Learn more about Search Results リポジトリ - Page 60

- You may be interested
- 画像中のテーブルの行と列をトランスフォ...
- 新興スタートアップにとってのAIカンファ...
- アップリフトモデリング—クレジットカード...
- 分類器のアンサンブル:投票分類器
- なぜBankrateはAI生成記事を諦めたのか
- このAIペーパーは、さまざまなタスクでCha...
- 「ファクトテーブルとディメンションテー...
- 「LLMモニタリングと観測性 – 責任...
- 「SMARTは、AI、自動化、そして働き方の未...
- 「Amazon SageMakerの最新機能を使用する...
- 「EUはメタバースの世界でリードを取り、...
- 「Quip Python APIs を使用して Quip スプ...
- このAI研究は、質問応答の実行能力におい...
- 「A/Bテストのマスタリング:現実世界のビ...
- 「Q4 Inc.が、Q&Aチャットボットの構...
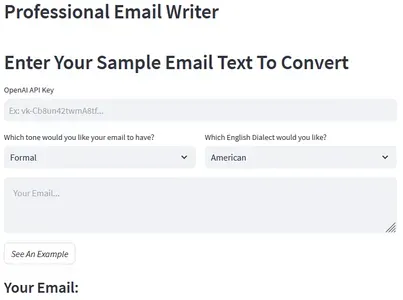
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…

「貪欲であることはどれほど悪いのか?」
私は職業としてデータサイエンティストです私のデータサイエンスのスキルは仕事において非常に重要ですが(定義上)、データサイエンスの概念は仕事以外の問題解決にも役立つことが分かっています!その中でも、一つの…

「生成AIとAmazon Kendraを使用して、エンタープライズスケールでキャプションの作成と画像の検索を自動化する」
Amazon Kendraは、機械学習(ML)によって駆動されるインテリジェントな検索サービスですAmazon Kendraは、ウェブサイトやアプリケーションのための検索を再構築し、従業員や顧客が組織内の複数の場所やコンテンツリポジトリに散らばっているコンテンツを簡単に見つけることができるようにしますAmazon Kendraはさまざまなドキュメントをサポートしています

「SageMaker Distributionは、Amazon SageMaker Studioで利用可能になりました」
SageMaker Distributionは、機械学習(ML)、データサイエンス、データ可視化のための多くの人気のあるパッケージを含んだ、事前に構築されたDockerイメージですこれには、PyTorch、TensorFlow、Kerasなどのディープラーニングフレームワーク、NumPy、scikit-learn、pandasなどの人気のあるPythonパッケージ、およびJupyterLabなどのIDEが含まれますさらに、SageMaker Distributionは、conda、micromamba、pipをPythonのサポートしています

