Learn more about Search Results エージェント - Page 60

- You may be interested
- マシンラーニングにおいて未分類データを...
- FAANG企業に入社するのはどの程度難しいの...
- AIを使ってYouTubeショートを作成する
- 特徴変換:PCAとLDAのチュートリアル
- 非教師あり学習シリーズ:階層クラスタリ...
- YouTubeと協力しています
- 「ChatGPTとAIでお金を稼ぐ3つの方法」
- 「最適化によるAIトレーニングにおける二...
- AIとMLによる株式取引の革命:機会と課題
- データサイエンス予測の検査:個別+負の...
- BigBirdのブロック疎な注意機構の理解
- アリババの研究者は、Qwen-VLシリーズを紹...
- 「NVIDIAとScalewayがヨーロッパのスター...
- 「線形回帰モデルを用いた勾配降下法の実装」
- 「エンジニアは失敗を見つける使命に就い...

Hugging FaceでのDecision Transformersの紹介 🤗
🤗 Hugging Faceでは、ディープ強化学習の研究者や愛好家向けのエコシステムに貢献しています。最近では、Stable-Baselines3などのディープRLフレームワークを統合しました。 そして、今日は喜んでお知らせします。オフライン強化学習手法であるDecision Transformerを🤗 transformersライブラリとHugging Face Hubに統合しました。ディープRLの分野でアクセシビリティを向上させるための興味深い計画があり、これからの数週間や数ヶ月でそれを共有できることを楽しみにしています。 オフライン強化学習とは何ですか? Decision Transformerの紹介 🤗 TransformersでDecision Transformerを使用する まとめ 次は何ですか? 参考文献 オフライン強化学習とは何ですか? ディープ強化学習(RL)は、意思決定エージェントを構築するためのフレームワークです。これらのエージェントは、試行錯誤を通じて環境との相互作用を通じて最適な行動(ポリシー)を学び、報酬を受け取ることでユニークなフィードバックを得ることを目指します。 エージェントの目標は、累積報酬であるリターンを最大化することです。なぜなら、RLは報酬の仮説に基づいているからです:すべての目標は、期待累積報酬を最大化することとして記述できるからです。 ディープ強化学習エージェントは、バッチの経験を使用して学習します。問題は、どのようにしてそれを収集するかです: オンラインとオフラインの設定での強化学習の比較、この投稿からの図 オンライン強化学習では、エージェントは直接データを収集します:環境との相互作用によってバッチの経験を収集します。その後、この経験を即座に(または一部のリプレイバッファを介して)使用して学習します(ポリシーを更新します)。 しかし、これはエージェントを実際の世界で直接トレーニングするか、シミュレータを持っている必要があることを意味します。もしそれがなければ、環境の複雑な現実をどのように反映させるか(環境での複雑な現実を反映させる方法は?)という非常に複雑な問題、高価な問題、そして安全性の問題があります。なぜなら、シミュレータに欠陥があれば、競争上の優位性を提供する場合はエージェントがそれを悪用する可能性があるからです。…

機械学習の専門家 – ルイス・タンストール
🤗 マシンラーニングエキスパートへようこそ – ルイス・タンストール こんにちは、みなさん!マシンラーニングエキスパートへようこそ。私は司会のブリトニー・ミュラーです。今日のゲストはルイス・タンストールさんです。ルイスさんはHugging Faceのマシンラーニングエンジニアで、トランスフォーマーを使ってビジネスプロセスを自動化し、MLOpsの課題を解決するための取り組みを行っています。 ルイスさんは、NLP、トポロジカルデータ解析、時系列の領域でスタートアップや企業向けに機械学習アプリケーションを開発してきました。 ルイスさんは、彼の新しい本、トランスフォーマー、大規模モデルの評価、MLエンジニアがより高速なレイテンシとスループットを目指すための最適化方法などについて話します。 以前は理論物理学者であり、仕事以外ではギターを弾いたり、トレイルランニングをしたり、オープンソースプロジェクトに貢献したりすることが好きです。 この楽しくて素晴らしいエピソードを紹介するのをとても楽しみにしています!ここで私がルイス・タンストールさんとの会話をお届けします。 注:転写はわかりやすい読みやすい体験を提供するために、わずかに修正/再フォーマットされています。 ようこそ、ルイスさん!お忙しい中、私との素晴らしいお仕事についてお話しいただき、本当にありがとうございます! ルイス: ありがとうございます、ブリトニーさん。こちらこそ、ここにいさせていただけて光栄です。 簡単な自己紹介と、Hugging Faceへの経緯について教えていただけますか? ルイス: 私をHugging Faceに導いたものはトランスフォーマーです。2018年、私はスイスのスタートアップでトランスフォーマーを使って仕事をしていました。最初のプロジェクトは、テキストを入力してそのテキスト内の質問に答えを見つけるためのモデルを訓練する質問応答のタスクでした。 当時のライブラリは「pytorch-pretrained-bert」という名前で、いくつかのスクリプトを持つ非常に特化したコードベースでした。私はトランスフォーマーについて何が起こっているのか全くわからず、オリジナルの「Attention Is All You Need」という論文を読んでも理解できませんでした。そこで他の学習リソースを探し始めました。…

