Learn more about Search Results Transformer - Page 5

- You may be interested
- 「NExT-GPTを紹介します:エンドツーエン...
- 『検索増強生成(RAG)の評価に向けた3ス...
- 「夢の彫刻:DreamTimeは、テキストから3D...
- 「集団行動のデコード:アクティブなベイ...
- 「アマゾンベッドロックを使った商品説明...
- ダブルマシンラーニングの簡素化:パート2...
- 「解釈力を高めたk-Meansクラスタリングの...
- 「AIと芸術における可能性と破壊」
- テックの雇用削減はAI産業について何を示...
- 「Ntropyの共同創設者兼CEO、ナレ・ヴァル...
- イメージの意味的なセグメンテーションに...
- 「NVIDIAは、エンタープライズや開発者向...
- 「エンタープライズAIの堀はRAG +ファイン...
- なぜAIが2023年のトップ開発者スキルとな...
- 「Amazon SageMaker Feature Storeを使用...
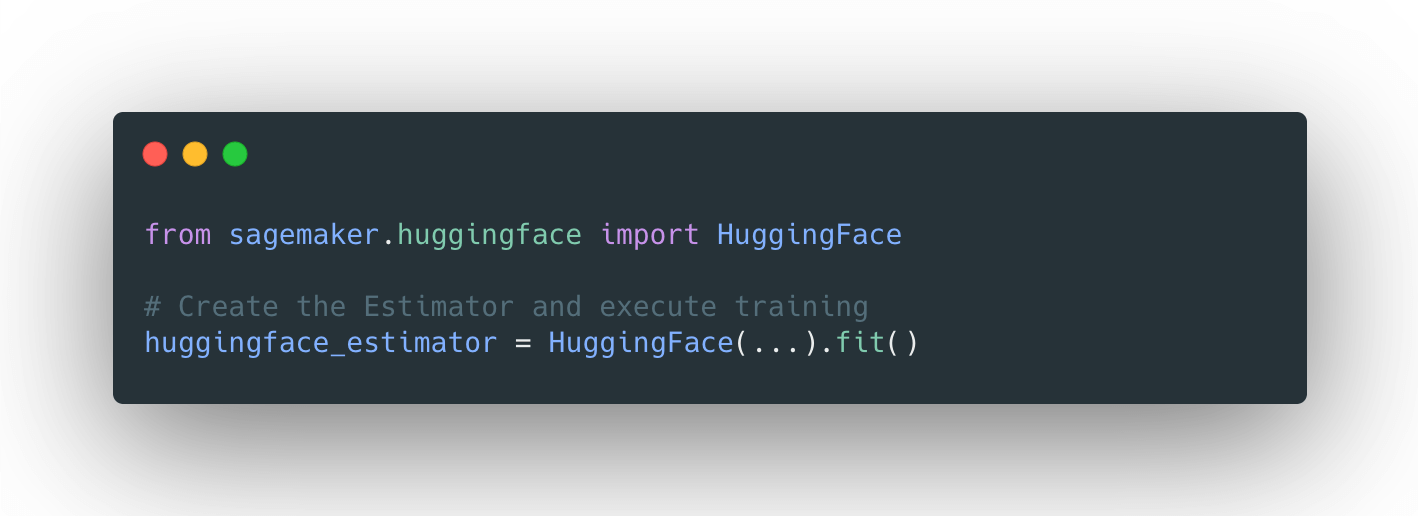
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…

Hugging Face HubでのSentence Transformers
過去数週間、私たちは機械学習エコシステム内の多くのオープンソースフレームワークと協力関係を築いてきました。特に私たちが興奮しているのは、Sentence Transformersです。 Sentence Transformersは、文、段落、画像の埋め込みのためのフレームワークです。これにより、意味のある埋め込みを導出することができます(1)。これは、意味検索や多言語ゼロショット分類などのアプリケーションに役立ちます。Sentence Transformers v2のリリースの一環として、たくさんのクールな新機能があります: ハブでモデルを簡単に共有することができます。 文の埋め込みと文の類似性のためのウィジェットおよび推論API。 より優れた文の埋め込みモデルが利用可能になりました(ベンチマークとハブ内のモデル)。 ハブには、100以上の言語の90以上の事前学習済みSentence Transformersモデルがあり、誰でもそれらを利用し、簡単に使用することができます。事前学習済みモデルは、数行のコードで直接ロードして使用できます: from sentence_transformers import SentenceTransformer sentences = ["Hello World", "Hallo Welt"] model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')…

