Learn more about Search Results Faiss - Page 5

- You may be interested
- 小売業の革新:AIが顧客体験、在庫管理、...
- 高速なトレーニングと推論 Habana Gaudi®2...
- ウェブ3.0とブロックチェーンの進化による...
- AIにおける事実性の向上 このAI研究は、よ...
- 「OpenAI関数呼び出しの紹介」
- UCバークレーの研究者たちは、ビデオ予測...
- 人工知能を規制するための競争
- 「Amazon SageMaker JumpStartを使用して...
- 「私たちの10の最大のAIの瞬間」
- 「安全で安心なAIに対する取り組みに基づ...
- Deep learning論文の数学をPyTorchで効率...
- あなたのVoAGIポスト-なぜPythonでリスト...
- 「’Acoustic Touch’テクノロ...
- 「13/11から19/11までの週の最も重要なコ...
- スタンフォードの研究者が提案する「EVAPO...

Hugging Faceデータセットとトランスフォーマーを使用した画像の類似性
この投稿では、🤗 Transformersを使用して画像の類似性システムを構築する方法を学びます。クエリ画像と候補画像の類似性を見つけることは、逆画像検索などの情報検索システムの重要なユースケースです。システムが答えようとしているのは、クエリ画像と候補画像セットが与えられた場合、どの画像がクエリ画像に最も類似しているかということです。 このシステムの構築には、このシステムの構築時に便利な並列処理をシームレスにサポートする🤗のdatasetsライブラリを活用します。 この投稿では、ViTベースのモデル( nateraw/vit-base-beans )と特定のデータセット(Beans)を使用していますが、ビジョンモダリティをサポートし、他の画像データセットを使用するために拡張することもできます。試してみることができるいくつかの注目すべきモデルには次のものがあります: Swin Transformer ConvNeXT RegNet また、投稿で紹介されているアプローチは、他のモダリティにも拡張できる可能性があります。 完全に動作する画像の類似性システムを学習するには、最初に2つの画像間の類似性をどのように定義するかを定義する必要があります。 このシステムを構築するためには、まず与えられた画像の密な表現(埋め込み)を計算し、その後、余弦類似性指標を使用して2つの画像の類似性を決定する一般的な方法があります。 この投稿では、画像をベクトル空間で表現するために「埋め込み」を使用します。これにより、画像の高次元ピクセル空間(たとえば224 x 224 x 3)を意味のある低次元空間(たとえば768)にうまく圧縮する方法が得られます。これによる主な利点は、後続のステップでの計算時間の削減です。 画像から埋め込みを計算するために、入力画像をベクトル空間で表現する方法について理解しているビジョンモデルを使用します。このタイプのモデルは画像エンコーダとも呼ばれます。 モデルをロードするために、AutoModelクラスを活用します。これにより、Hugging Face Hubから互換性のあるモデルチェックポイントをロードするためのインターフェースが提供されます。モデルと共に、データ前処理に関連するプロセッサもロードします。 from transformers…
ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
ChromaDB、Langchain、およびChatGPTを活用した大規模ドキュメントデータベースからの強化された応答と引用されたソース