FHEを用いた暗号化された大規模言語モデルに向けて
大規模言語モデル(LLM)は最近、プログラミング、コンテンツ作成、テキスト分析、ウェブ検索、遠隔学習などの多くの分野で生産性を向上させるための信頼性のあるツールとして証明されています。 大規模言語モデルがユーザーのプライバシーに与える影響 LLMの魅力にもかかわらず、これらのモデルによって処理されるユーザークエリに関するプライバシーの懸念が残っています。一方で、LLMの能力を活用することは望ましいですが、他方で、LLMサービスプロバイダーに対して機密情報が漏洩するリスクがあります。医療、金融、法律などの一部の分野では、このプライバシーリスクは問題の原因となります。 この問題への1つの解決策は、オンプレミス展開です。オンプレミス展開では、LLMの所有者がクライアントのマシンにモデルを展開します。これは、LLMの構築に数百万ドル(GPT3の場合は4.6Mドル)かかるため、最適な解決策ではありません。また、オンプレミス展開では、モデルの知的財産(IP)が漏洩するリスクがあります。 Zamaは、ユーザーのプライバシーとモデルのIPの両方を保護できると考えています。このブログでは、Hugging Face transformersライブラリを活用して、モデルの一部を暗号化されたデータ上で実行する方法を紹介します。完全なコードは、このユースケースの例で見つけることができます。 完全同型暗号(FHE)はLLMのプライバシーの課題を解決できます ZamaのLLM展開の課題に対する解決策は、完全同型暗号(FHE)を使用することです。これにより、暗号化されたデータ上で関数の実行が可能となります。モデルの所有者のIPを保護しながら、ユーザーのデータのプライバシーを維持することが可能です。このデモでは、FHEで実装されたLLMモデルが元のモデルの予測の品質を維持していることを示しています。これを行うためには、Hugging Face transformersライブラリのGPT2の実装を適応し、Concrete-Pythonを使用してPython関数をそのFHE相当に変換する必要があります。 図1は、GPT2のアーキテクチャを示しています。これは繰り返し構造を持ち、連続的に適用される複数のマルチヘッドアテンション(MHA)レイヤーから成り立っています。各MHAレイヤーは、モデルの重みを使用して入力をプロジェクションし、アテンションメカニズムを計算し、アテンションの出力を新しいテンソルに再プロジェクションします。 TFHEでは、モデルの重みと活性化は整数で表現されます。非線形関数はプログラマブルブートストラッピング(PBS)演算で実装する必要があります。PBSは、暗号化されたデータ上でのテーブルルックアップ(TLU)演算を実装し、同時に暗号文をリフレッシュして任意の計算を可能にします。一方で、PBSの計算時間は線形演算の計算時間を上回ります。これらの2つの演算を活用することで、FHEでLLMの任意のサブパート、または、全体の計算を表現することができます。 FHEを使用したLLMレイヤーの実装 次に、マルチヘッドアテンション(MHA)ブロックの単一のアテンションヘッドを暗号化する方法を見ていきます。また、このユースケースの例では、完全なMHAブロックの例も見つけることができます。 図2は、基礎となる実装の簡略化された概要を示しています。クライアントは、共有モデルから削除された最初のレイヤーまでの推論をローカルで開始します。ユーザーは中間操作を暗号化してサーバーに送信します。サーバーは一部のアテンションメカニズムを適用し、その結果をクライアントに返します。クライアントはそれらを復号化してローカルの推論を続けることができます。 量子化 まず、暗号化された値上でモデルの推論を実行するために、モデルの重みと活性化を量子化し、整数に変換する必要があります。理想的には、モデルの再トレーニングを必要としない事後トレーニング量子化を使用します。このプロセスでは、FHE互換のアテンションメカニズムを実装し、整数とPBSを使用し、LLMの精度への影響を検証します。 量子化の影響を評価するために、暗号化されたデータ上で1つのLLMヘッドが動作する完全なGPT2モデルを実行します。そして、重みと活性化の量子化ビット数を変化させた場合の精度を評価します。 このグラフは、4ビットの量子化が元の精度の96%を維持していることを示しています。この実験は、約80の文章からなるデータセットを使用して行われます。メトリクスは、元のモデルのロジット予測と量子化されたヘッドモデルを比較して計算されます。 Hugging Face GPT2モデルにFHEを適用する Hugging…

「Huggy Lingo:Hugging Face Hubで言語メタデータを改善するための機械学習の利用」
Huggy Lingo: Hugging Face Hubで言語メタデータを改善するために機械学習を使用する 要約: 私たちは機械学習を使用して、言語メタデータのないHubデータセットの言語を検出し、このメタデータを追加するために司書ボットがプルリクエストを行っています。 Hugging Face Hubは、コミュニティが機械学習モデル、データセット、アプリケーションを共有するリポジトリとなっています。データセットの数が増えるにつれて、メタデータは自分のユースケースに適したリソースを見つけるための重要なツールとなっています。 このブログ投稿では、Hugging Face Hubでホストされるデータセットのメタデータを改善するために機械学習を使用したいくつかの初期実験を共有します。 Hub上のデータセットの言語メタデータ Hugging Face Hubには現在約50,000の公開データセットがあります。データセットで使用される言語に関するメタデータは、データセットカードの先頭にあるYAMLフィールドを使用して指定することができます。 すべての公開データセットは、メタデータ内の言語タグを使用して1,716の一意の言語を指定しています。ただし、指定される言語のいくつかは、異なる方法で指定されることになります。たとえば、IMDBデータセットでは、YAMLメタデータにen(英語を示す)が指定されています。 IMDBデータセットのYAMLメタデータのセクション 英語がHub上のデータセットで遥かに最も一般的な言語であることは驚くべきことではありません。Hub上のデータセットの約19%が言語をenとしてリストしています(enのバリエーションを含めない場合であり、実際の割合はおそらくはるかに高いでしょう)。 Hugging Face Hub上のデータセットの頻度とパーセンテージ頻度 英語を除外した場合、言語の分布はどのようになりますか?いくつかの支配的な言語のグループがあり、その後は言語が出現する頻度が比較的滑らかに減少していることがわかります。…

再抽出を用いた統計的実験
「Pythonを使用したA/B仮説検定とパワー推定における順列/ブートストラップ法」

創造力を解き放つ:ジェネレーティブAIとAmazon SageMakerがビジネスを支援し、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
広告代理店は、生成AIとテキストから画像を生成する基礎モデルを使用して、革新的な広告クリエイティブとコンテンツを作成することができますこの記事では、Amazon SageMakerを使用して既存のベース画像から新しい画像を生成する方法を示しますAmazon SageMakerは、スケーラブルなMLモデルを構築、トレーニング、展開するための完全な管理サービスですこのソリューションを使用することで、大規模なビジネスでも[…]

