Learn more about Search Results MNIST - Page 5

- You may be interested
- 新しいAI研究が「SWIM-IR」をリリース!28...
- マイクロソフトの研究者たちは「エモーシ...
- Amazon SageMakerを使用して、オーバーヘ...
- 「データパイプラインについての考え方が...
- このAI研究では、BOFT(Foundationモデル...
- 省エネAI:ニューロモーフィックコンピュ...
- 「生産性を最大化するための5つの最高のAI...
- In Japanese ゼファー7Bベータ:必要な...
- トップ投稿6月19日〜25日:無料でGPT-4に...
- ジョージア工科大学の論文は、より速く潜...
- 「マインドのための宇宙船」:フロリダ大...
- 「Amazon SageMaker ClarifyとMLOpsサービ...
- 「SUSTech VIP研究室が、高性能なインタラ...
- AIを活用した「ディープフェイク」詐欺:...
- 「ChatGPT AI-1の解放:高度なLLMベースの...

PyTorch DDPからAccelerateへ、そしてTrainerへ簡単に分散トレーニングをマスターしましょう
全般的な概要 このチュートリアルでは、PyTorchと単純なモデルのトレーニング方法について基本的な理解があることを前提としています。分散データ並列処理(DDP)というプロセスを通じて複数のGPUでのトレーニングを紹介します。以下の3つの異なる抽象化レベルを通じて行います: pytorch.distributedモジュールを使用したネイティブなPyTorch DDP pytorch.distributedをラップした🤗 Accelerateの軽量なラッパーを利用し、コードの変更なしに単一のGPUおよびTPUで実行できるようにする方法 🤗 Transformerの高レベルのTrainer APIを利用し、ボイラープレートコードを抽象化し、さまざまなデバイスと分散シナリオをサポートする方法 「分散」トレーニングとは何か、なぜ重要なのか? まず、公式のMNISTの例に基づいて、以下の非常に基本的なPyTorchのトレーニングコードを見てみましょう。 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as…
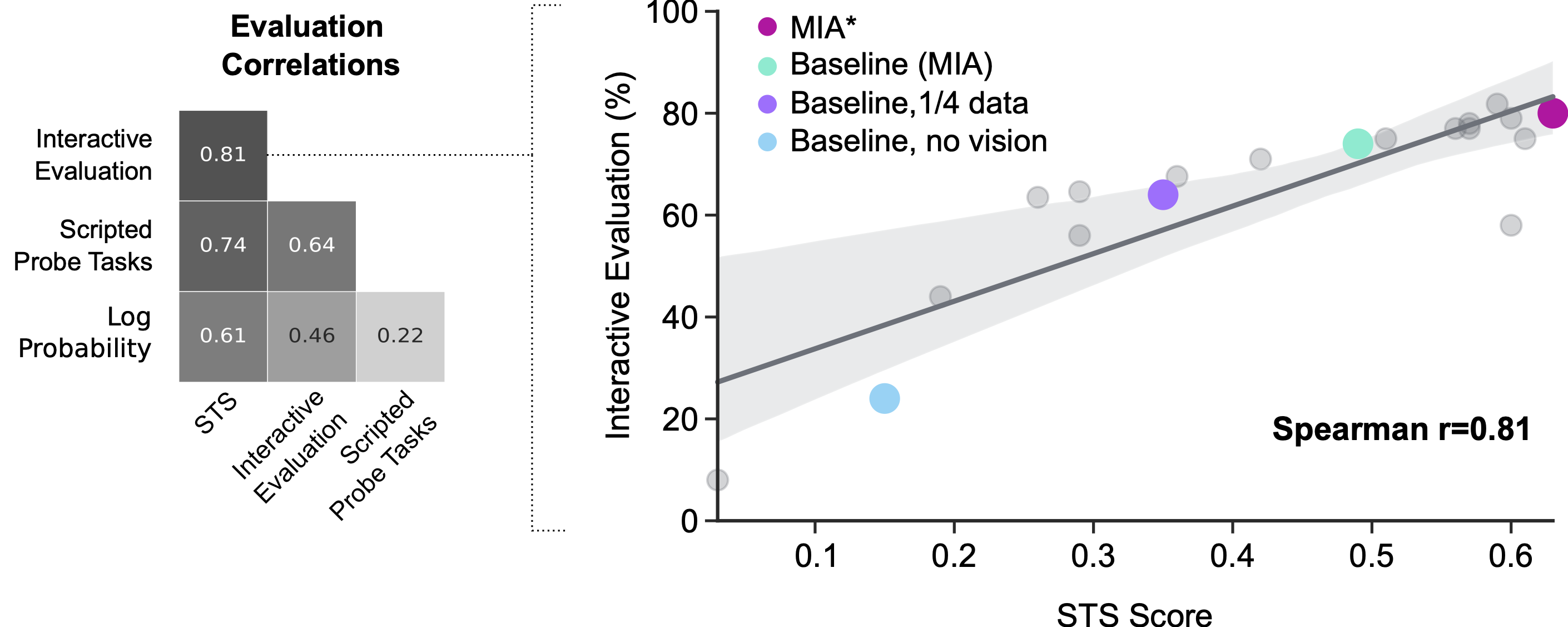
マルチモーダルインタラクティブエージェントの評価
この論文では、これらの既存の評価尺度の利点を評価し、Standardised Test Suite (STS) と呼ばれる評価方法の新しいアプローチを提案しますSTSは、実際の人間の相互作用データから採掘された行動シナリオを使用します