今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
人工知能には無限の可能性があります。それは、新しいリリースや開発によって明らかになっています。OpenAIが開発した最新のチャットボットであるChatGPTのリリースにより、AIの領域はGPTのトランスフォーマーアーキテクチャのおかげで常に注目を浴びています。ディープラーニング、自然言語処理(NLP)、自然言語理解(NLU)からコンピュータビジョンまで、AIは無限のイノベーションをもたらす未来へと皆を推進しています。ほぼすべての産業がAIの潜在能力を活用し、自己革新を遂げています。特に大規模言語モデル(LLMs)、LangChain、およびベクトルデータベースの領域での優れた技術的進歩がこの素晴らしい発展の原動力です。 大規模言語モデル 大規模言語モデル(LLMs)の開発は、人工知能における大きな進歩を表しています。これらのディープラーニングベースのモデルは、自然言語を処理し理解する際に印象的な正確さと流暢さを示します。LLMsは、書籍、ジャーナル、Webページなど、さまざまなソースからの大量のテキストデータを使用してトレーニングされます。言語を学ぶ過程で、LLMsは言語の構造、パターン、および意味的な関連性を理解するのに役立ちます。 LLMsの基本的なアーキテクチャは通常、複数の層からなるディープニューラルネットワークです。このネットワークは、トレーニングデータで発見されたパターンと接続に基づいて、入力テキストを分析し予測を行います。トレーニングフェーズ中にモデルの期待される出力と意図された出力の不一致を減少させるために、モデルのパラメータは調整されます。LLMは、トレーニング中にテキストデータを消費し、文脈に応じて次の単語または単語のシリーズを予測しようとします。 LLMsの使用方法 質問への回答:LLMsは質問に回答するのが得意であり、正確で簡潔な回答を提供するために、本や論文、ウェブサイトなどの大量のテキストを検索します。 コンテンツ生成 – LLMsは、コンテンツ生成に活用されることが証明されています。彼らは、文法的に正しい一貫した記事、ブログエントリ、および他の文章を生成する能力を持っています。 テキスト要約:LLMsはテキスト要約に優れており、長いテキストを短く、より理解しやすい要約にまとめることができます。 チャットボット – LLMsは、チャットボットや対話型AIを使用したシステムの開発に頻繁に使用されます。これらのシステムは、質問を理解し適切に応答し、対話全体で文脈を保持することで、ユーザーと自然な言語で対話することができます。 言語翻訳 – LLMsは、言語の壁を乗り越えて成功したコミュニケーションを可能にするため、テキストの正確な翻訳が可能です。 LLMのトレーニングの手順 LLMのトレーニングの最初の段階は、モデルが言語のパターンや構造を発見するために使用する大規模なテキストデータセットを編集することです。 データセットが収集されたら、トレーニングのためにそれを準備するために前処理が必要です。これには、不要なエントリを削除することによるデータのクリーニングが含まれます。 LLMをトレーニングするために適切なモデルアーキテクチャを選択することは重要です。トランスフォーマベースのアーキテクチャは、GPTモデルを含む自然言語の処理と生成に非常に効率的であることが示されています。 モデルのパラメータを調整してLLMをトレーニングし、バックプロパゲーションなどのディープラーニング手法を使用してその精度を向上させます。モデルはトレーニング中に入力データを処理し、認識されたパターンに基づいて予測を行います。 初期のトレーニング後、LLMは特定のタスクやドメインでさらに微調整され、それらの領域でのパフォーマンスが向上します。 トレーニングされたLLMのパフォーマンスを評価し、モデルのパフォーマンスを評価するためのパープレキシティや精度などの複数のメトリクスを使用して、その効果を決定することが重要です。 トレーニングと評価が完了したLLMは、実際のアプリケーションのためのプロダクション環境で使用されます。…

