Learn more about Search Results Word2vec - Page 5

- You may be interested
- 「中国の科学者が驚異的な新記録を樹立し...
- 物議を醸している:GrokがOpenAIのコード...
- この中国のAI研究は、マルチモーダルな大...
- CycleGANによる画像から画像への変換
- 「2024年の包括的なNLP学習パス」
- 一貫性のあるAIビデオエディターが登場し...
- 大規模データ分析のエンジンとしてのゲー...
- このAI論文では、アマゾンの最新の機械学...
- わかりやすいYOLOv8 Eigen-CAMを使ったYOL...
- 「10 Best AI医療書記」
- 「AIによるPaytmによるインド経済の保護:...
- 「ビジュアルで高速にMLパイプラインを構...
- UCバークレーとスタンフォード大学の研究...
- MetaGPT 現在利用可能な最高のAIエージェ...
- ランナーの疲労検知のための時間系列分類 ...

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…
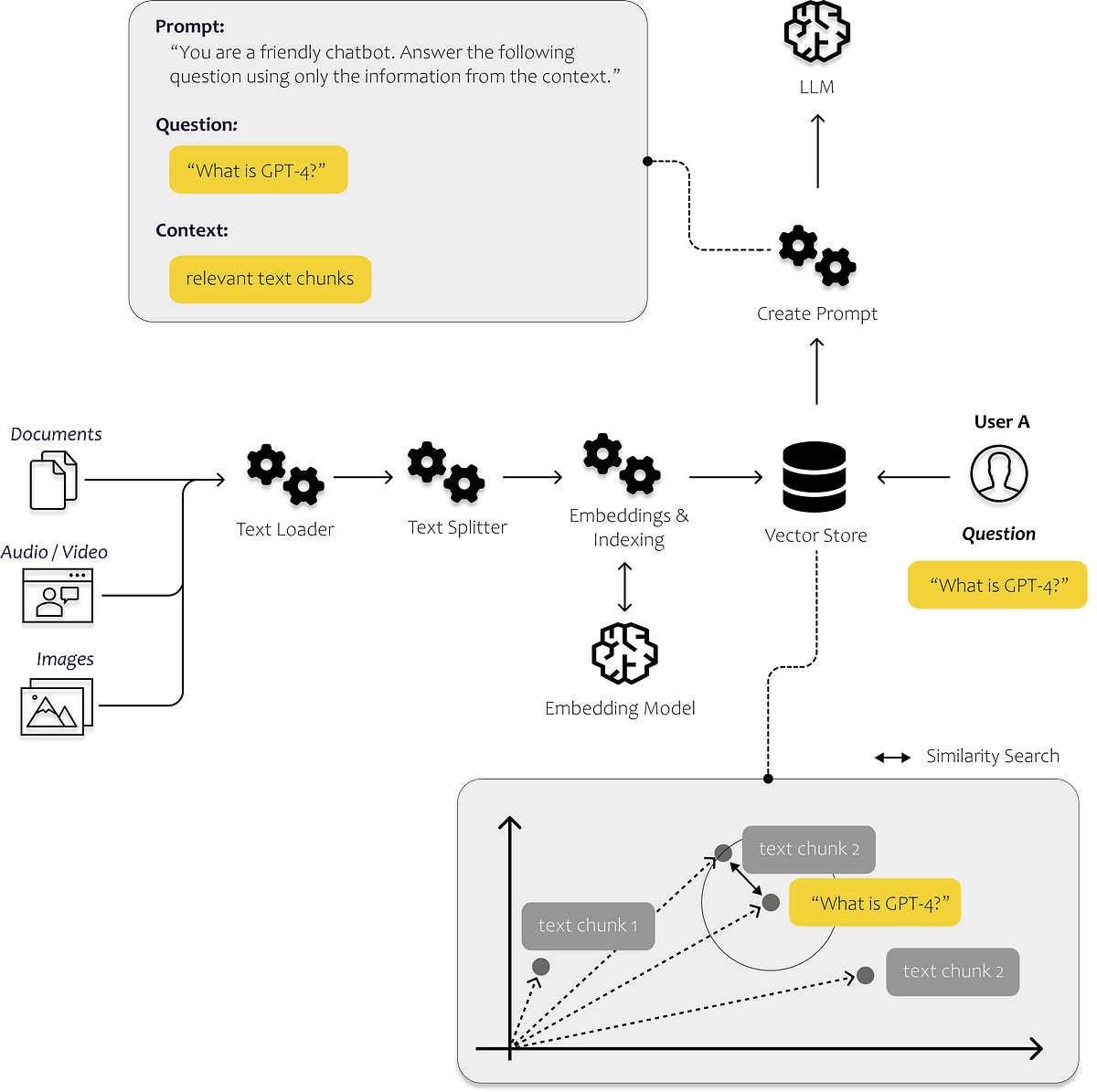
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.