Learn more about Search Results subplots - Page 5

- You may be interested
- 「Ai X ビジネスおよびイノベーションサミ...
- 「NVIDIAスタジオ」で美しく写実的なフー...
- AIが脳の液体の流れを示すのに役立つ
- 大規模言語モデル、MirrorBERT — モデルを...
- 「Google DeepMindの研究者たちは、PROmpt...
- 「AIブーム:小規模ビジネスのための生成A...
- 『分析チームとしての緊急性と持続可能性...
- Stack Overflowで最もよく尋ねられるPytho...
- 「感覚AIの公開:人工汎用知能(AGI)の実...
- チャートの推論に基づくモデルの基盤
- 「自然言語処理の技術比較:RNN、トランス...
- 「決定木は回帰問題をどのように解決する...
- ソースフリーのドメイン適応における壁の...
- 「AIと働き方の未来:AI時代における労働...
- 「強化学習を使用してLeetcodeの問題を解...

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

CLIPSegによるゼロショット画像セグメンテーション
このガイドでは、🤗 transformersを使用して、ゼロショットの画像セグメンテーションモデルであるCLIPSegを使用する方法を紹介します。CLIPSegは、ロボットの知覚、画像補完など、さまざまなタスクに使用できるラフなセグメンテーションマスクを作成します。より正確なセグメンテーションマスクが必要な場合は、Segments.aiでCLIPSegの結果を改善する方法も紹介します。 画像セグメンテーションは、コンピュータビジョンの分野でよく知られたタスクです。これにより、コンピュータは画像内の物体を知るだけでなく(分類)、画像内の物体の位置を知ることもできます(検出)、さらには物体の輪郭も知ることができます。物体の輪郭を知ることは、ロボット工学や自動運転などの分野では重要です。たとえば、ロボットは物体の形状を正しく把握するために、その形状を知る必要があります。セグメンテーションは、画像補完と組み合わせることもでき、ユーザーが画像のどの部分を置き換えたいかを説明することができます。 ほとんどの画像セグメンテーションモデルの制限の1つは、固定されたカテゴリのリストでのみ機能するということです。たとえば、オレンジでトレーニングされたセグメンテーションモデルを使用して、リンゴをセグメント化することはできません。セグメンテーションモデルに追加のカテゴリを教えるには、新しいカテゴリのデータをラベル付けし、新しいモデルをトレーニングする必要があります。これは費用と時間がかかる場合があります。しかし、さらなるトレーニングなしにほとんどどのような種類のオブジェクトでもセグメント化できるモデルがあったらどうでしょうか?それがCLIPSeg、ゼロショットのセグメンテーションモデルが達成するものです。 現時点では、CLIPSegにはまだ制限があります。たとえば、モデルは352 x 352ピクセルの画像を使用するため、出力はかなり低解像度です。したがって、モダンなカメラの画像を使用すると、ピクセルパーフェクトな結果を期待することはできません。より正確なセグメンテーションを必要とする場合、前のブログ記事で示したように、最新のセグメンテーションモデルを微調整することができます。その場合、CLIPSegを使用してラフなラベルを生成し、Segments.aiなどのラベリングツールでそれらを調整することができます。それについて説明する前に、まずCLIPSegの動作を見てみましょう。 CLIP: CLIPSegの背後にある魔法のモデル CLIP(Contrastive Language–Image Pre-training)は、OpenAIが2021年に開発したモデルです。CLIPに画像またはテキストの一部を与えると、CLIPは入力の抽象的な表現を出力します。この抽象的な表現、または埋め込みとも呼ばれるものは、実際にはベクトル(数値のリスト)です。このベクトルは、高次元空間のポイントと考えることができます。CLIPは、似たような画像とテキストの表現も似たようにするようにトレーニングされています。つまり、画像とそれに合致するテキストの説明を入力すると、画像とテキストの表現が似ている(つまり、高次元のポイントが近くにある)ことになります。 最初はあまり役に立たないように思えるかもしれませんが、実際には非常に強力です。