Hugging FaceとGraphcoreがIPU最適化されたTransformersのために提携
2021年AIハードウェアサミットでの発表により、Hugging Faceはデバイス最適化モデルやソフトウェア統合を含む新しいハードウェアパートナープログラムの開始を発表しました。ここでは、Intelligence Processing Unit(IPU)を開発したGraphcoreがプログラムの創設メンバーであり、Hugging Faceとのパートナーシップにより開発者が最新のTransformerモデルを簡単に高速化できるよう具体的な説明をしています。 GraphcoreとHugging Faceは、機械知能のパワーを利用するイノベーターにとって、手を取り合って作業を容易にするという共通の目標を持つ2つの企業です。 Hugging Faceのハードウェアパートナープログラムにより、Graphcoreシステムを使用して最新のTransformerモデルを展開し、Intelligence Processing Unit(IPU)に最適化されたモデルを最小限のコーディング複雑さで本番規模で使用することができます。 Intelligence Processing Unitとは何ですか? IPUは、GraphcoreのIPU-PODデータセンター計算システムを駆動するプロセッサです。この新しいタイプのプロセッサは、AIや機械学習の非常に特定の計算要件をサポートするように設計されています。細かい粒度の並列処理、低精度演算、スパース性の処理能力などがシリコンに組み込まれています。 GPUのようなSIMD/SIMTアーキテクチャを採用するのではなく、GraphcoreのIPUは大規模な並列処理を行うMIMDアーキテクチャを使用し、プロセッサコアの隣に超高帯域幅メモリをシリコンダイ上に配置しています。 この設計により、BERTやEfficientNetなどの最も人気のあるモデルや次世代のAIアプリケーションを実行する際に、高いパフォーマンスと新しいレベルの効率を実現します。 ソフトウェアは、IPUの機能を引き出す上で重要な役割を果たしています。GraphcoreのPoplar SDKは、Graphcoreの創設以来プロセッサと共同設計されています。現在は、PyTorchやTensorFlowなどの標準の機械学習フレームワーク、およびDockerやKubernetesなどのオーケストレーションや展開ツールと完全に統合されています。 広く使用されているこれらのサードパーティシステムとの互換性を持つようにPoplarを作成することで、開発者は他の計算プラットフォームからモデルを簡単に移植し、IPUの高度なAI機能を利用できるようになります。 