教育のためのHugging Faceをご紹介します 🤗
機械学習がソフトウェア開発の圧倒的な割合を占めること、非技術的な人々がますますAIシステムに触れることを考えると、AIの主な課題の1つは従業員のスキルを適応・向上させることです。また、AIの倫理的および重要な問題を積極的に考慮するために教育スタッフをサポートする必要があります。 Hugging Faceは機械学習を民主化するオープンソース企業として、世界中のあらゆるバックグラウンドの人々に教育を提供することが重要だと考えています。 私たちは2022年3月にMLデモクラタイゼーションツアーを開始し、Hugging Faceの専門家が16カ国の1000人以上の学生に対して実践的な機械学習クラスを教えました。新しい目標は、「2023年末までに500万人に機械学習を教える」ことです。 このブログ記事では、教育に関する目標達成方法の概要を提供します。 🤗 すべての人のための教育 🗣️ 私たちの目標は、機械学習の可能性と限界を誰にでも理解してもらうことです。これによって、これらの技術の応用が社会全体にとって正味の利益につながる方向へ進化すると信じています。 私たちの既存の取り組みの一部の例: 私たちはMLモデルのさまざまな使い方(要約、テキスト生成、物体検出など)を非常にわかりやすく説明しています。 モデルページのウィジェットを通じて、誰でも直接ブラウザでモデルを試すことができるようにしています。そのため、それを行うための技術的なスキルの必要性を低下させています(例)。 システムで特定された有害なバイアスについてドキュメント化し、警告しています(GPT-2など)。 誰でも1クリックでMLの潜在能力を理解できるオープンソースのMLアプリを作成するためのツールを提供しています。 🤗 初心者向けの教育 🗣️ 私たちは、オンラインコース、実践的なワークショップ、その他の革新的な技術を提供することで、機械学習エンジニアになるためのハードルを下げたいと考えています。 私たちは自然言語処理(NLP)やその他のドメインについての無料コースを提供しています(近日中に)。これらのコースでは、Hugging Faceエコシステムの無料ツールやライブラリを使用して学ぶことができます。このコースの最終目標は、(ほぼ)どんな機械学習の問題にもTransformerを適用する方法を学ぶことです! 私たちはDeep Reinforcement Learningについての無料コースを提供しています。このコースでは、理論と実践でDeep…

深層強化学習の概要
Hugging FaceとのDeep Reinforcement Learningクラスの第1章 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 人工知能の最も魅力的なトピックへようこそ: Deep Reinforcement Learning(深層強化学習) Deep RLは、エージェントが行動を実行し、結果を観察することで、環境内でどのように振る舞うかを学習する機械学習の一種です。…

