Learn more about Search Results A - Page 636

- You may be interested
- 2023年に知っておく必要があるデータ分析...
- 『広範な展望:NVIDIAの基調講演がAIの更...
- VoAGIニュース、6月14日:あなたの無料の...
- クラウドストライクは、Fal.Con 2023にお...
- 「Amazon SageMakerを使用して、Rayベース...
- 「AI企業がソフトウェア供給チェーンの脆...
- 「MLOpsに関する包括的なガイド」
- データ契約の裏側:消費者の責任の目覚め
- 「機械学習とAIが偽のレビューを迅速に検...
- LMSYS ORG プレゼント チャットボット・ア...
- 「夢を先に見て、後で学ぶ:DECKARDは強化...
- 「データと分析について非データの人々と...
- 「2023年の最高の人工知能AIベースのアー...
- 「2023年の機械学習のアンラーニング:現...
- 「誰も所有していないサービスを修復する...

スタンフォード大学の研究は、PointOdysseyを紹介します:長期ポイント追跡のための大規模な合成データセット
大規模な注釈付きデータセットは、さまざまなコンピュータビジョンタスクで正確なモデルを作成するためのハイウェイとして機能してきました。この研究では、細かい粒度の長距離トラッキングを達成するために、このようなハイウェイを提供することを目指しています。細かい粒度の長距離トラッキングは、映画の任意のフレームの任意のピクセルの位置を与えられた場合に、できるだけ長い時間、マッチングする世界の表面点を追跡することを目指しています。細かい粒度の短距離トラッキング(光流など)を目的としたデータセットの世代がいくつかあり、さまざまな種類の粗い粒度の長距離トラッキング(単一オブジェクトトラッキング、複数オブジェクトトラッキング、ビデオオブジェクトセグメンテーションなど)を目的とした定期的に更新されるデータセットがあります。しかし、これら2つの監視タイプのインターフェースに関する作品は限られています。 研究者たちはすでに実世界の映画で細かい粒度のトラッカーをスパースな人手による注釈(BADJAとTAPVid)を持つ映画でテストし、非現実的な合成データ(FlyingThings++とKubric-MOVi-E)でそれらをトレーニングしています。合成データは、ランダムなオブジェクトがランダムなバックドロップ上で予期せぬ方向に移動するものです。これらのモデルが実際のビデオに一般化できるという事実は興味深いですが、このような基本的なトレーニングを使用することで、長期的なコンテキストとシーンレベルの意味理解の開発が妨げられます。彼らは、長距離ポイントトラッキングは光流の拡張として考えてはならず、自然主義が犠牲になってもネガティブな結果が発生しないと主張しています。 ビデオのピクセルは多少ランダムに動くかもしれませんが、その経路にはカメラの振動、オブジェクトレベルの移動と変形、社会的および物理的相互作用を含む多くのモデリング可能な要素が反映されています。進歩は、問題の重要性を認識することに依存しています。これは、データと方法論の両方の観点からの問題の重要性を人々が認識することに依存しています。スタンフォード大学の研究者たちは、PointOdysseyという長期的な細かい粒度のトラッキングのトレーニングと評価のための大規模な合成データセットを提案しています。彼らのコレクションには、リアルワールドのビデオの複雑さ、多様性、リアリズムがすべて表現されており、ピクセルパーフェクトな注釈はシミュレーションを通じてのみ実現可能です。 彼らは、ランダムまたは手動設計ではなく、リアルワールドのビデオとモーションキャプチャから採掘したモーション、シーンレイアウト、カメラの軌跡を使用しており、これは彼らの作業を以前の合成データセットと区別しています。また、環境マップ、照明、人間および動物の体、カメラの軌跡、材料など、さまざまなシーン属性でドメインのランダム化を使用しています。高品質なコンテンツとレンダリング技術のアクセス性の向上により、これまでに達成できなかったより写真的なリアリズムを提供することもできます。彼らのデータのモーションプロファイルは、大規模な人間および動物のモーションキャプチャデータセットから派生しています。これらのキャプチャを使用して、屋外環境でのヒューマノイドや他の動物のリアルな長距離軌跡を生成します。 屋外環境では、これらのアクターを地面にランダムに配置された3Dオブジェクトとペアにします。これらのオブジェクトは、キックされたり、足が接触すると蹴られたりするなど、物理的な反応を示します。次に、内部設定のモーションキャプチャを使用して、リアルな屋内シナリオを作成し、キャプチャ環境を手動で再現します。これにより、元のデータのシーン認識の性格を保ちながら、正確なモーションと相互作用を再現することができます。また、シチュエーションの複雑なマルチビューデータを提供するために、実際の映像から導かれたカメラの軌跡をインポートし、合成された存在の頭部に追加のカメラを接続します。KubricとFlyingThingsの主にランダムなモーションパターンとは対照的に、キャプチャ駆動アプローチを取っています。 彼らのデータは、従来のボトムアップの手がかり(特徴マッチングなど)だけに頼るのではなく、シーンレベルの手がかりを利用してトラックに強力なプライオリティを提供するトラッキング技術の開発を促進します。42種類のヒューマノイド形状、アーティストによって作成されたテクスチャ、7種類の動物、1K以上のオブジェクト/背景テクスチャ、1K以上のオブジェクト、20のオリジナル3Dシーン、50の環境マップなど、さまざまなシミュレートされたアセットの大規模なコレクションがデータに美的多様性を与えています。シーンの照明をランダム化して、さまざまな暗い場所と明るい場所を作成します。さらに、シーンにダイナミックな霧や煙の効果を追加し、FlyingThingsとKubricに完全に欠けている部分的な遮蔽のタイプを追加します。PointOdysseyが開く新しい問題の1つは、長距離の時間的コンテキストをどのように使用するかです。 たとえば、最先端のトラッキングアルゴリズムであるPersistent Independent Particles (PIPs)は、8フレームの時間ウィンドウを持っています。彼らは、任意の長さの時間的コンテキストを使用するための最初のステップとして、PIPにいくつかの変更を提案しています。これには、8フレームの時間範囲を大幅に拡張し、テンプレートの更新メカニズムを追加することが含まれます。実験結果によれば、彼らのソリューションは、PointOdysseyのテストセットおよび実世界のベンチマークにおいて、トラッキングの正確さにおいて他のすべての手法を上回るという結果です。結論として、本研究の主要な貢献である、リアルワールドの細かい粒度のモニタリングの難しさと機会を反映しようとする長期的なポイントトラッキングのための大規模な合成データセットであるPointOdysseyです。