「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
現在の急速に進化する医療の現場では、医師は介護者のメモ、電子健康記録、画像報告書など、さまざまな情報源から大量の臨床データに直面しています患者のケアには不可欠なこの情報の富は、医療専門家にとっても圧倒的で時間のかかるものになります効率的に要約し、抽出することは、

「SD-Small」と「SD-Tiny」の知識蒸留コードと重みのオープンソース化
近年、AIコミュニティでは、Falcon 40B、LLaMa-2 70B、Falcon 40B、MPT 30Bなど、より大きく、より高性能な言語モデルの開発が著しく進んでいます。また、SD2.1やSDXLなどの画像領域のモデルでも同様です。これらの進歩は、AIが達成できることの境界を押し広げ、高度に多様かつ最先端の画像生成および言語理解の能力を可能にしています。しかし、これらのモデルのパワーと複雑さを驚嘆しながらも、AIモデルをより小さく、効率的に、そしてよりアクセスしやすくするという成長するニーズの認識が不可欠です。特に、オープンソース化によってこれらのモデルを利用可能にすることが求められています。 Segmindでは、生成型AIモデルをより速く、安価にする方法に取り組んできました。昨年、voltaMLという加速されたSD-WebUIライブラリをオープンソース化しました。これはAITemplate/TensorRTベースの推論高速化ライブラリであり、推論速度が4~6倍向上しました。生成モデルをより速く、小さく、安価にする目標に向けて、私たちは圧縮されたSDモデル「SD-Small」と「SD-Tiny」の重みとトレーニングコードをオープンソース化しています。事前学習済みのチェックポイントはHuggingfaceで利用可能です🤗 知識蒸留 私たちの新しい圧縮モデルは、知識蒸留(KD)技術に基づいてトレーニングされており、この論文に大きく依存しています。著者は、いくつかのUNetレイヤーを削除し、学習された生徒モデルの重みを説明したブロック除去知識蒸留法について説明しています。論文で説明されているKDの手法を使用して、圧縮モデル2つをトレーニングしました。🧨 diffusersライブラリを使用してトレーニングした「Small」と「Tiny」は、ベースモデルと比較してそれぞれ35%と55%少ないパラメータを持っており、ベースモデルと同様の画像品質を実現しています。私たちはこのリポジトリで蒸留コードをオープンソース化し、Huggingfaceで事前学習済みのチェックポイントを提供しています🤗 ニューラルネットワークの知識蒸留トレーニングは、先生が生徒をステップバイステップで指導するのと似ています。大きな先生モデルは大量のデータで事前トレーニングされ、その後、より小さなモデルは小規模なデータセットでトレーニングされ、クラシカルなトレーニングと共に、大きなモデルの出力を模倣するようになります。 この特定の種類の知識蒸留では、生徒モデルは通常の拡散タスクである純粋なノイズからの画像の復元を行うようにトレーニングされますが、同時に、モデルは大きな先生モデルの出力と一致するようになります。出力の一致はU-netの各ブロックで行われるため、モデルの品質はほとんど保たれます。したがって、前述のアナロジーを使用すると、このような蒸留中、生徒は質問と回答だけでなく、先生の回答からも学び、回答に至る方法もステップバイステップで学ぼうとします。これを達成するために、損失関数には3つのコンポーネントがあります。まず、ターゲット画像の潜在変数と生成された画像の潜在変数の間の従来の損失です。次に、先生が生成した画像の潜在変数と生徒が生成した画像の潜在変数の間の損失です。そして最後に、最も重要なコンポーネントであるフィーチャーレベルの損失です。これは、先生と生徒の各ブロックの出力の間の損失です。 これらすべてを組み合わせて、知識蒸留トレーニングが成り立ちます。以下は、論文「テキストから画像への拡散モデルのアーキテクチャ圧縮について」(Shinkookら)からのアーキテクチャの例です。 画像はShinkookらによる論文「テキストから画像への拡散モデルのアーキテクチャ圧縮について」から取得 私たちは、ベースとなる先生モデルとしてRealistic-Vision 4.0を選び、高品質な画像の説明を持つLAION Art Aestheticデータセットでトレーニングしました(画像スコアが7.5以上のもの)。論文とは異なり、私たちはSmallモードでは100Kステップ、Tinyモードでは125Kステップで1M枚の画像で2つのモデルをトレーニングしました。蒸留トレーニングのコードはこちらで見つけることができます。 モデルの使用方法 モデルは🧨 diffusersのDiffusionPipelineを使用して利用できます from diffusers import DiffusionPipeline…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.