Learn more about Search Results DataLoader - Page 5

- You may be interested
- DeepSpeedとAccelerateを使用した非常に高...
- このAI論文は、オープンソースライブラリ...
- ChatGPTは自己を規制するための法律を作成...
- AIとアクセシビリティを活用して、融合エ...
- PyTorchを使用してx86 CPU上で推論速度を...
- 「トランスフォーマーの簡素化:理解でき...
- 効率的なプロンプトエンジニアになるため...
- 「イェール大学とGoogleの研究者が、効率...
- Appleの研究者がマトリョーシカ拡散モデル...
- Nvidiaは、エンジニア向けに生成AIを試験...
- ディープラーニング実験の十のパターンと...
- 「データは言語モデルの基盤です」
- 人間の注意力を予測するモデルを通じて、...
- なぜBankrateはAI生成記事を諦めたのか
- Python RegExのマスタリング:パターンマ...

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…
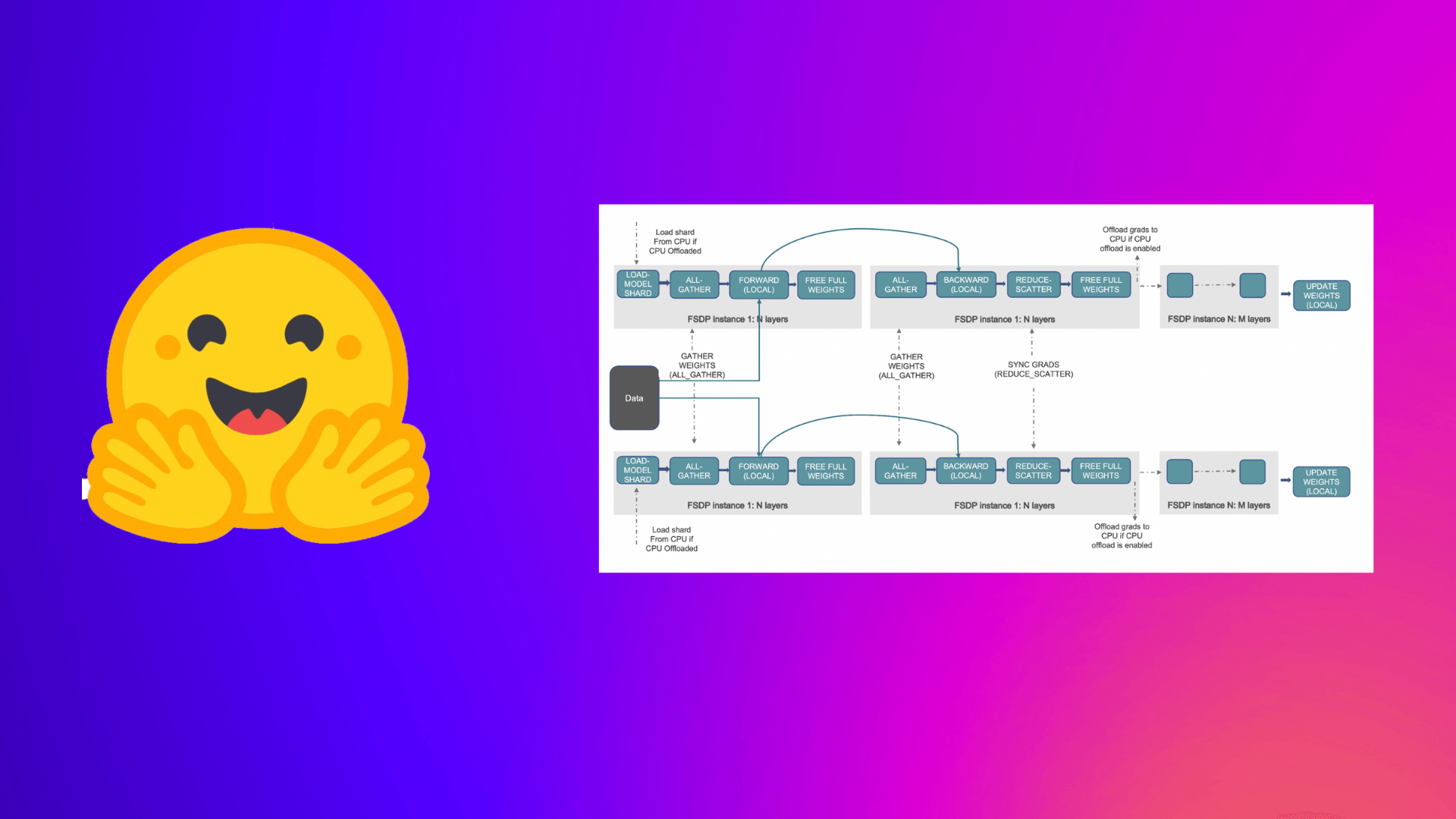
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