本番向けのTransformerの最適化 Transformerは、AIの分野を完全に変革しました。CamemBERT(フランス語)からNLPの知見をコンピュータビジョンに適用するViTまで、Hugging Faceではさまざまなアプリケーションで広く使用されています。これらのマルチタレントモデルは、特徴抽出、テキスト生成、感情分析、翻訳など、さまざまな機能を実行できます。 すでに、Hugging…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…
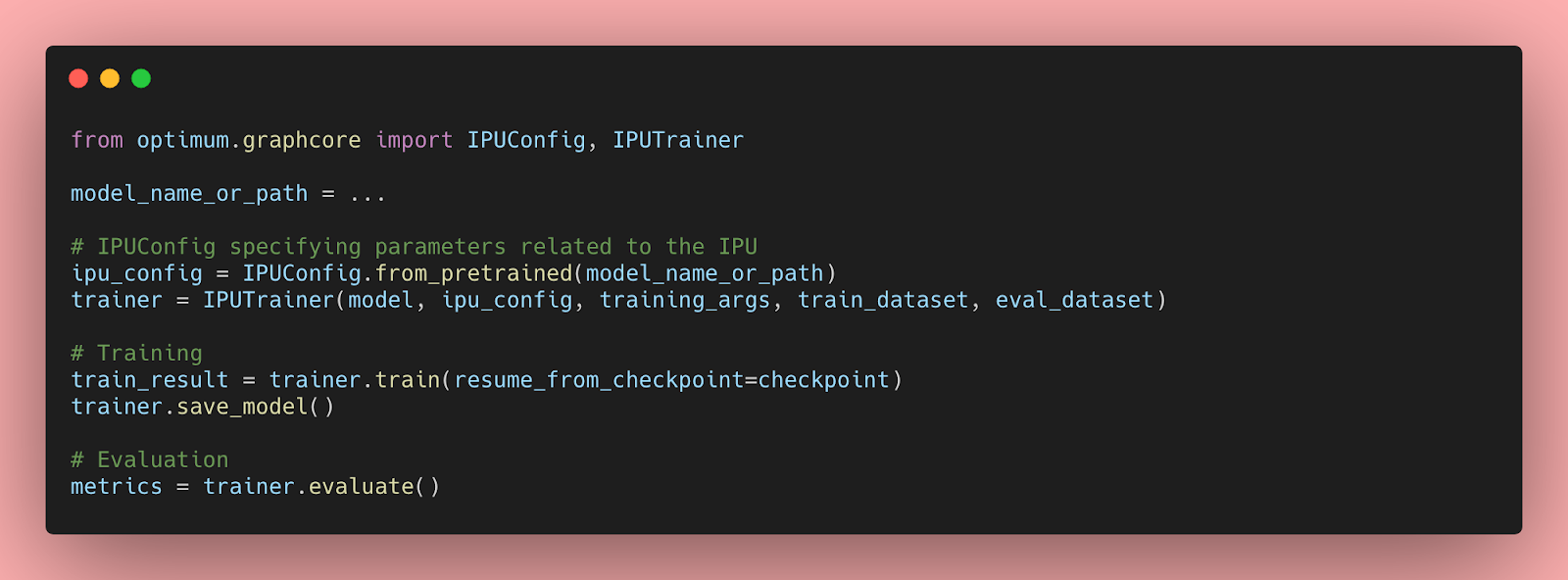
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

Hugging Face Transformers と Amazon SageMaker を使用して、GPT-J 6B を推論のためにデプロイします
約6ヶ月前の今日、EleutherAIはGPT-3のオープンソースの代替となるGPT-J 6Bをリリースしました。GPT-J 6BはEleutherAIs GPT-NEOファミリーの6,000,000,000パラメータの後継モデルであり、テキスト生成のためのGPTアーキテクチャに基づくトランスフォーマーベースの言語モデルです。 EleutherAIの主な目標は、GPT-3と同じサイズのモデルを訓練し、オープンライセンスの下で一般の人々に提供することです。 過去6ヶ月間、GPT-Jは研究者、データサイエンティスト、さらにはソフトウェア開発者から多くの関心を集めてきましたが、実世界のユースケースや製品にGPT-Jを本番環境に展開することは非常に困難でした。 Hugging Face Inference APIやEleutherAIs 6b playgroundなど、製品ワークロードでGPT-Jを使用するためのホステッドソリューションはいくつかありますが、自分自身の環境に簡単に展開する方法の例は少ないです。 このブログ記事では、Amazon SageMakerとHugging Face Inference Toolkitを使用して、数行のコードでGPT-Jを簡単に展開する方法を学びます。これにより、スケーラブルで信頼性の高いセキュアなリアルタイムの推論が可能な通常サイズのNVIDIA T4(約500ドル/月)のGPUインスタンスを使用します。 しかし、それに入る前に、なぜGPT-Jを本番環境に展開するのが困難なのかを説明したいと思います。 背景 6,000,000,000パラメータモデルの重みは、約24GBのメモリを使用します。float32でロードするためには、少なくとも2倍のモデルサイズのCPU RAMが必要です。