Q-学習入門 第1部への紹介
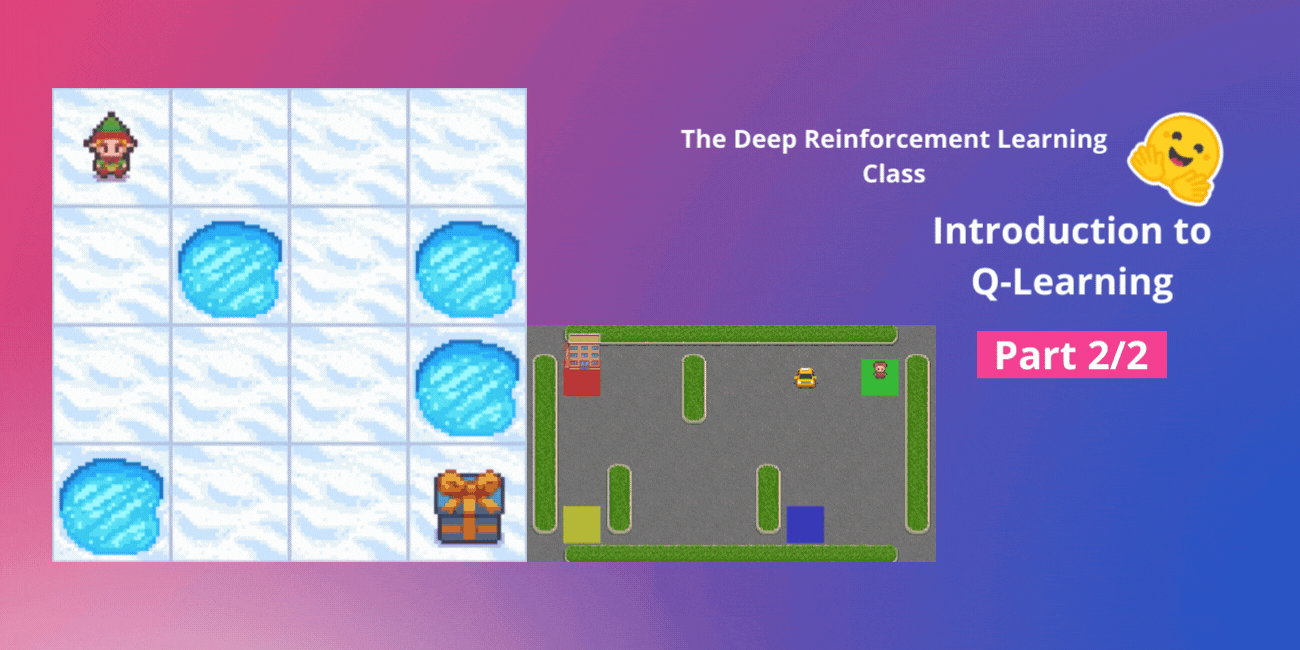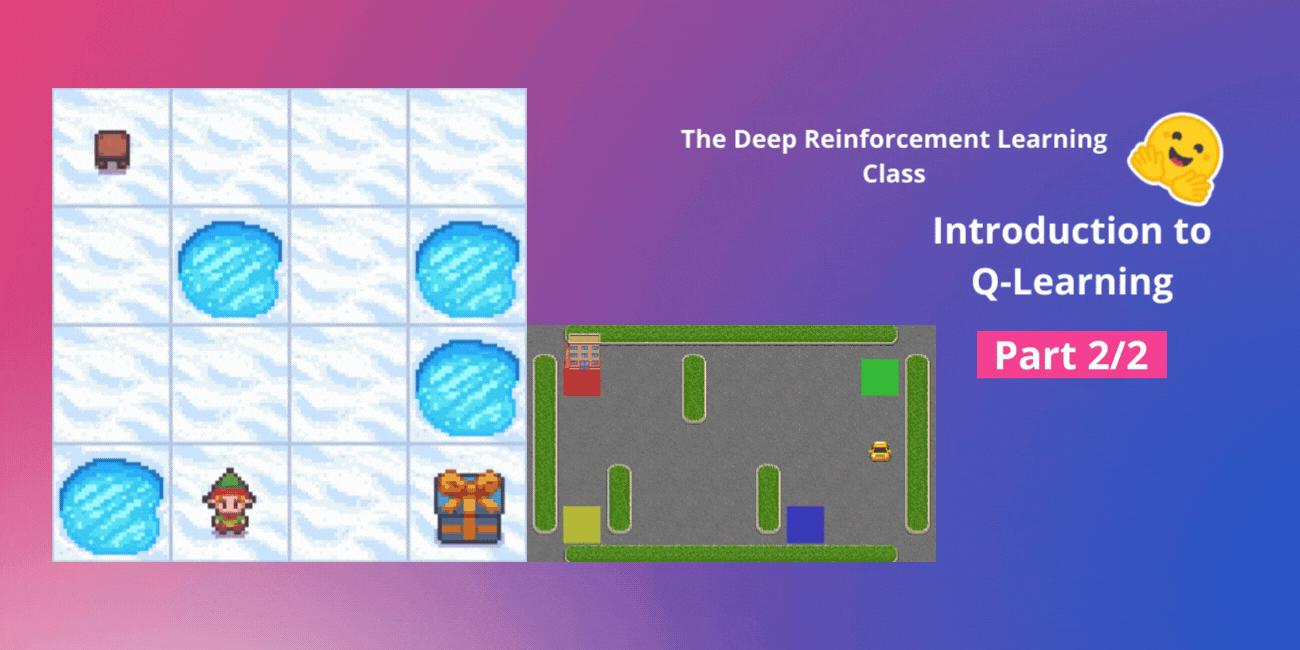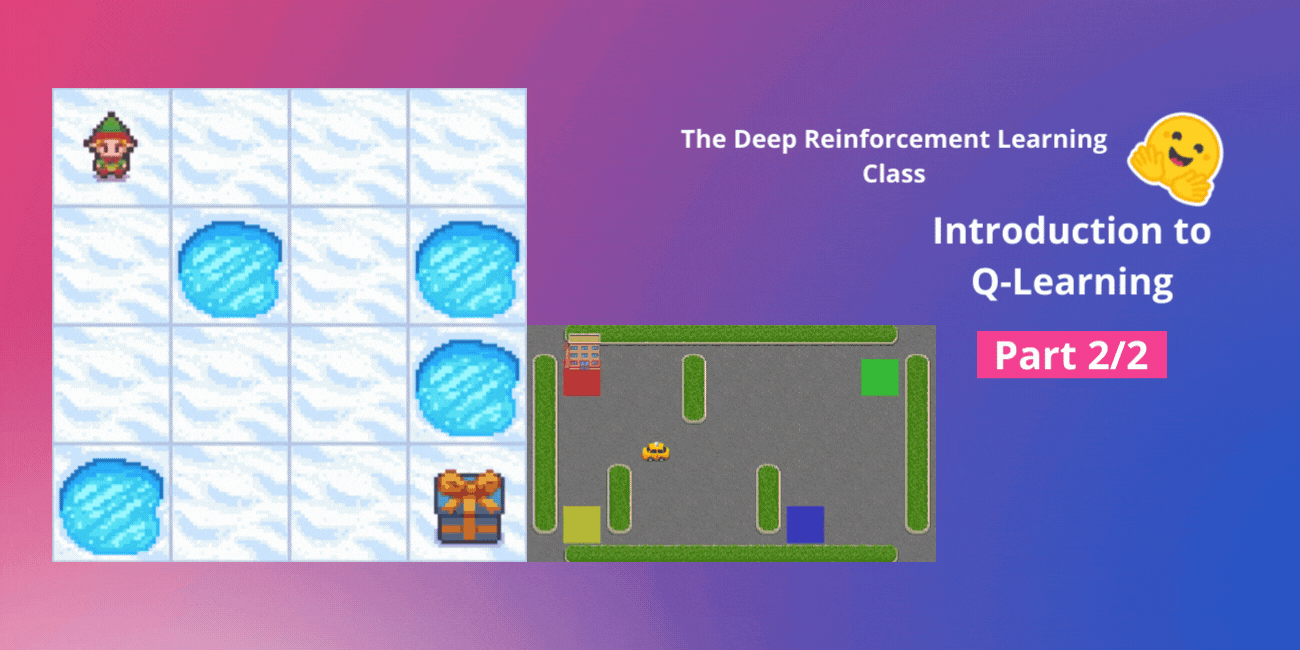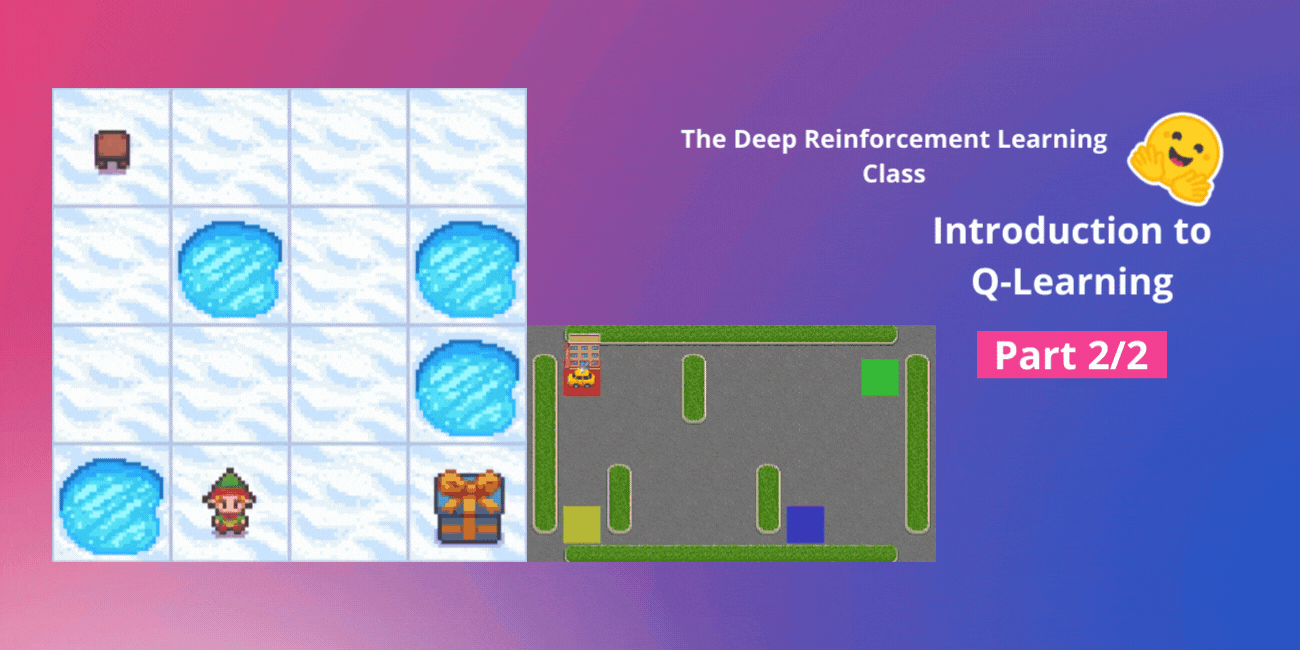
ハギングフェイスと一緒に行うディープ強化学習クラスのユニット2、パート1 🤗 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 このクラスの第1章では、強化学習(RL)、RLプロセス、およびRL問題を解決するための異なる手法について学びました。また、最初のランダーエージェントをトレーニングして、月面に正しく着陸させ、Hugging Face Hubにアップロードしました。 今日は、強化学習のメソッドの一つである価値ベースの手法について詳しく掘り下げて、最初のRLアルゴリズムであるQ-Learningを学びます。 また、スクラッチから最初のRLエージェントを実装し、2つの環境でトレーニングします: Frozen-Lake-v1(滑りにくいバージョン):エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)へ移動する必要があります。 自動タクシーは、都市をナビゲートすることを学び、乗客をポイントAからポイントBまで輸送する必要があります。 このユニットは2つのパートに分かれています: 第1部では、価値ベースの手法とモンテカルロ法と時間差学習の違いについて学びます。 そして、第2部では、最初のRLアルゴリズムであるQ-Learningを学び、最初のRLエージェントを実装します。 このユニットは、Deep Q-Learning(ユニット3)で作業できるようになるためには基礎となるものです。これは最初のDeep…
Q-Learningの紹介 パート2/2
ディープ強化学習クラスのユニット2、パート2(Hugging Faceと共に) ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 このユニットの第1部では、価値ベースの手法とモンテカルロ法と時差学習の違いについて学びました。 したがって、第2部では、Q-Learningを学び、スクラッチから最初のRLエージェントであるQ-Learningエージェントを実装し、2つの環境でトレーニングします: 凍った湖 v1 ❄️:エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)に移動する必要があります。 自律運転タクシー 🚕:エージェントは都市をナビゲートし、乗客を地点Aから地点Bに輸送する必要があります。 このユニットは、ディープQ-Learning(ユニット3)で作業を行うためには基礎となるものです。 では、始めましょう! 🚀 Q-Learningの紹介 Q-Learningとは?…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

