタスク解決用のボットの開発を調査しています。 大規模な「基礎モデル」は、数学的な推論、コンピュータビジョン、自然言語処理の問題に取り組む上でリードを取っています。「基礎モデル」を作成することは、このパラダイムの下で重要な問題であり、ユニークで長期的な意思決定問題に対応できる「基礎モデル」の作成には、多くの関心が集まっています。いくつかの以前の研究では、視覚、言語、アクションのデータをマッチさせ、長期的なタスクを処理するために単一のニューラルネットワークを訓練することが行われました。しかし、連動したビジョンと言語のロボットの例は、インターネット上で利用可能な豊富な資料に対して見つけることが難しく、編集するのにも費用がかかります。 さらに、モデルの重みがオープンソース化されていないため、GPT3.5/4やPaLMなどの高性能な言語モデルを微調整することは現在困難です。基礎モデルの主な特徴は、新しい問題を解決するために学習する必要がある場合よりも、はるかに少ないデータで解決できることです。本研究では、長期的な計画のための基礎モデルを構築するために、3つのモダリティ間でペアのデータを収集するという時間と費用のかかるプロセスに代わるスケーラブルな代替手段を模索しています。これは、新しい計画タスクの解決においても合理的に効果的であることができるでしょうか。 Improbable AI Lab、MIT-IBM Watson AI Lab、マサチューセッツ工科大学からの研究者たちは、階層的計画のための構成的基礎モデル(HiP)を提案しています。これは、言語、ビジョン、アクションのデータに独自にトレーニングされた多くの専門モデルから構成される基礎モデルです。基礎モデルを構築するために必要なデータ量は大幅に削減されます(図1)。HiPは、抽象的な言語指示で指定された意図したタスクから、一連のサブタスク(すなわち、計画)を発見するために大規模な言語モデルを使用します。HiPは、環境に関する幾何学的および物理的情報を収集するために大規模なビデオ拡散モデルを使用して、観察のみの軌跡としてより複雑な計画を開発します。最後に、HiPは、以前にトレーニングされた大規模な逆モデルを使用して、一連の自己中心的な画像をアクションに変換します。 図1:階層的計画のための構成的基礎モデルが上記に示されています。HiPは、タスクモデル(LLMによって表される)を使用して抽象的な計画を作成し、ビジュアルモデル(ビデオモデルによって表される)を使用して画像の軌跡計画を作成し、自己中心的なアクションモデルを使用して画像の軌跡からアクションを推論します。 連動した意思決定データをモダリティ間で収集する必要がないため、構成的な設計選択は、さまざまなモデルが階層の異なるレベルで推論し、専門的な結論を共同で導くことを可能にします。別々にトレーニングされた3つのモデルは、相反する結果を生成する可能性があり、全体の計画プロセスで失敗する可能性があります。例えば、キャビネットでティーケトルを探すという計画のステップは、一つのモデルでは高い確率で成功する一方で、もう一つのモデルでは確率がゼロになるかもしれません。家にキャビネットがない場合などです。代わりに、すべての専門モデルにわたって尤度を最大化する戦略をサンプリングすることが重要です。 彼らは、多様なモデル間で一貫性を確保するための反復的な改良技術を提供しています。ダウンストリームモデルからのフィードバックを利用して、異なるモデル間で一貫性のある計画を開発します。言語モデルの生成プロセスの出力分布には、各段階で現在の状態を表す条件付きの尤度推定器からの中間フィードバックが組み込まれています。同様に、アクションモデルからの中間入力は、開発プロセスの各段階でのビデオの作成を向上させます。この反復的な改良プロセスにより、多くのモデル間で合意形成が促進され、目標に対応し、既存の状態とエージェントに基づいて実行可能な階層的に一貫した計画が作成されます。彼らの提案された反復的改良手法は、広範なモデルの微調整を必要とせず、トレーニングの計算効率が高くなっています。 さらに、彼らはモデルの重みを知る必要もなく、彼らの戦略は入力と出力のAPIアクセスを提供するすべてのモデルに適用できます。結論として、彼らは長期の計画を作成するために、さまざまなインターネットおよびエゴセントリックなロボティクスデータのモダリティで独立に取得された基礎モデルの組成を使用する階層的計画の基礎モデルを提供しています。3つの長期のテーブルトップ操作シナリオにおいて、彼らは有望な結果を示しています。