例えば、CLIPを使用して訓練されたことがないタスクで画像を分類する方法を簡単に見てみましょう。画像を分類するには、画像と選択肢となる異なるカテゴリをCLIPに入力します(例えば、画像と「りんご」、「オレンジ」などの単語を入力します)。CLIPは、画像と各カテゴリの埋め込みを返します。今、画像の埋め込みに最も近いカテゴリの埋め込みを確認するだけです。これで完了です!まるで魔法のようですね。 CLIPを使用した画像分類の例(出典)。 さらに、CLIPは分類だけでなく、画像検索(これが分類と似ていることがわかりますか?)、テキストから画像への変換モデル(DALL-E 2はCLIPで動作します)、物体検出(OWL-ViT)などにも使用できます。そして、私たちにとって最も重要なのは、画像セグメンテーションです。これでCLIPが機械学習において本当に画期的なものである理由がお分かりいただけるでしょう。 CLIPが非常にうまく機能する理由は、モデルがテキストのキャプション付きの膨大なデータセットでトレーニングされたからです。そのデータセットには、インターネットから取得した4億枚の画像テキストペアが含まれています。これらの画像にはさまざまなオブジェクトや概念が含まれており、CLIPはそれぞれのオブジェクトに対して表現を生成するのに優れています。 CLIPSeg: CLIPによる画像セグメンテーション CLIPSegは、CLIPの表現を使用して画像セグメンテーションマスクを作成するモデルです。Timo LüddeckeさんとAlexander Eckerさんによって公開されました。彼らは、CLIPモデルを凍結したまま、TransformerベースのデコーダをCLIPモデルの上にトレーニングすることで、ゼロショット画像セグメンテーションを達成しました。デコーダは、画像のCLIP表現とセグメンテーションしたい対象のCLIP表現を入力として受け取り、これらの2つの入力を使用して、CLIPSegデコーダは2値のセグメンテーションマスクを作成します。より詳しく言うと、デコーダはセグメンテーションしたい画像の最終的なCLIP表現だけでなく、CLIPのいくつかのレイヤーの出力も使用します。 ソース デコーダは、PhraseCutデータセットでトレーニングされています。このデータセットには、340,000以上のフレーズと対応する画像セグメンテーションマスクが含まれています。著者たちはまた、データセットのサイズを拡大するためにさまざまな拡張方法も試みました。ここでの目標は、データセットに存在するカテゴリだけでなく、未知のカテゴリもセグメンテーションできるようにすることです。実験の結果、デコーダは未知のカテゴリにも対応できることが示されています。…
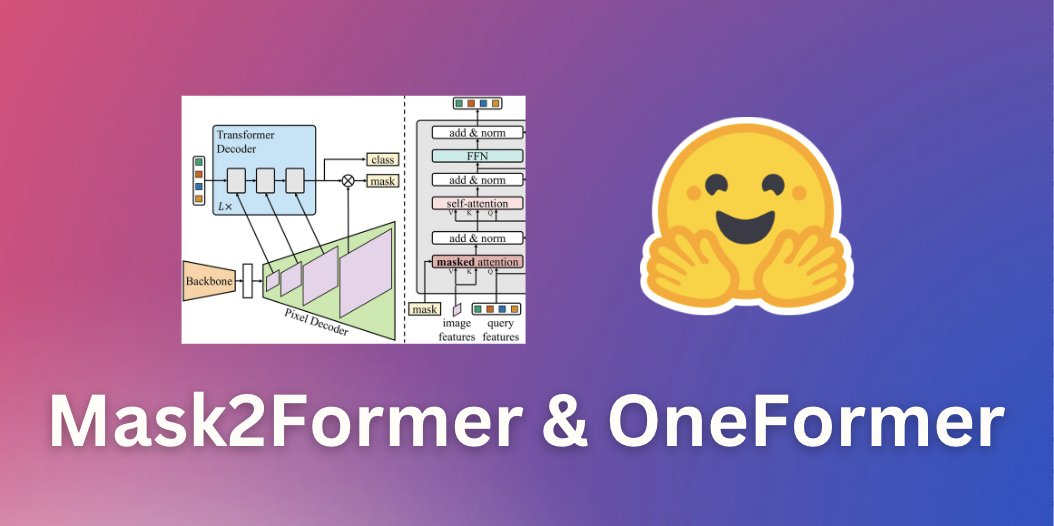
マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。 画像セグメンテーション 画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。 画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。 インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。 パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。 以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。 ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。 ユニバーサル画像セグメンテーション 幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。 Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。 要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。 Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。 TransformersでのMask2FormerとOneFormerの推論 Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。 from…