Hugging Faceハブへ、fastaiさんを歓迎します
ニューラルネットを再びクールじゃなくする…そして共有する Deep Learningのアクセシビリティを高めるために、fast.aiエコシステムは他に類を見ない成果を上げてきました。Hugging Faceの使命は、優れた機械学習を民主化することです。機械学習へのアクセスの排他性、事前学習済みモデルを過去のものとし、この素晴らしい領域をさらに推進しましょう。 fastaiは、PyTorchとPythonを活用して、テキスト、画像、表形式のデータに対して最新の出力を備えた高速かつ正確なニューラルネットワークをトレーニングするためのハイレベルなコンポーネントを提供するオープンソースのDeep Learningライブラリです。ただし、fast.aiは単なるライブラリ以上のものです。それはオープンソースの貢献者とニューラルネットワークの学習に取り組む人々の繁栄するエコシステムに成長しました。いくつかの例として、彼らの書籍やコースをチェックしてみてください。fast.aiのDiscordやフォーラムに参加してください。彼らのコミュニティに参加することで、確実に学びが得られます! これら全ての理由から(この記事の執筆者はfast.aiのコースのおかげで自分の旅をスタートさせました)、私たちは誇りを持ってお知らせします。fastaiのプラクティショナーは、Pythonの一行でモデルをHugging Face Hubに共有・アップロードすることができるようになりました。 👉 この記事では、fastaiとHubの統合について紹介します。さらに、このチュートリアルをColabノートブックとして開くこともできます。 fast.aiコミュニティ、特にJeremy Howard、Wayde Gilliam、Zach Muellerにフィードバックをいただいたことに感謝します 🤗。このブログは、fastaiドキュメントのHugging Face Hubセクションに強く触発されています。 Hubに共有する理由 Hubは、モデル、データセット、MLデモを共有・探索できる中央プラットフォームです。最も広範なオープンソースのモデル、データセット、デモのコレクションを提供しています。 Hubで共有することで、あなたのfastaiモデルの影響力を広げ、他の人がダウンロードして探索できるようにします。また、fastaiモデルを転移学習に利用することもできます。他の誰かのモデルをタスクの基礎として読み込むことができます。 誰でも、hf.co/modelsのウェブページでfastaiライブラリをフィルタリングすることで、Hubの全てのfastaiモデルにアクセスできます。以下の画像を参照してください。 広範なコミュニティへの無料モデルホスティングと露出に加えて、Hubにはgitに基づいたバージョン管理(大容量ファイルの場合はgit-lfs)や、発見性と再現性のためのモデルカードも組み込まれています。Hubのナビゲーションについての詳細は、この紹介を参照してください。 Hugging…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

Sentence Transformersモデルのトレーニングと微調整
このNotebook Companion付きのチュートリアルをご覧ください: センテンス変換モデルのトレーニングまたはファインチューニングは、利用可能なデータと目標のタスクに大きく依存します。キーは2つあります: モデルにデータを入力し、データセットを適切に準備する方法を理解する。 データセットと関連する異なる損失関数を理解する。 このチュートリアルでは、以下の内容を学びます: “スクラッチ”から作成するか、Hugging Face Hubからファインチューニングすることにより、センテンス変換モデルの動作原理を理解する。 データセットの異なる形式について学ぶ。 データセットの形式に基づいて選択できる異なる損失関数について確認する。 モデルのトレーニングまたはファインチューニング。 Hugging Face Hubにモデルを共有する。 センテンス変換モデルが最適な選択肢でない場合について学ぶ。 センテンス変換モデルの動作原理 センテンス変換モデルでは、可変長のテキスト(または画像ピクセル)を、その入力の意味を表す固定サイズの埋め込みにマップします。埋め込みの取得方法については、前回のチュートリアルをご覧ください。この投稿では、テキストに焦点を当てています。 センテンス変換モデルの動作原理は次の通りです: レイヤー1 – 入力テキストは、Hugging Face Hubから直接取得できる事前学習済みTransformerモデルを通過します。このチュートリアルでは、「distilroberta-base」モデルを使用します。Transformerの出力は、すべての入力トークンに対する文脈化された単語の埋め込みです。テキストの各トークンに対する埋め込みを想像してください。…