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」

本番環境向けのベクトル検索の構築
ベクトルストアは、機械学習の進化において重要な役割を果たし、データの数値エンコーディングのための必須のリポジトリとして機能しますベクトルは、多次元空間におけるカテゴリカルなデータポイントを表すために使用される数学的なエンティティです機械学習の文脈では、ベクトルストアは、データの保存、取得、フィルタリングを行う手段を提供します

大規模言語モデルの応用の最先端テクニック
イントロダクション 大規模言語モデル(LLM)は、人工知能の絶えず進化する風景において、注目すべきイノベーションの柱です。GPT-3のようなこれらのモデルは、印象的な自然言語処理およびコンテンツ生成の能力を示しています。しかし、それらのフルポテンシャルを活かすには、その複雑な仕組みを理解し、ファインチューニングなどの効果的な技術を用いてパフォーマンスを最適化する必要があります。 私はLLMの研究の奥深さに踏み込むことが好きなデータサイエンティストとして、これらのモデルが輝くためのトリックや戦略を解明するための旅に出ました。この記事では、LLMのための高品質データの作成、効果的なモデルの構築、および現実世界のアプリケーションでの効果を最大化するためのいくつかの重要な側面を紹介します。 学習目標: 基礎モデルから専門エージェントまでのLLMの使用における段階的なアプローチを理解する。 安全性、強化学習、およびデータベースとのLLMの接続について学ぶ。 「LIMA」、「Distil」、および質問応答技術による一貫した応答の探求。 「phi-1」などのモデルを用いた高度なファインチューニングの理解とその利点。 スケーリング則、バイアス低減、およびモデルの傾向に対処する方法について学ぶ。 効果的なLLMの構築:アプローチと技術 LLMの領域に没入する際には、その適用の段階を認識することが重要です。これらの段階は、私にとって知識のピラミッドを形成し、各層が前の層に基づいて構築されています。基礎モデルは基盤です。それは次の単語を予測することに優れたモデルであり、スマートフォンの予測キーボードと同様です。 魔法は、その基礎モデルをタスクに関連するデータを用いてファインチューニングすることで起こります。ここでチャットモデルが登場します。チャットの会話や教示的な例でモデルをトレーニングすることで、チャットボットのような振る舞いを示すように誘導することができます。これは、さまざまなアプリケーションにおける強力なツールです。 インターネットはかなり乱暴な場所であるため、安全性は非常に重要です。次のステップは、人間のフィードバックからの強化学習(RLHF)です。この段階では、モデルの振る舞いを人間の価値観に合わせ、不適切な応答や不正確な応答を防止します。 ピラミッドをさらに上に進むと、アプリケーション層に達します。ここでは、LLMがデータベースと接続して、有益な情報を提供し、質問に答えたり、コード生成やテキスト要約などのタスクを実行したりすることができます。 最後に、ピラミッドの頂点は、独自にタスクを実行できるエージェントの作成に関わります。これらのエージェントは、ファイナンスや医学などの特定のドメインで優れた性能を発揮する特殊なLLMと考えることができます。 データ品質の向上とファインチューニング データ品質はLLMの効果において重要な役割を果たします。データを持つことだけでなく、正しいデータを持つことが重要です。たとえば、「LIMA」のアプローチでは、注意深く選ばれた小さなセットの例が大きなモデルよりも優れることが示されています。したがって、焦点は量から品質へと移ります。 「Distil」テクニックは、別の興味深いアプローチを提供しています。ファインチューニング中に回答に根拠を加えることで、モデルに「何」を教えるかと「なぜ」を教えることができます。これにより、より堅牢で一貫性のある応答が得られることがしばしばあります。 Metaの創造的なアプローチである回答から質問のペアを作成する手法も注目に値します。既存のソリューションに基づいて質問を形成するためにLLMを活用することで、より多様で効果的なトレーニングデータセットが作成できます。 LLMを使用したPDFからの質問ペアの作成 特に魅力的な手法の1つは、回答から質問を生成することです。これは一見矛盾する概念ですが、知識の逆破壊とも言える手法です。テキストがあり、それから質問を抽出したいと想像してみてください。これがLLMの得意分野です。 たとえば、LLM Data Studioのようなツールを使用すると、PDFをアップロードすると、ツールが内容に基づいて関連する質問を出力します。このような手法を用いることで、特定のタスクを実行するために必要な知識を持ったLLMを効率的に作成することができます。…