Langchainを使用してYouTube動画用のChatGPTを構築する
はじめに ビデオとチャットで話すことができたらどのくらい便利だろうかと考えたことがありますか?私自身、ブログを書く人間として、関連する情報を見つけるために1時間ものビデオを見ることはしばしば退屈に感じます。ビデオから有用な情報を得るために、ビデオを見ることが仕事のように感じることもあります。そこで、YouTubeビデオやその他のビデオとチャットできるチャットボットを作成しました。これは、GPT-3.5-turbo、Langchain、ChromaDB、Whisper、およびGradioによって実現されました。この記事では、Langchainを使用してYouTubeビデオのための機能的なチャットボットを構築するコードの解説を行います。 学習目標 Gradioを使用してWebインターフェースを構築する Whisperを使用してYouTubeビデオを処理し、テキストデータを抽出する テキストデータを適切に処理およびフォーマットする テキストデータの埋め込みを作成する Chroma DBを構成してデータを保存する OpenAI chatGPT、ChromaDB、および埋め込み機能を使用してLangchainの会話チェーンを初期化する 最後に、Gradioチャットボットに対するクエリとストリーミング回答を行う コーディングの部分に入る前に、使用するツールや技術に慣れておきましょう。 この記事は、Data Science Blogathonの一部として公開されました。 Langchain Langchainは、Pythonで書かれたオープンソースのツールで、Large Language Modelsデータに対応したエージェントを作成できます。では、それはどういうことでしょうか?GPT-3.5やGPT-4など、商用で利用可能な大規模言語モデルのほとんどは、トレーニングされたデータに制限があります。たとえば、ChatGPTは、すでに見た質問にしか答えることができません。2021年9月以降のものは不明です。これがLangchainが解決する核心的な問題です。Wordドキュメントや個人用PDFなど、どのデータでもLLMに送信して人間らしい回答を得ることができます。ベクトルDB、チャットモデル、および埋め込み関数などのツールにはラッパーがあり、Langchainだけを使用してAIアプリケーションを簡単に構築できます。 Langchainを使用すると、エージェント(LLMボット)を構築することもできます。これらの自律エージェントは、データ分析、SQLクエリ、基本的なコードの記述など、複数のタスクに設定できます。これらのエージェントを使用することで、低レベルな知識作業をLLMに外注することができるため、時間とエネルギーを節約できます。 このプロジェクトでは、Langchainツールを使用して、ビデオ用のチャットアプリを構築します。Langchainに関する詳細については、公式サイトを訪問してください。 Whisper Whisperは、OpenAIの別の製品です。これは、オーディオまたはビデオをテキストに変換できる汎用音声認識モデルです。多言語翻訳、音声認識、および分類を実行するために、多様なオーディオをトレーニングしています。…
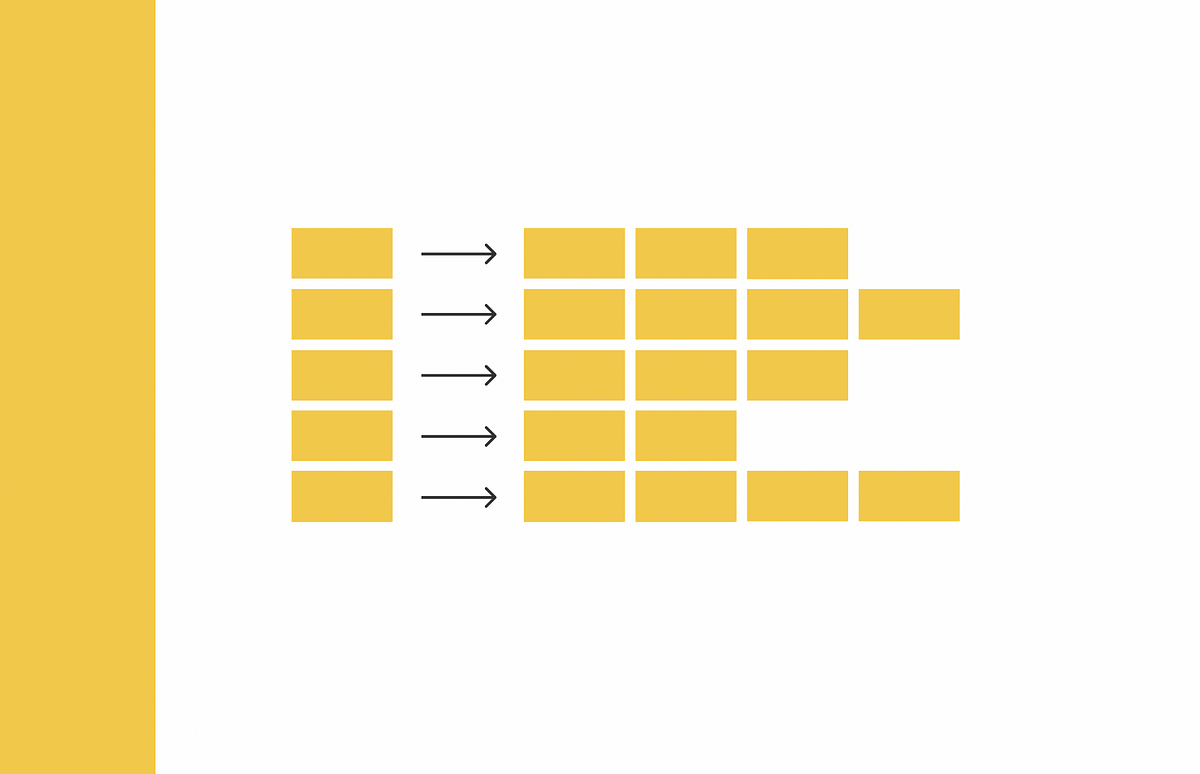
類似検索、パート5:局所性鋭敏ハッシュ(LSH)
類似度検索とは、クエリが与えられたときに、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目的とした問題ですデータサイエンスにおいては、類似度検索はしばしば自然言語処理において現れます...
言語学習モデルにおけるOpenAIの関数呼び出しの力:包括的なガイド
OpenAIの関数呼び出し機能を使用したデータパイプラインの変換:PostgreSQLとFastAPIを使用した電子メール送信ワークフローの実装

GPT4Allは、あなたのドキュメント用のローカルChatGPTであり、無料です!
あなたのラップトップにGPT4Allをインストールし、AIにあなた自身のドメイン知識(あなたのドキュメント)について尋ねる方法... そして、それはCPUのみで動作します!

無料のフルスタックLLMブートキャンプ
LLMについて詳しく学び、クールなLLMパワードアプリケーションを作成したいですか?この無料のフルスタックLLMブートキャンプが必要なすべてです!

Amazon SageMakerを使用してOpenChatkitモデルを利用したカスタムチャットボットアプリケーションを構築する
オープンソースの大規模言語モデル(LLM)は、研究者、開発者、そして組織がこれらのモデルにアクセスしてイノベーションや実験を促進できるようになり、人気が高まっていますこれにより、オープンソースコミュニティからの協力が促進され、LLMの開発や改良に貢献することができますオープンソースのLLMは、モデルアーキテクチャ、トレーニングプロセス、トレーニングデータに透明性を提供し、研究者がモデルを理解することができます[…]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.