ポリシーグラディエント(Policy Gradient)によるPyTorchの実装
Deep Reinforcement Learning Classのユニット5、Hugging Faceと共に 🤗 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 前のユニットでは、Deep Q-Learningについて学びました。この価値ベースのDeep…

アドバンテージアクタークリティック(A2C)
ハギングフェイスとのDeep Reinforcement Learningクラスのユニット7 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ユニット5では、最初のPolicy-BasedアルゴリズムであるReinforceについて学びました。Policy-Basedメソッドでは、価値関数を使用せずにポリシーを直接最適化することを目指します。具体的には、ReinforceはPolicy-Gradientメソッドと呼ばれるPolicy-Basedメソッドのサブクラスの一部であり、Gradient Ascentを使用して最適なポリシーの重みを推定することでポリシーを直接最適化します。 Reinforceはうまく機能することを見ました。ただし、リターンを推定するためにモンテカルロサンプリングを使用するため、ポリシーグラデーションの推定にはかなりの分散があります。 ポリシーグラデーションの推定はリターンの最も急速な増加の方向です。つまり、良いリターンにつながるアクションのポリシーウェイトを更新する方法です。モンテカルロの分散は、このユニットでさらに詳しく学びますが、分散を緩和するために多くのサンプルが必要なため、トレーニングが遅くなります。 今日はActor-Criticメソッドを学びます。これはバリューベースとポリシーベースのメソッドを組み合わせたハイブリッドアーキテクチャで、トレーニングを安定化させるためのものです: エージェントの行動方法を制御するアクター(ポリシーベースのメソッド) 取られたアクションの良さを測る評価者(バリューベースのメソッド)…

プロキシマルポリシーオプティマイゼーション(PPO)
Deep Reinforcement Learning ClassのUnit 8、Hugging Faceと共に 🤗 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 前のユニットでは、Advantage…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.