UCIと浙江大学の研究者は、ドラフティングと検証のステージを使用した自己推測デコーディングによるロスレスな大規模言語モデルの高速化を紹介しました
トランスフォーマーに基づく大規模言語モデル(LLM)は、GPT、PaLM、LLaMAなど、さまざまな実世界のアプリケーションで広く使用されています。これらのモデルは、テキスト生成、翻訳、自然言語解釈など、さまざまなタスクに適用されています。ただし、特に低遅延が重要な場合において、これらのモデルの推論コストが大きな懸念事項となっています。これらのモデルが使用する自己回帰デコーディング方式が、高い推論コストの主な原因です。自己回帰デコーディングでは、各出力トークンが順次生成されるため、多くのトランスフォーマー呼び出しがあります。各トランスフォーマー呼び出しのメモリ帯域幅は制限されており、効率の悪い計算と長い実行時間を引き起こします。 大規模言語モデル(LLM)の推論プロセスを高速化するために、最近の研究では、補助モデルを必要としないユニークな手法であるセルフスペキュレーティブデコーディングを導入しています。この手法は、出力品質を保持しながら推論をより迅速に生成する問題に取り組んでいます。これは、起案と検証の2段階の手順を組み合わせることによって特徴付けられています。 起案ステージ – 起案ステージの目的は、従来の自己回帰方式を使用して生成されたトークンよりもわずかに品質が劣るドラフトトークンをより速く生成することです。このために、この手法では起案中にいくつかの中間層をバイパスします。LLMのこれらの中間層は出力を洗練するが、推論中に多くの時間とリソースを消費します。 検証ステージ – この手法は、起案ステージでドラフトの出力トークンを生成し、オリジナルの変更されていないLLMを使用してこれらのトークンを単一の順方向パスで検証します。従来の自己回帰デコーディング手法を使用した場合、LLMは同じ最終結果を生成するため、この検証ステップによって保証されます。したがって、起案ステージがトークンをより速く生成したとしても、最終的な品質は保持されます。 セルフスペキュレーティブデコーディングは、ニューラルネットワークの追加のトレーニングを必要としないため、その主な利点の1つです。既存の推論の高速化手法では、補助モデルのトレーニングやLLMのアーキテクチャの大幅な変更が一般的であり、これらは課題がありリソースを消費する要素です。一方、セルフスペキュレーティブデコーディングは、「プラグアンドプレイ」のアプローチであり、追加のトレーニングやモデルの変更なしに既存のLLMに追加できます。 この研究は、セルフスペキュレーティブデコーディングの有効性を実証する経験的なサポートを提供しています。ベンチマークの結果は、LLaMA-2およびその改良モデルを使用して示されています。これらのベンチマークに基づいて、セルフスペキュレーティブデコーディング手法は、従来の自己回帰手法よりもデータを1.73倍速くデコードできます。これは、推論プロセスを約2倍速くする重要な利点があり、遅延が問題となる状況で重要です。 まとめると、セルフスペキュレーティブデコーディングは、大規模言語モデルが情報を推論する方法を向上させる革新的な手法です。これは、起案ステージ中にスキップするレイヤーを選択してトークンをより速く生成し、検証ステージ中に出力品質を検証することによって実現されます。この手法は、ニューラルネットワークの追加のメモリ負荷やトレーニング要件を追加することなく、LLMの推論を高速化します。

「データと分析について非データの人々と話す方法」
効果的なコミュニケーション戦略は、関連性のあるアナロジーの作成、視覚的な要素の戦略的な活用、そして意識的なストーリーテリングなどで、このギャップを埋める役割を果たします聴衆の文脈を理解し、専門用語を避けることにより、データ専門家は自分たちの調査結果をよりアクセスしやすくすることができます
時系列のLSTMモデルの5つの実践的な応用とコード
「2022年1月に『時系列のためのLSTMニューラルネットワークモデルの探求』を書いたとき、私の目標は、高度なニューラルネットワークを簡単にPythonで実装できることを示すことでしたscalecastを使用していました」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.