Learn more about Search Results MPT - Page 60

- You may be interested
- BrainPadがAmazon Kendraを使用して内部の...
- 学生と機関のためのChatGPTプラグインで学...
- 「AIアラインメントの二つの側面」
- 「Stack Overflowは、OverflowAIによって...
- 物理情報を持つDeepONetによる逆問題の解...
- AIモデルの知覚を測定する
- 「大規模言語モデル:現実世界のCXアプリ...
- 「大規模言語モデルを改善するための簡単...
- 深層強化学習の概要
- 「AIの求人市場の黙示録を避けろ:生き残...
- ニューラルネットワークの活性化関数
- 「FastEmbedをご紹介:高速かつ軽量なテキ...
- 「AIを活用した言語学習のためのパーソナ...
- スタビリティAIは、StableChatを紹介しま...
- ファイル共有を簡単にする

「40以上のクールなAIツールをチェックアウトしましょう(2023年8月)」
DeepSwap DeepSwapは、説得力のあるディープフェイクのビデオや画像を作成したい人向けのAIベースのツールです。ビデオ、写真、ミーム、旧作映画、GIFなど、さまざまなコンテンツをリフェイシングして簡単にコンテンツを作成することができます。アプリにはコンテンツの制限がないため、ユーザーはどんなコンテンツでもアップロードすることができます。さらに、初めて製品のサブスクライバーになると、50%オフで利用できます。 Aragon Aragonを使用して、簡単に見栄えの良いプロフェッショナルなヘッドショットを手に入れましょう。最新のAI技術を活用して、瞬時に自分自身の高品質なヘッドショットを作成します!写真スタジオの予約やドレスアップの手間を省きましょう。写真の編集や修正も迅速に行われます。次の仕事を得るためにあなたに優位性を与えるHD写真40枚を受け取りましょう。 AdCreative.ai AdCreative.aiを使用して、広告やソーシャルメディアのゲームを向上させましょう。究極の人工知能ソリューションであるAdCreative.aiを使用すると、数秒で変換率の高い広告やソーシャルメディアの投稿を生成することができます。AdCreative.aiを使って、成功を最大化し、努力を最小限に抑えましょう。 Otter AI 人工知能を活用したOtter.AIは、共有可能で検索可能でアクセス可能で安全なリアルタイムの会議の議事録を提供します。音声を記録し、メモを書き、スライドを自動的にキャプチャし、要約を生成する会議のアシスタントを手に入れましょう。 Notion Notionは、高度なAI技術を活用してユーザーベースを増やすことを目指しています。最新の機能であるNotion AIは、ノートの要約、会議でのアクションアイテムの特定、テキストの作成と変更などのタスクを支援する強力な生成AIツールです。Notion AIは、退屈なタスクを自動化し、ユーザーに提案やテンプレートを提供することで、ワークフローを効率化し、ユーザーエクスペリエンスを簡素化し、改善します。 Docktopus AI Docktopusは、100以上のカスタマイズ可能なテンプレートを備えたAIパワープレゼンテーションツールで、数秒でプロのプレゼンテーションを作成することができます。 SaneBox AIは未来ですが、SaneBoxでは、AIが過去12年間にわたって電子メールを成功裏に支えており、平均ユーザーの週間の受信トレイ管理時間を3時間以上節約しています。 Promptpal AI Promptpal AIは、ChatGPTなどのAIモデルを最大限に活用するための最適なプロンプトをユーザーに提供します。 Quinvio AI…

「Codey:Googleのコーディングタスクのための生成型AI」
イントロダクション OpenAIが導入されて以来、彼らのトップクラスのGPTフレームワークをベースにした数々の生成AIおよび大規模言語モデルがリリースされてきました。その中には、ChatGPTという彼らの生成型対話AIも含まれています。対話型言語モデルの成功に続いて、開発者たちは常に、開発者がアプリケーションのコーディングを開発または支援することのできる大規模言語モデルを作成しようとしています。OpenAIを含む多くの企業が、それらのプログラミング言語を知っているLLM(Large Language Models)によって開発者がアプリケーションをより速く構築できるようにするために、これらのLLMを研究し始めています。GoogleはPaLM 2のファインチューニングモデルであるCodeyを開発しました。Codeyはさまざまなコーディングタスクを実行できるモデルです。 また、こちらも読んでみてください:GoogleがGPT-4効果に対処するためのPaLM 2 学習目標 Codeyの構築方法の理解 Google Cloud PlatformでのCodeyの使用方法の学習 Codeyが受け入れられるプロンプトのタイプの理解 Codey内のさまざまなモデルの探索と関与 Codeyを活用して作業可能なPythonコードを生成する Codeyがコードのエラーを特定して解決する方法のテスト この記事は、データサイエンスブログマラソンの一環として公開されました。 Codeyとは何ですか? Codeyは、最近Googleによって構築およびリリースされた基礎モデルの一つです。CodeyはPaLM 2 Large Language Modelに基づいています。CodeyはPaLM 2…
「データからドルへ:線形回帰の利用」
「データに基づく意思決定はあらゆる業界の企業にとってゲームチェンジャーとなっていますマーケティング戦略の最適化から顧客行動の予測まで、データは未開拓の可能性を開く鍵を握っています...」