「解答付きの無料データサイエンスプロジェクト5つ」
はじめに データサイエンスに没頭し、スキルを磨きたいですか?もう探す必要はありません!この記事では、ステップバイステップの解決策を備えた、エキサイティングなデータサイエンスプロジェクトを5つ紹介します。初心者が学びたいと思っているか、経験豊富なデータ愛好家がポートフォリオを拡大したいと思っているかに関係なく、これらの実践的な無料のデータサイエンスプロジェクトは、実世界の課題を乗り越える力を与えてくれます。なによりも、無料で利用できます。さあ、このデータ駆動の旅に乗り出し、一つずつデータサイエンスの専門知識を高めましょう! データサイエンスプロジェクトの重要性 いくつかの説得力のある理由から、データサイエンスプロジェクトはこの分野で重要な役割を果たしています。まず、それらは理論的な知識と実践の橋渡しとなり、データサイエンティストが学んだことを実際のシナリオでテストし、実装することができます。これらのプロジェクトは、データの収集、クリーニング、分析、可視化、モデリングのスキルを磨くための貴重な学習経験となります。 さらに、完了したデータサイエンスプロジェクトは強力なポートフォリオの基盤となり、求職活動やフリーランスの機会を向上させます。また、多くのプロジェクトが複雑な課題に取り組むことを含むため、問題解決能力と批判的思考力を磨きます。さらに、プロジェクトのテーマに応じて、データサイエンティストは業界固有の知識を獲得し、特定の産業でより効果的になることがあります。 さらに、データサイエンスプロジェクトは、意思決定をサポートする洞察を提供し、ビジネスがプロセスを最適化し、成長の機会を特定することができるようにします。データ分析技術の限界を押し広げることで、イノベーションを促進します。プロジェクトでの協力は、職場で重要なチームワークとコミュニケーションスキルを育成します。最後に、これらのプロジェクトは、データサイエンティストが常に最新のツールと技術に適応し、継続的な学習を促進することで、この分野の最先端に立ち続けることをサポートします。 また読む:ソースコード付きトップ10のデータサイエンスプロジェクト トップ5の無料データサイエンスプロジェクト ローンの対象分類 感情分析とテキスト分類 PythonによるWebスクレイピング 回帰による売上予測 時系列予測 プロジェクト1:ローンの対象分類 このプロジェクトでは、ローンの対象分類に焦点を当てています。特に、住宅ローンに関するケーススタディに取り組みます。オンライン申し込み時に提供された顧客の詳細に基づいて、ローンの対象化プロセスを自動化することが課題です。 解決方法 このコースを通じて、分類問題に対するさまざまなアプローチを学びます。Pythonを使用して、ローンの対象分類問題を解決するための実践的な経験を提供します。 必要なツール Python、機械学習と分類のためのライブラリ。 解決方法の索引 問題の設定 仮説の生成 演習2 |…