Megatron-LMを使用して言語モデルをトレーニングする方法
PyTorchで大規模な言語モデルをトレーニングするには、単純なトレーニングループだけでは不十分です。通常、複数のデバイスに分散しており、安定した効率的なトレーニングのための多くの最適化技術があります。Hugging Face 🤗 Accelerateライブラリは、トレーニングループに非常に簡単に統合できるように、GPUとTPUを跨いで分散トレーニングをサポートするために作成されました。🤗 TransformersもTrainer APIを介して分散トレーニングをサポートしており、トレーニングループの実装を必要とせずにPyTorchでの完全なトレーニングを提供します。 大規模なトランスフォーマーモデルを事前トレーニングするための研究者の間でのもう一つの人気ツールはMegatron-LMです。これはNVIDIAのApplied Deep Learning Researchチームによって開発された強力なフレームワークです。🤗 AccelerateとTrainerとは異なり、Megatron-LMの使用は直感的ではなく、初心者には少し抵抗があるかもしれません。しかし、これはGPU上でのトレーニングに最適化されており、いくつかの高速化を提供することができます。このブログ記事では、Megatron-LMを使用してNVIDIAのGPU上で言語モデルをトレーニングし、それをtransformersと一緒に使用する方法を学びます。 このフレームワークでGPT2モデルをトレーニングするためのさまざまなステップを紹介します。これには以下が含まれます。 環境のセットアップ データの前処理 トレーニング モデルの🤗 Transformersへの変換 なぜMegatron-LMを選ぶのか? トレーニングの詳細に入る前に、他のフレームワークよりもこのフレームワークが効率的である理由を理解しましょう。このセクションは、Megatron-DeepSpeedでのBLOOMトレーニングについての素晴らしいブログから着想を得ています。詳細については参照してください。このブログ記事はMegatron-LMへの優しい入門を提供することを目的としています。 データローダー Megatron-LMには、データがトークン化され、トレーニング前にシャッフルされる効率的なデータローダーが付属しています。また、データは番号付きのシーケンスに分割され、それらは計算が必要な場合にのみ計算されるようにインデックスで保存されます。インデックスを作成するために、エポック数はトレーニングパラメータに基づいて計算され、順序が作成され、その後シャッフルされます。これは通常の場合とは異なり、データセット全体を繰り返し処理してから2番目のエポックのために繰り返すというものです。これにより、学習曲線が滑らかになり、トレーニング中の時間が節約されます。 組み込みCUDAカーネル GPU上で計算を実行する場合、必要なデータはメモリから取得され、計算が実行され、結果がメモリに保存されます。簡単に言えば、組み込みカーネルのアイデアは、通常はPyTorchによって別々に実行される類似の操作を、単一のハードウェア操作に統合することです。そのため、複数の個別の計算で行われるメモリ移動の回数を減らします。以下の図は、カーネルフュージョンのアイデアを示しています。これは、詳細について説明しているこの論文からインスピレーションを受けています。 f、g、hが1つのカーネルで結合された場合、fとgの中間結果x’とy’はGPUレジスタに保存され、hによって即座に使用されます。しかし、フュージョンがない場合、x’とy’はメモリにコピーされ、hによって読み込まれる必要があります。したがって、カーネルフュージョンは計算に著しいスピードアップをもたらします。Megatron-LMはまた、PyTorchの実装よりも高速なApexのFused…

PyTorch DDPからAccelerateへ、そしてTrainerへ簡単に分散トレーニングをマスターしましょう
全般的な概要 このチュートリアルでは、PyTorchと単純なモデルのトレーニング方法について基本的な理解があることを前提としています。分散データ並列処理(DDP)というプロセスを通じて複数のGPUでのトレーニングを紹介します。以下の3つの異なる抽象化レベルを通じて行います: pytorch.distributedモジュールを使用したネイティブなPyTorch DDP pytorch.distributedをラップした🤗 Accelerateの軽量なラッパーを利用し、コードの変更なしに単一のGPUおよびTPUで実行できるようにする方法 🤗 Transformerの高レベルのTrainer APIを利用し、ボイラープレートコードを抽象化し、さまざまなデバイスと分散シナリオをサポートする方法 「分散」トレーニングとは何か、なぜ重要なのか? まず、公式のMNISTの例に基づいて、以下の非常に基本的なPyTorchのトレーニングコードを見てみましょう。 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

効率的で安定した拡散微調整のためのLoRAの使用
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。 DiffusersのためのLoRA 🧨 LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。 私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。 クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。 私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します: 既に議論されているように、トレーニングがはるかに高速です。 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました! トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。 私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。 LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。 (@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.