「Amazon SageMakerを使用して数千のMLモデルのトレーニングと推論をスケール化する」
数千のモデルのトレーニングとサービスには、堅牢でスケーラブルなインフラストラクチャが必要ですそれがAmazon SageMakerの役割ですSageMakerは、開発者やデータサイエンティストが迅速にMLモデルを構築、トレーニング、展開できる、完全に管理されたプラットフォームです同時に、AWSクラウドインフラストラクチャを使用することで、コスト削減のメリットも提供しますこの記事では、Amazon SageMaker Processing、SageMakerトレーニングジョブ、SageMakerマルチモデルエンドポイント(MME)などのSageMakerの機能を使用して、コスト効果の高い方法で数千のモデルをトレーニングおよびサービスする方法について説明します説明されているソリューションで始めるには、GitHubの関連するノートブックを参照してください

「マルチスレッディングの探求:Pythonにおける並行性と並列実行」
イントロダクション 並行性は、アプリケーションの速度と応答性を向上させるのに役立つ、コンピュータプログラミングの重要な要素です。Pythonでは、マルチスレッドを使用して並行性を作り出す強力な方法があります。マルチスレッドを使用すると、複数のスレッドが単一のプロセス内で同時に実行され、並行実行とシステムリソースの効果的な利用が可能になります。このチュートリアルでは、Pythonのマルチスレッドについて詳しく説明します。アイデア、利点、困難について説明します。スレッドの設定と制御、スレッド間でのデータ共有、スレッドの安全性の確保などを学びます。 また、共有リソースの管理や競合状態の回避のための典型的な罠や、マルチスレッドのプログラムの開発と実装のための推奨事項も学びます。マルチスレッドの理解は、ネットワークアクティビティ、I/Oバウンドタスクを含むアプリケーションの開発、またはプログラムをより応答性のあるものにする試みなど、どのような場面でも有利です。並行実行の潜在能力を最大限に活用することで、パフォーマンスの向上とシームレスなユーザーエクスペリエンスを実現できます。Pythonのマルチスレッドの奥深さに迫り、並行かつ効果的なアプリケーションを作成するためのポテンシャルを引き出す方法を発見するために、私たちと一緒にこの航海に参加してください。 学習目標 このトピックからのいくつかの学習目標は以下の通りです: 1. スレッドとは何か、単一プロセス内でどのように動作し、並行性をどのように実現するかを含め、マルチスレッドの基礎を学びます。Pythonでのマルチスレッドの利点と制限、特にCPUバウンドタスクへのGlobal Interpreter Lock(GIL)の影響について理解します。 2. ロック、セマフォ、条件変数などのスレッド同期技術を探索し、共有リソースの管理と競合状態の回避方法を学びます。スレッドの安全性を確保し、共有データを効率的かつ安全に処理する並行プログラムの設計方法を学びます。 3. Pythonのスレッディングモジュールを使用してスレッドを作成・管理するハンズオンの経験を積みます。スレッドの開始、結合、終了方法を学び、スレッドプールやプロデューサー・コンシューマーモデルなどのマルチスレッドの一般的なパターンを探索します。 この記事はData Science Blogathonの一環として公開されました。 並行性の基本 コンピュータサイエンスの重要な考え方の1つは、並行性と呼ばれ、複数のタスクやプロセスを同時に実行することを指します。これにより、プログラムは複数のタスクを同時に処理することができ、応答性と全体的なパフォーマンスが向上します。並行性は、CPUコア、I/Oデバイス、ネットワーク接続などのシステムリソースを効果的に活用するため、プログラムのパフォーマンス向上に重要です。プログラムは、多くの活動を同時に実行することで、これらのリソースを効率的に使用し、アイドル時間を減らすことができます。これにより、実行が高速化し、効率が向上します。 並行性と並列性の違い 並行性と並列性は関連する概念ですが、明確な違いがあります: 並行性:「並行性」は、システムが多くの活動を同時に実行する能力を指します。並行システムでは、タスクが同時に実行されないかもしれませんが、交互に進むことができます。複数のタスクを同時に調整することが主な目標です。 並列性:一方、並列性は、異なる処理ユニットやコアに割り当てられた複数のタスクを同時に実行することを意味します。並列システムでは、タスクは同時にかつ並列に実行されます。困難をより管理しやすいアクションに分割し、それらを同時に実行してより速い結果を得ることに重点が置かれています。 多くのタスクを同時に実行して、それらが重なり合い、同時に進行するように管理することを並行性と呼びます。一方、並列性は、異なる処理ユニットを使用して多くのタスクを同時に実行することを意味します。Pythonでは、マルチスレッドとマルチプロセスを使用することで、並行性と並列プログラミングを実現することができます。マルチプロセスを使用して多くのプロセスを同時に実行することで並列性を実現し、マルチスレッドを使用して単一のプロセス内で多くのスレッドを実行することで並行性を実現します。 マルチスレッドによる並行性 import threading import…
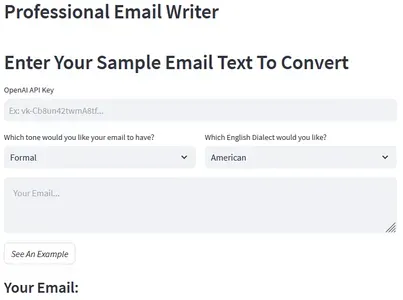
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…
「ゼロから効果的なデータ品質戦略を構築するためのステップバイステップガイド」
データエンジニアとして、私たちは(またはすべきです)提供するデータの品質に責任を持っていますこれは新しいことではありませんが、データプロジェクトに参加するたびに、私は常に同じ質問を自問自答します:完璧は…
「Amazon SageMakerを使用して、生成AIを使ってパーソナライズされたアバターを作成する」
生成AIは、エンターテイメント、広告、グラフィックデザインなど、さまざまな産業で創造プロセスを向上させ、加速させるための一般的なツールとなっていますそれにより、観客によりパーソナライズされた体験が可能となり、最終製品の全体的な品質も向上します生成AIの一つの重要な利点は、ユーザーに対してユニークでパーソナライズされた体験を作り出すことです例えば、[…]