自己学習のためのデータサイエンスカリキュラム
はじめに データサイエンティストになる予定ですが、どこから始めればいいかわからないですか?心配しないでください、私たちがお手伝いします。この記事では、自己学習のためのデータサイエンスカリキュラム全体と、プロセスを早めるためのリソースとプログラムのリストをカバーします。 このカリキュラムでは、優れたデータサイエンティストになるために必要なツール、トリック、知識の基礎をカバーしています。もし科学と統計について少し知識があるなら、良い位置にいます。これらのことについて初めて知る場合は、まずそれらについて学ぶと役立つかもしれません。そして、既にデータに詳しい場合は、これはクイックな復習になるかもしれません。 覚えておいてください、すべてのプロジェクトでこれらのスキルをすべて使うわけではありません。一部のプロジェクトでは、このリストにない特別なトリックやツールが必要です。しかし、このカリキュラムの内容を十分に理解し、習得すると、ほとんどのデータサイエンスの仕事に対応できるようになります。そして、必要なときに新しいことを学ぶ方法も知っています。 さあ、始めましょう! データサイエンスカリキュラムをなぜフォローするのか? データサイエンスのカリキュラムに従うことは、構造化された効果的な学習には欠かせません。これにより、知識とスキルを習得するための明確なパスが提供され、この分野の広大さに圧倒されることなく学ぶことができます。良いカリキュラムは包括的なカバレッジを保証し、基礎的な概念から高度なテクニックまでを案内します。このステップバイステップのアプローチは、複雑なトピックに深入りする前に、堅固な基盤を築くための基礎となります。 さらに、カリキュラムは実践的な応用を促進します。多くのプログラムにはハンズオンのプロジェクトや演習が含まれており、理論的な知識を実世界のスキルに変換することができます。進捗を体系的に追跡することで、学習の旅においてモチベーションを保ち、集中する助けとなります。 即効的な利点を超えて、カリキュラムに従うことは職業にも役立ちます。データサイエンスの構造化された教育を完了することは、潜在的な雇用主に対してコミットメントと熟練度を示し、仕事の見通しを向上させます。さらに、このアプローチは適応性を育成し、自身のニーズに合わせてペースを調整し、困難なテーマに深入りすることができるようにします。 要するに、データサイエンスのカリキュラムは必須のスキルを身につけるだけでなく、データサイエンスの常に進化する分野で独立して学び続ける能力を養うことも可能です。 自己学習のためのデータサイエンスカリキュラム 以下は、データサイエンスの旅を始める際に探索するための主要な領域の簡略化されたロードマップです: 数学の基礎 多変数微積分:複数の変数の関数、導関数、勾配、ステップ関数、シグモイド関数、コスト関数などを理解する。 線形代数:ベクトル、行列、転置や逆行列などの行列演算、行列式、内積、固有値、固有ベクトルを習得する。 最適化手法:コスト関数、尤度関数、誤差関数などについて学び、勾配降下法(および確率的勾配降下法などの変種)などのアルゴリズムを理解する。 プログラミングの基礎 PythonまたはRを主要な言語として選択する。 Pythonの場合、NumPy、pandas、scikit-learn、TensorFlow、PyTorchなどのライブラリを習得する。 データの基礎 さまざまな形式(CSV、PDF、テキスト)でのデータ操作を学ぶ。 データのクリーニング、補完、スケーリング、インポート、エクスポート、Webスクレイピングのスキルを習得する。 PCAやLDAなどのデータ変換や次元削減の手法を探索する。 確率と統計の基礎…