ノイズ除去オートエンコーダの公開
はじめに デノイジングオートエンコーダーは、ノイズの混入したデータまたはノイズのあるデータから元のデータを再構築することを学習することで、ノイズを除去するニューラルネットワークモデルです。モデルを訓練して元のデータと再構築されたデータの差異を最小化します。これらのオートエンコーダーをスタックしてディープネットワークを形成することで、パフォーマンスを向上させることができます。 さらに、画像、音声、テキストなど、さまざまなデータ形式に対応するためにこのアーキテクチャをカスタマイズすることもできます。また、ソルトアンドペッパーやガウシアンノイズなどのノイズを自由にカスタマイズすることもできます。DAEがイメージを再構築するにつれて、入力特徴の学習を効果的に行い、潜在表現の抽出を向上させます。通常のオートエンコーダーと比較して、デノイジングオートエンコーダーは恒等関数の学習の可能性を低減させることを強調することが重要です。 学習目標 デノイジングオートエンコーダー(DAE)の概要と、ノイズの種類から元のデータを再構築することで低次元表現を得るための使用方法についての概要。 エンコーダーとデコーダーなど、DAEアーキテクチャの構成要素についても説明します。 DAEの性能を検証することで、ノイズの混入したデータから元のデータを再構築する役割について洞察を得ることができます。 さらに、デノイジング、圧縮、特徴抽出、表現学習など、DAEのさまざまな応用について考えます。イメージデノイジングを行うためのDAEの実装に焦点を当てた具体的な例として、Kerasデータセットを使用します。 この記事はData Science Blogathonの一環として公開されました。 デノイジングオートエンコーダーとは何ですか? デノイジングオートエンコーダーは、データ表現やエンコーディングの非教示学習を可能にする特定のタイプのニューラルネットワークです。主な目的は、ノイズで破損した入力信号の元のバージョンを再構築することです。この能力は、画像認識や詐欺検出などの問題で、ノイズの混入した形式から元の信号を回復することが目標となります。 オートエンコーダーは、次の2つの主要なコンポーネントで構成されています: エンコーダー:このコンポーネントは、入力データを低次元表現またはエンコーディングにマッピングします。 デコーダー:このコンポーネントは、エンコーディングを元のデータ空間に戻します。 訓練フェーズでは、オートエンコーダーにクリーンな入力例とそれに対応するノイズの混入したバージョンのセットを提供します。目的は、エンコーダー-デコーダーアーキテクチャを使用して、ノイズの入力をクリーンな出力に効率的に変換するタスクを学習することです。 DAEのアーキテクチャ デノイジングオートエンコーダー(DAE)のアーキテクチャは、標準的なオートエンコーダーと似ています。次の2つの主要なコンポーネントで構成されています: エンコーダー エンコーダーは、1つまたは複数の隠れ層を備えたニューラルネットワークを作成します。 その目的は、ノイズの入力データを受け取り、データの低次元表現であるエンコーディングを生成することです。 エンコーダーは、入力データよりも少ないパラメータを持つエンコーディングを持つ圧縮関数として理解します。 デコーダー…
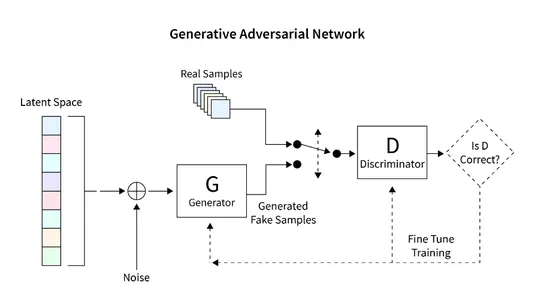
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…
次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
素晴らしいデータサイエンスプロジェクトの鍵は素晴らしいデータセットですが、素晴らしいデータを見つけることは言うほど簡単ではありません私がデータサイエンス修士課程を勉強していた頃を覚えていますが、それはちょうど...

