Learn more about Search Results エージェント - Page 62

- You may be interested
- 新しいNVIDIA GPUベースのAmazon EC2イン...
- このAI研究は「カンディンスキー1」という...
- 「AIシステムへの9つの一般的な攻撃のタイ...
- 「Amazon Qをご紹介します:ビジネスの卓...
- パンダのプレイブック:7つの必須の包括的...
- NVIDIA H100 GPUがMLPerfベンチマークのデ...
- 「科学者たちが他の種とコミュニケーショ...
- Juliaでの一致するチャットボットの構築
- 『スタートアップでのフルスタックデータ...
- IBMの「Condor」量子コンピュータは1000以...
- 「Pythonでリストをフィルタリングする方...
- 「Protopia AIによる企業LLMアクセラレー...
- ポイントクラウド用のセグメント化ガイド...
- 「生成AIとAmazon Kendraを使用して、エン...
- 「アルマンド・ソラール・レザマが初代デ...

Acme 分散強化学習のための新しいフレームワーク
Acmeは、読みやすく効率的な、研究指向の強化学習(RL)アルゴリズムを構築するためのフレームワークですAcmeのコアには、分散エージェントを含むさまざまな実行規模で実行できるRLエージェントの簡単な記述を可能にする設計思想がありますAcmeのリリースにより、学術研究機関や産業研究所で開発されたさまざまなRLアルゴリズムの結果を、機械学習コミュニティ全体で再現し拡張することが容易になることを目指しています

dm_control 連続制御のためのソフトウェアとタスク
dm_controlソフトウェアパッケージは、関節化されたボディシミュレーションにおける強化学習エージェントのためのPythonライブラリとタスクスイートのコレクションですMuJoCoラッパーは、便利な関数とデータ構造へのバインディングを提供しますPyMJCFとComposerライブラリは、手続き型モデルの操作とタスクの作成を可能にします
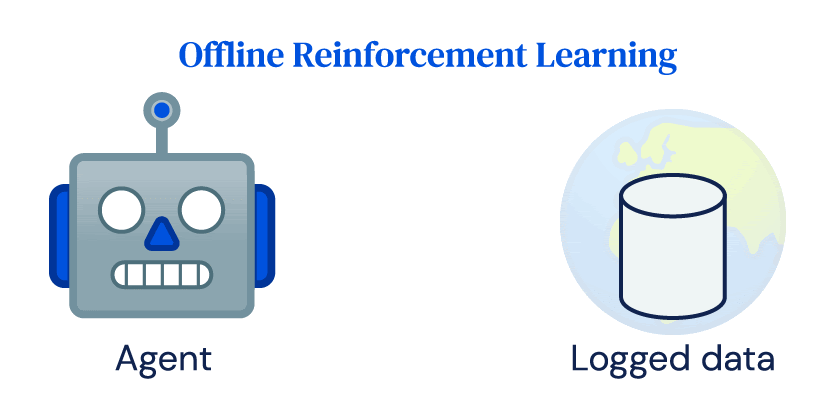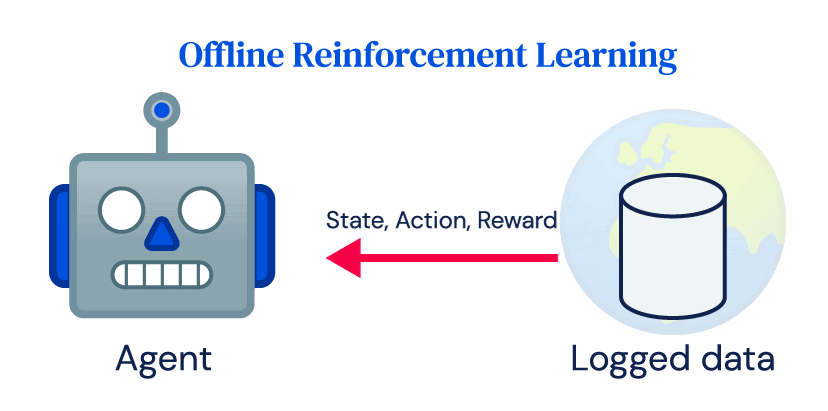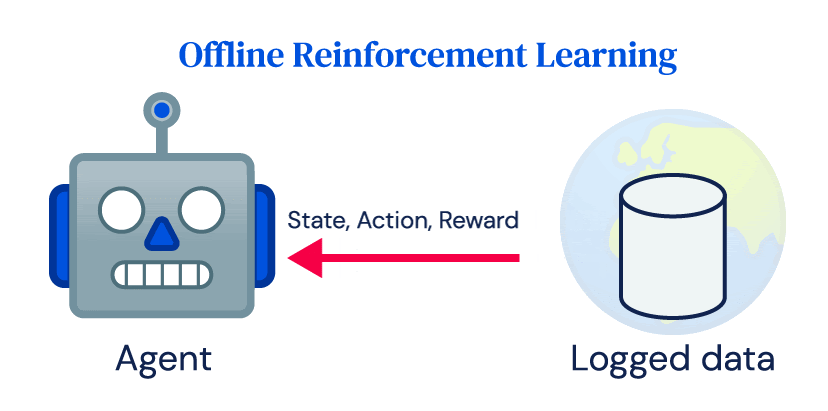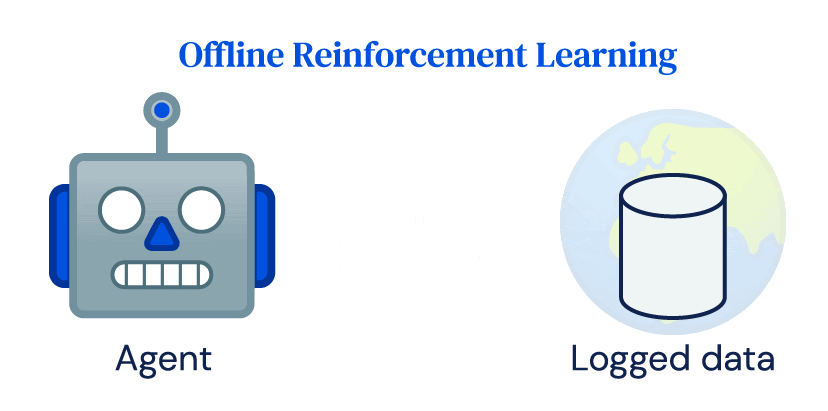
RLアンプラグド:オフライン強化学習のベンチマーク
私たちは、オフラインRL(強化学習)手法の評価と比較を行うためのベンチマークとして「RL Unplugged」というものを提案していますRL Unpluggedには、Atariベンチマークなどのゲームや、DM Control Suiteなどのシミュレートされたモーターコントロール問題など、さまざまなドメインのデータが含まれていますこれらのデータセットには、部分的または完全に観測可能なドメイン、連続または離散のアクションの使用、確率的または確定的なダイナミクスがあるドメインなどが含まれています