バッテリー最適化の解除:機械学習とナノスケールX線顕微鏡がリチウムバッテリーを革命化する可能性
優れた研究機関から画期的な取り組みが浮上し、リチウム系バッテリーの謎めいた複雑さを解明することを目指しています。研究者たちは画像学習を駆使し、ピクセルレベルでX線ビデオを緻密に分析する革新的な手法を用いており、これによってバッテリーの研究が革新的に進展する可能性があります。 この取り組みの中心にある課題は、特に活性物質のナノ粒子で構成されたリチウム系バッテリーの包括的な理解を求めることです。これらのバッテリーは現代技術の命脈であり、スマートフォンから電気自動車まで多くのデバイスを動かしています。しかし、これらの複雑な内部構造を解読することは一貫して困難でした。 MITとスタンフォードの多学科チームが達成したブレイクスルーは、バッテリーの動作を高解像度のX線ビデオから深い洞察を引き出す能力にあります。これまでは、これらのビデオは情報の宝庫でしたが、その複雑さから有意義なデータを抽出することは困難でした。 研究者たちは、これらのバッテリー内のインターフェースがその挙動を制御する上で重要な役割を果たしていることを強調しています。この新たな理解によって、バッテリーの性能を大幅に向上させるためのエンジニアリングソリューションの可能性が開かれます。 さらに、バッテリー技術の進展を促進するためには、基礎的な科学に基づく洞察が必要です。画像学習を用いてナノスケールのX線動画を分析することで、研究者は従来不明瞭だった知識にアクセスできるようになりました。これは、より効率的なバッテリーの開発を目指す産業パートナーにとって重要です。 この研究の方法論は、充電および放電プロセス中のリン酸鉄リチウム粒子の詳細な走査トンネルX線顕微鏡動画をキャプチャすることで行われました。人間の目では捉えることができない微妙な変化を、洗練されたコンピュータービジョンモデルが詳細に検証しました。その結果は、以前の理論モデルと比較されました。その中で最も重要な発見の一つは、リチウムイオンの流れと個々の粒子の炭素コーティングの厚さとの相関関係の発見でした。この発見は、将来のリチウムイオンリン酸塩バッテリーシステムの最適化に向けた有望な道を提供し、バッテリーの性能を向上させることができます。 要約すると、優れた研究機関の協力と画像学習のバッテリー研究への統合は、リチウム系バッテリーの理解を大きく前進させる重要な進歩です。インターフェースにスポットライトを当て、画像学習の能力を活用することで、科学者たちはこれらの重要なエネルギー貯蔵デバイスの性能と効率を向上させる新たな可能性を発見しました。この研究はバッテリー技術の限界を押し広げるだけでなく、近い将来より高度で持続可能なエネルギーソリューションの到来を約束しています。
「Python初心者のための独自のPythonパッケージの作成と公開」
Pythonパッケージは、プロジェクト間で簡単に共有し、実装することができる再利用可能なコードの集まりです私たちは一度コードを書き、多くの場所で何度も使用することができますパッケージを使用することで、私たちは共有することができます…
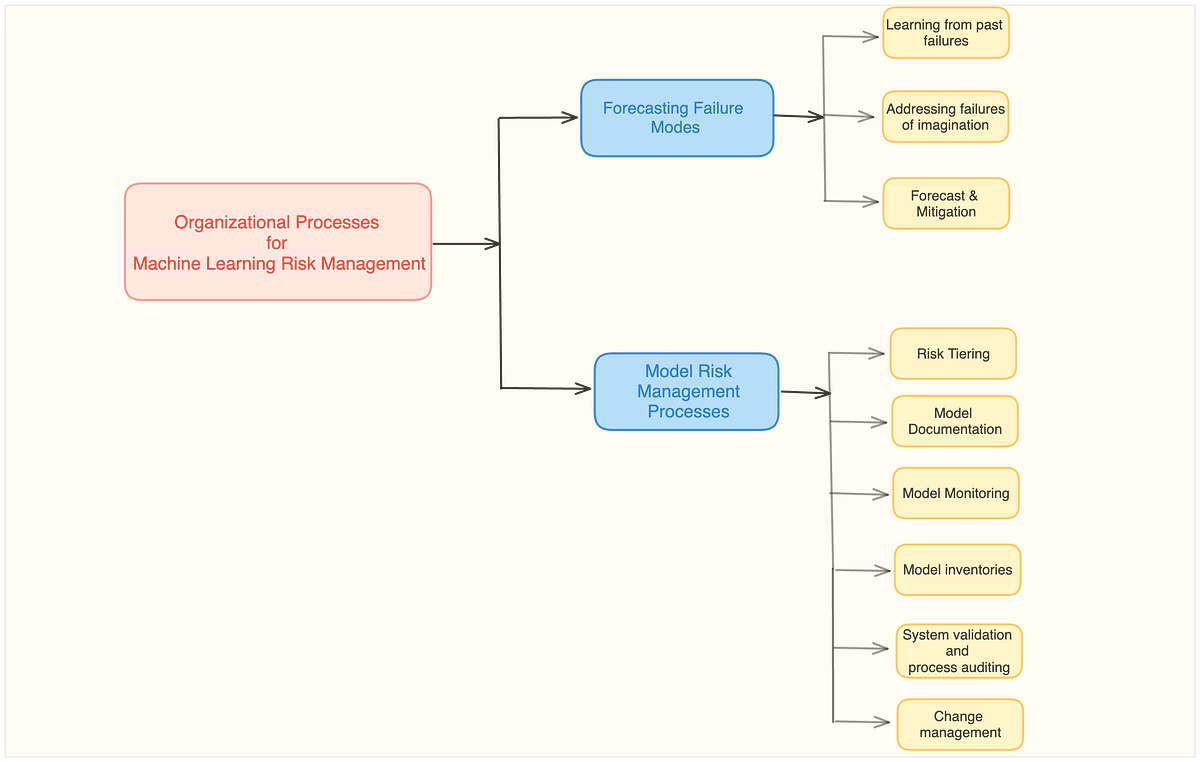
機械学習リスク管理の組織プロセス
「機械学習リスク管理シリーズでは、機械学習(ML)システムの信頼性を確保するための重要な要素を解明する旅に乗り出しました最初の...」