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…
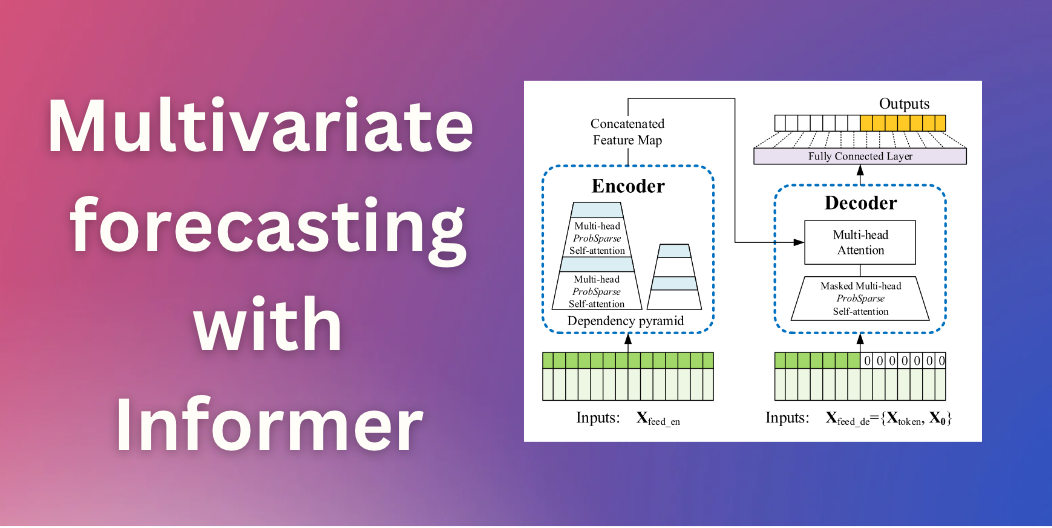
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

Pythonを使用した画像処理の紹介
当シリーズの第2エピソードの第3部へようこそ!前のパートでは、フーリエ変換とホワイトバランス技術について説明しましたが、今回は...
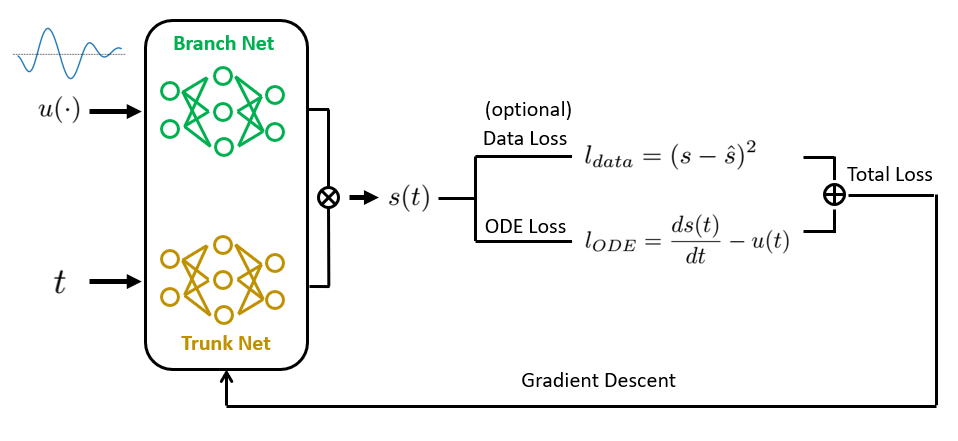
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.