初期重みのために1倍、チェックポイントのロードのために1倍です。したがって、GPT-Jをロードするには少なくとも48GBのCPU RAMが必要です。 モデルをよりアクセス可能にするために、EleutherAIはfloat16の重みを提供しており、transformersには大規模な言語モデルのロード時のメモリ使用量を削減する新しいオプションがあります。これらすべてを組み合わせると、モデルのロードにはおおよそ12.1GBのCPU…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

🤗 Transformersを使用して、Wav2Vec2を使用して大規模なファイルで自動音声認識を行う方法
Tl;dr: この投稿では、Connectionist Temporal Classification(CTC)アーキテクチャの特性を活用して、任意の長さのファイルやライブ推論中でも非常に良い品質の自動音声認識(ASR)を実現する方法を説明します。 Wav2Vec2は、音声認識のための人気のある事前学習モデルです。Meta AI Researchによって2020年9月にリリースされ、この新しいアーキテクチャは、自己教師あり事前学習における音声認識の進歩を促進しました(例:G. Ng et al.、2021年、Chen et al.、2021年、Hsu et al.、2021年、Babu et al.、2021年)。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは、現在月間25万回以上ダウンロードされています。 Wav2Vec2は、その核としてtransformersモデルを使用しており、transformersの注意点の1つは、通常、扱えるシーケンスの長さに限界があることです。それは位置符号化を使用するためではなく(この場合は違います)、単純にtransformersの注意コストが実際にはO(n²)となり、非常に大きなシーケンス長を使用すると複雑さやメモリの使用量が爆発します。したがって、非常に長いファイルでさえWav2Vec2を実行することはできません(たとえA100のような非常に大きなGPUを使用しても)。プログラムはクラッシュします。試してみましょう! pip install transformers from transformers…
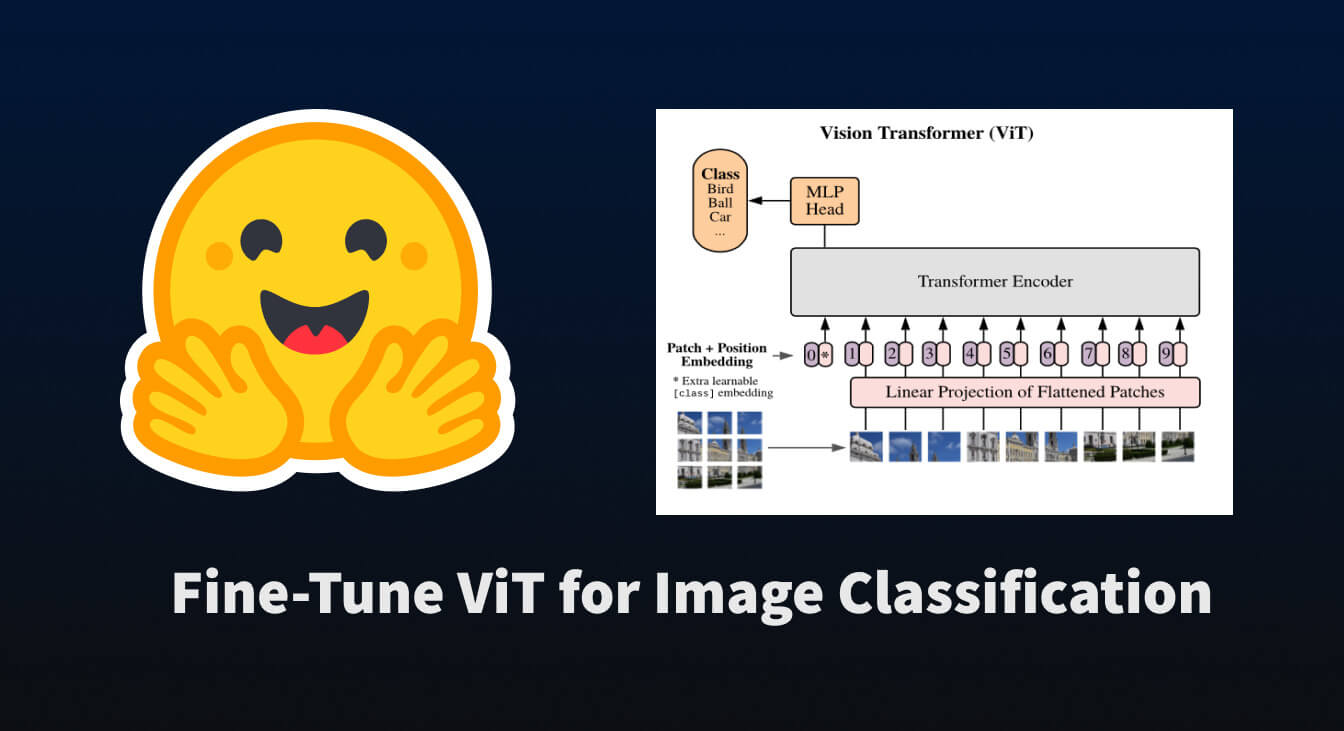
🤗 Transformersを使用して、画像分類のためにViTを微調整する