Pythonのスタックの実装:関数、メソッド、例など
導入 スタックは、プログラミングとコンピュータサイエンスにおける基本的な概念です。この記事では、データ管理とアルゴリズムにおいて重要なLast-In-First-Out(LIFO)の振る舞いを持つPythonスタックの実装について探求します。効率的なPythonスタックの使用についての基本原則、メソッド、および重要な考慮事項を探求します。 Pythonにおけるスタックとは何ですか? スタックは線形データ構造です。これはLast-In-First-Out(LIFO)の原則に従います。要素のコレクションとして機能し、最後に追加されたアイテムが最初に削除されます。Pythonにおけるスタックに関連するいくつかの主要な操作は次のとおりです: Push:スタックのトップに要素を追加します。 Pop:スタックからトップの要素を削除して返します。 Peek:削除せずにスタックのトップの要素を表示します。 空かどうかの確認:スタックが要素を持っているかどうかを確認します。 Pythonスタックは、関数呼び出しの追跡、式の評価、およびパーシングアルゴリズムなど、さまざまなアプリケーションで使用されます。 Pythonスタックのメソッド Pythonのスタックは、多くのプログラミング言語と同様に、このデータ構造内のデータの操作を容易にするいくつかの基本的なメソッドと操作が備わっています。以下ではPythonのスタックのメソッドについて説明します: push(item):このメソッドは要素(item)をスタックのトップに追加します。 stack.push(42) pop():pop()メソッドはスタックからトップの要素を削除して取得するために使用されます。この操作により、スタックのサイズが1減少します。スタックが空の場合はエラーが発生します。 top_element = stack.pop() peek():スタックのトップの要素を削除せずに表示するためには、peek()関数が非常に便利です。スタック自体を変更せずに、スタックの頂点の要素を検査するための優れたツールです。 top_element = stack.peek() is_empty():このメソッドはスタックが空かどうかを判定します。スタックに要素がない場合はTrueを返し、それ以外の場合はFalseを返します。 if stack.is_empty(): …

「機械学習プロジェクトのための最高のGitHubの代替品」
「GitHubに似た機能と機能を提供するいくつかのプラットフォームやサイトを見てみましょうこれらは簡単にGitHubに対抗できる堅牢な機能を備えています」

PROsに対する推論
今日は、PROユーザー向けのInferenceを紹介します。これは、最もエキサイティングなモデルのAPIへのアクセス、無料Inference APIの使用に対する改善されたレート制限を提供するコミュニティオファリングです。PROに登録するためには、以下のページをご利用ください。 Hugging Face PROユーザーは、テキスト生成推論による超高速推論の恩恵を受けるパワフルなモデルのカリキュレーションエンドポイントに独占的にアクセスすることができます。これは、すべてのHugging Faceユーザーが利用できる無料の推論APIの上にある特典です。PROユーザーは、これらのモデルに対してより高いレート制限を享受するだけでなく、今日最も優れたモデルへの独占的なアクセスも楽しむことができます。 目次 サポートされているモデル PRO向けInferenceの始め方 アプリケーション Llama 2とCode Llamaでのチャット Code Llamaを使用したコード補完 Stable Diffusion XL 生成パラメータ テキスト生成の制御 画像生成の制御 キャッシング ストリーミング PROに登録する…

「ソフトロボットは自分自身を繰り返し膨張させることで歩く」
コーネル大学とイスラエルのテクニオン-イスラエル工科大学の研究者たちは、内部燃焼によって移動する柔軟な四足ロボットを開発しました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.