行動の組み合わせによる高速強化学習
新しいレシピを学ぶたびに、切る・皮をむく・かき混ぜる方法を再び学ばなければならないとしたらどうでしょうか多くの機械学習システムでは、新たな課題に直面するときに、エージェントは完全にゼロから学ばなければなりませんしかし、明らかなことは、人々はこれよりも効率的に学ぶことができるということです彼らは以前に学んだ能力を組み合わせることができます有限の単語の辞書がほぼ無限の意味を持つ文に再構成されるように、人々は既に持っているスキルを再利用し再組み合わせして新しい課題に取り組むのです

Unityを使用して知能を解決するための利用
私たちは、広く認識され、包括的なゲームエンジンであるUnityの使用方法を紹介し、より多様で複雑な仮想シミュレーションを作成していますこれらの環境を簡素化するために開発されたコンセプトとコンポーネントについて説明しますこれらの環境は、主に強化学習の分野で使用することを意図しています

JAXを使用して研究を加速化する
DeepMindのエンジニアは、ツールの構築、アルゴリズムのスケーリングアップ、そして人工知能(AI)システムのトレーニングとテストのための挑戦的な仮想および物理世界の作成により、私たちの研究を加速させていますこの取り組みの一環として、私たちは常に新しい機械学習ライブラリやフレームワークの評価を行っています

インタラクティブな知能の模倣
最初に、仮想のロボットが移動したり物体を操作したりお互いに話したりすることができる興味深いさまざまな相互作用が行えるシミュレートされた環境であるプレイルームを作成しますプレイルームの寸法はランダム化され、棚、家具、窓やドアのようなランドマーク、子供のおもちゃや日常の物体の配置もランダム化されます環境の多様性により、空間や物体の関係についての推論、参照の曖昧さ、包含性、構築、サポート、遮蔽、部分的な可視性などを含む相互作用が可能となりますプレイルームには2つのエージェントが埋め込まれ、共同意図、協力、プライベートな知識の伝達などを研究するための社会的な要素を提供します

MuZero ルールなしでGo、チェス、将棋、アタリをマスターする
2016年、我々はAlphaGoという初めて人間を囲碁で打ち負かすことのできる人工知能(AI)プログラムを紹介しました2年後、その後継者であるAlphaZeroは、ゼロから囲碁、チェス、将棋をマスターするために学習しましたそして今、学術誌Natureに掲載された論文で、我々はMuZeroを紹介していますこれは汎用アルゴリズムの追求において重要な進展ですMuZeroは、未知の環境で勝利戦略を計画する能力により、ルールを教えられることなく囲碁、チェス、将棋、アタリをマスターします

大規模データ分析のエンジンとしてのゲーム理論
現代のAIシステムは、画像内のオブジェクトを認識したり、タンパク質の3D構造を予測したりするタスクに取り組む際、熱心な学生が試験の準備をするようなアプローチを取ります多くの例題に基づいてトレーニングを行うことで、彼らは時間とともにミスを最小限に抑え、成功を達成しますしかし、これは孤独な取り組みであり、既知の学習の形態の一つに過ぎません学習はまた、他の人々との相互作用や遊びによっても行われます非常に複雑な問題を一人で解決できる個人は稀です問題解決をゲームのような特性で行うことにより、以前のDeepMindの取り組みではAIエージェントがCapture the Flagをプレイしたり、Starcraftでグランドマスターレベルを達成したりすることが可能になりましたこれは、ゲーム理論に基づいたこのような視点が他の基本的な機械学習の問題を解決するのに役立つのではないかと考えさせられます

AI研究によるスポーツ分析の進歩
AI研究を実験室から現実世界に進めるためのテスト環境を作成することは、非常に困難ですAIとの長い関係から、スポーツは興味深い機会を提供していますAIが人間を支援し、多くの動的な相互作用を持つ複数エージェント環境で複雑なリアルタイムの意思決定を行うことができるテストベッドとして、研究者に興奮をもたらします
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.