トランスフォーマーベースのモデルがNLPを革命化したように、我々は今、それらを他のさまざまな領域に適用する論文の爆発を目撃しています。その中でも最も革命的なものの一つが「Vision Transformer(ViT)」です。これは、Google Brainの研究チームによって2021年6月に紹介されました。 この論文では、文をトークン化するように画像をトークン化する方法を探求しており、それによってトランスフォーマーモデルにトレーニング用のデータとして渡すことができます。実際には非常にシンプルな概念です… 画像をサブ画像パッチのグリッドに分割する 各パッチを線形変換で埋め込む 各埋め込まれたパッチがトークンとなり、埋め込まれたパッチのシーケンスがモデルに渡される 上記の手順を実行すると、NLPのタスクと同様にトランスフォーマーを事前学習および微調整することができることがわかります。かなり便利です 😎。 このブログポストでは、🤗 datasets を使用して画像分類データセットをダウンロードおよび処理し、それを使用して事前学習済みの ViT を 🤗 transformers を使用して微調整する方法について説明します。 まずは、それらのパッケージをインストールしましょう。 pip install datasets transformers データセットの読み込み まずは、小規模な画像分類データセットを読み込んで、その構造を確認しましょう。…

🤗 Transformersにおいて制約付きビームサーチを用いたテキスト生成のガイド
イントロダクション このブログ投稿では、トランスフォーマーを使用した言語生成のための異なるデコーディング方法について説明したブログ投稿「テキスト生成方法: トランスフォーマーを使用した異なるデコーディング方法」で説明されているように、読者がビームサーチの異なるバリアントを使用したテキスト生成方法に精通していることを前提としています。 通常のビームサーチとは異なり、制約付きビームサーチではテキスト生成の出力に対して制御を行うことができます。これは、出力内に正確に何を含めたいかを知っている場合に役立ちます。たとえば、ニューラル機械翻訳のタスクでは、辞書検索を使用して最終的な翻訳に含まれる必要がある単語を知っているかもしれません。言語モデルにとってほぼ同じくらい可能性がある生成出力でも、特定の文脈においてエンドユーザーにとっては同じくらい望ましくない場合があります。これらの状況は、ユーザーがモデルに最終出力に含まれる必要のある単語を指示することで解決できます。 なぜ難しいのか しかし、これは非常に非自明な問題です。これは、生成されたテキストの最終出力のどこかで、特定の部分文字列の生成を強制する必要があるからです。 例えば、トークン t 1 , t 2 t_1, t_2 t 1 , t 2 を順番に含む文 S を生成したいとします。予測される文…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.