音から視覚へ:音声から画像を合成するAudioTokenについて
ニューラル生成モデルは、私たちがデジタルコンテンツを消費する方法を変え、さまざまな側面を革命化しています。彼らは高品質の画像を生成し、長いテキストスパンでの一貫性を確保し、音声やオーディオを生成する能力を持っています。異なるアプローチの中でも、拡散ベースの生成モデルは注目を集め、さまざまなタスクで有望な結果を示しています。 拡散プロセス中、モデルは定義済みのノイズ分布を目標データ分布にマップする方法を学習します。各ステップで、モデルはノイズを予測し、目標分布から信号を生成します。拡散モデルは、生の入力や潜在表現など、さまざまな形式のデータ表現で動作できます。 Stable Diffusion、DALLE、Midjourneyなどの最先端のモデルは、テキストから画像合成のタスクに対して開発されています。最近ではX-to-Y生成に対する関心が高まっていますが、オーディオから画像へのモデルはまだ深く探究されていません。 テキストプロンプトではなくオーディオ信号を使用する理由は、動画のコンテキストでの画像と音声の相互接続にあります。一方、テキストベースの生成モデルは優れた画像を生成できますが、テキストの説明は画像と本質的に関連していません。つまり、テキストの説明は通常手動で追加されます。また、オーディオ信号には、同じ楽器の異なるバリエーション(例:クラシックギター、アコースティックギター、エレキギターなど)や、同一のオブジェクトの異なる視点(例:スタジオで録音されたクラシックギターとライブショーでのクラシックギター)など、複雑なシーンやオブジェクトを表す能力があります。異なるオブジェクトのこのような詳細な情報の手動注釈は労力がかかり、拡張性が低下するため、スケーラビリティに課題があります。 以前の研究では、主にGANを使用してオーディオ録音に基づいて画像を生成することに焦点を当てた方法が提案されています。ただし、彼らの作業と提案された方法の間には顕著な違いがあります。一部の方法では、MNIST数字の生成にのみ焦点を当て、一般的なオーディオサウンドを包括するアプローチには拡張しませんでした。その他の方法では、一般的なオーディオから画像を生成しましたが、低品質の画像に結果が出たものもありました。 これらの研究の制限を克服するために、オーディオから画像を生成するためのDLモデルが提案されました。その概要は、以下の図に示されています。 このアプローチは、事前にトレーニングされたテキストから画像を生成するモデルと、事前にトレーニングされたオーディオ表現モデルを活用して、それらの出力と入力の間の適応層マッピングを学習することを含みます。最近のテキスト反転の研究から、専用のオーディオトークンが導入され、オーディオ表現が埋め込みベクトルにマップされます。このベクトルは、新しい単語埋め込みを反映する連続表現として、ネットワークに転送されます。 オーディオエンベッダーは、事前トレーニングされたオーディオ分類ネットワークを使用して、オーディオの表現をキャプチャします。通常、識別的ネットワークの最後の層が分類目的に使用されますが、識別的なタスクとは関係のない重要なオーディオの詳細を見落とすことがよくあります。そのため、このアプローチでは、最後の隠れ層と以前の層を組み合わせて、オーディオ信号の時間埋め込みを生成します。 提供されたモデルによって生成されたサンプル結果は、以下に報告されています。 これが、新しいオーディオから画像(A2I)合成モデルであるAudioTokenの概要でした。興味がある場合は、以下のリンクでこの技術についてもっと学ぶことができます。

オープンソースのAmazon SageMaker Distributionで始めましょう
データサイエンティストは、依存関係を管理し、安全である機械学習(ML)およびデータサイエンスのワークロードのための一貫した再現可能な環境が必要ですAWS Deep Learning Containersは、TensorFlow、PyTorch、MXNetなどの一般的なフレームワークでモデルのトレーニングやサービングを行うためのプレビルドされたDockerイメージを既に提供していますこの体験を改善するために、私たちはパブリックベータを発表しました[…]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.