「大規模言語モデルの微調整に関する包括的なガイド」
導入 過去数年間、自然言語処理(NLP)の領域は大きな変革を遂げてきました。それは大規模な言語モデルの登場によるものです。これらの高度なモデルにより、言語翻訳から感情分析、さらには知的なチャットボットの作成まで、幅広いアプリケーションの可能性が開かれました。 しかし、これらのモデルの特筆すべき点はその汎用性です。特定のタスクやドメインに対応するためにこれらを微調整することは、その真の可能性を引き出し、性能を向上させるための標準的な手法となりました。この包括的なガイドでは、基礎から高度な内容まで、大規模な言語モデルの微調整の世界について詳しく掘り下げます。 学習目標 大規模な言語モデルを特定のタスクに適応させるための微調整の概念と重要性を理解する。 マルチタスキング、指示微調整、パラメータ効率的な微調整など、高度な微調整技術を学ぶ。 微調整された言語モデルが産業界を革新する実際の応用例について実践的な知識を得る。 大規模な言語モデルの微調整のステップバイステップのプロセスを学ぶ。 効率的な微調整メカニズムの実装を行う。 標準的な微調整と指示微調整の違いを理解する。 この記事はData Science Blogathonの一部として公開されました。 事前学習済み言語モデルの理解 事前学習済み言語モデルは、通常インターネットから収集された膨大なテキストデータに対して訓練された大規模なニューラルネットワークです。訓練プロセスは、与えられた文やシーケンス内の欠損している単語やトークンを予測することで、モデルに文法、文脈、意味の深い理解を与えます。これらのモデルは数十億の文を処理することで、言語の微妙なニュアンスを把握することができます。 人気のある事前学習済み言語モデルの例には、BERT(Bidirectional Encoder Representations from Transformers)、GPT-3(Generative Pre-trained Transformer 3)、RoBERTa(A Robustly…

「Huggy Lingo:Hugging Face Hubで言語メタデータを改善するための機械学習の利用」
Huggy Lingo: Hugging Face Hubで言語メタデータを改善するために機械学習を使用する 要約: 私たちは機械学習を使用して、言語メタデータのないHubデータセットの言語を検出し、このメタデータを追加するために司書ボットがプルリクエストを行っています。 Hugging Face Hubは、コミュニティが機械学習モデル、データセット、アプリケーションを共有するリポジトリとなっています。データセットの数が増えるにつれて、メタデータは自分のユースケースに適したリソースを見つけるための重要なツールとなっています。 このブログ投稿では、Hugging Face Hubでホストされるデータセットのメタデータを改善するために機械学習を使用したいくつかの初期実験を共有します。 Hub上のデータセットの言語メタデータ Hugging Face Hubには現在約50,000の公開データセットがあります。データセットで使用される言語に関するメタデータは、データセットカードの先頭にあるYAMLフィールドを使用して指定することができます。 すべての公開データセットは、メタデータ内の言語タグを使用して1,716の一意の言語を指定しています。ただし、指定される言語のいくつかは、異なる方法で指定されることになります。たとえば、IMDBデータセットでは、YAMLメタデータにen(英語を示す)が指定されています。 IMDBデータセットのYAMLメタデータのセクション 英語がHub上のデータセットで遥かに最も一般的な言語であることは驚くべきことではありません。Hub上のデータセットの約19%が言語をenとしてリストしています(enのバリエーションを含めない場合であり、実際の割合はおそらくはるかに高いでしょう)。 Hugging Face Hub上のデータセットの頻度とパーセンテージ頻度 英語を除外した場合、言語の分布はどのようになりますか?いくつかの支配的な言語のグループがあり、その後は言語が出現する頻度が比較的滑らかに減少していることがわかります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.