Learn more about Search Results Chroma DB - Page 5

- You may be interested
- 「NVIDIA OmniverseでDLSS 3.5およびレイ...
- 初心者向けの転移学習
- アリゾナ州立大学のこのAI研究は、テキス...
- OpenAIはGPT-4 Turboを発表:カスタマイズ...
- SalesForce AIはCodeChainを導入:代表的...
- 「PythonでCuPyを使ってGPUのパワーを最大...
- AIとオープンソースソフトウェア:誕生時...
- 「KPMG、AIに20億ドル以上の賭けをし、120...
- エントロピー正則化強化学習の説明
- 「Synthesysレビュー:最高のAIビデオジェ...
- Pythonコード生成のためのLlama-2 7Bモデ...
- 「ソフトウェア開発者のための機械学習フ...
- 「AI Time JournalがeBook「2023年の顧客...
- 混合現実で測定された没入型エンゲージメ...
- プロジェクトゲームフェイスをご紹介しま...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...
自分のハードウェアでのコード理解
現在の大規模言語モデル(LLM)が実行できるさまざまなタスクの中で、ソースコードの理解は、ソフトウェア開発者やデータエンジニアとしてソースコードで作業している場合に特に興味深いものかもしれません
ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
ChromaDB、Langchain、およびChatGPTを活用した大規模ドキュメントデータベースからの強化された応答と引用されたソース

今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
人工知能には無限の可能性があります。それは、新しいリリースや開発によって明らかになっています。OpenAIが開発した最新のチャットボットであるChatGPTのリリースにより、AIの領域はGPTのトランスフォーマーアーキテクチャのおかげで常に注目を浴びています。ディープラーニング、自然言語処理(NLP)、自然言語理解(NLU)からコンピュータビジョンまで、AIは無限のイノベーションをもたらす未来へと皆を推進しています。ほぼすべての産業がAIの潜在能力を活用し、自己革新を遂げています。特に大規模言語モデル(LLMs)、LangChain、およびベクトルデータベースの領域での優れた技術的進歩がこの素晴らしい発展の原動力です。 大規模言語モデル 大規模言語モデル(LLMs)の開発は、人工知能における大きな進歩を表しています。これらのディープラーニングベースのモデルは、自然言語を処理し理解する際に印象的な正確さと流暢さを示します。LLMsは、書籍、ジャーナル、Webページなど、さまざまなソースからの大量のテキストデータを使用してトレーニングされます。言語を学ぶ過程で、LLMsは言語の構造、パターン、および意味的な関連性を理解するのに役立ちます。 LLMsの基本的なアーキテクチャは通常、複数の層からなるディープニューラルネットワークです。このネットワークは、トレーニングデータで発見されたパターンと接続に基づいて、入力テキストを分析し予測を行います。トレーニングフェーズ中にモデルの期待される出力と意図された出力の不一致を減少させるために、モデルのパラメータは調整されます。LLMは、トレーニング中にテキストデータを消費し、文脈に応じて次の単語または単語のシリーズを予測しようとします。 LLMsの使用方法 質問への回答:LLMsは質問に回答するのが得意であり、正確で簡潔な回答を提供するために、本や論文、ウェブサイトなどの大量のテキストを検索します。 コンテンツ生成 – LLMsは、コンテンツ生成に活用されることが証明されています。彼らは、文法的に正しい一貫した記事、ブログエントリ、および他の文章を生成する能力を持っています。 テキスト要約:LLMsはテキスト要約に優れており、長いテキストを短く、より理解しやすい要約にまとめることができます。 チャットボット – LLMsは、チャットボットや対話型AIを使用したシステムの開発に頻繁に使用されます。これらのシステムは、質問を理解し適切に応答し、対話全体で文脈を保持することで、ユーザーと自然な言語で対話することができます。 言語翻訳 – LLMsは、言語の壁を乗り越えて成功したコミュニケーションを可能にするため、テキストの正確な翻訳が可能です。 LLMのトレーニングの手順 LLMのトレーニングの最初の段階は、モデルが言語のパターンや構造を発見するために使用する大規模なテキストデータセットを編集することです。 データセットが収集されたら、トレーニングのためにそれを準備するために前処理が必要です。これには、不要なエントリを削除することによるデータのクリーニングが含まれます。 LLMをトレーニングするために適切なモデルアーキテクチャを選択することは重要です。トランスフォーマベースのアーキテクチャは、GPTモデルを含む自然言語の処理と生成に非常に効率的であることが示されています。 モデルのパラメータを調整してLLMをトレーニングし、バックプロパゲーションなどのディープラーニング手法を使用してその精度を向上させます。モデルはトレーニング中に入力データを処理し、認識されたパターンに基づいて予測を行います。 初期のトレーニング後、LLMは特定のタスクやドメインでさらに微調整され、それらの領域でのパフォーマンスが向上します。 トレーニングされたLLMのパフォーマンスを評価し、モデルのパフォーマンスを評価するためのパープレキシティや精度などの複数のメトリクスを使用して、その効果を決定することが重要です。 トレーニングと評価が完了したLLMは、実際のアプリケーションのためのプロダクション環境で使用されます。…
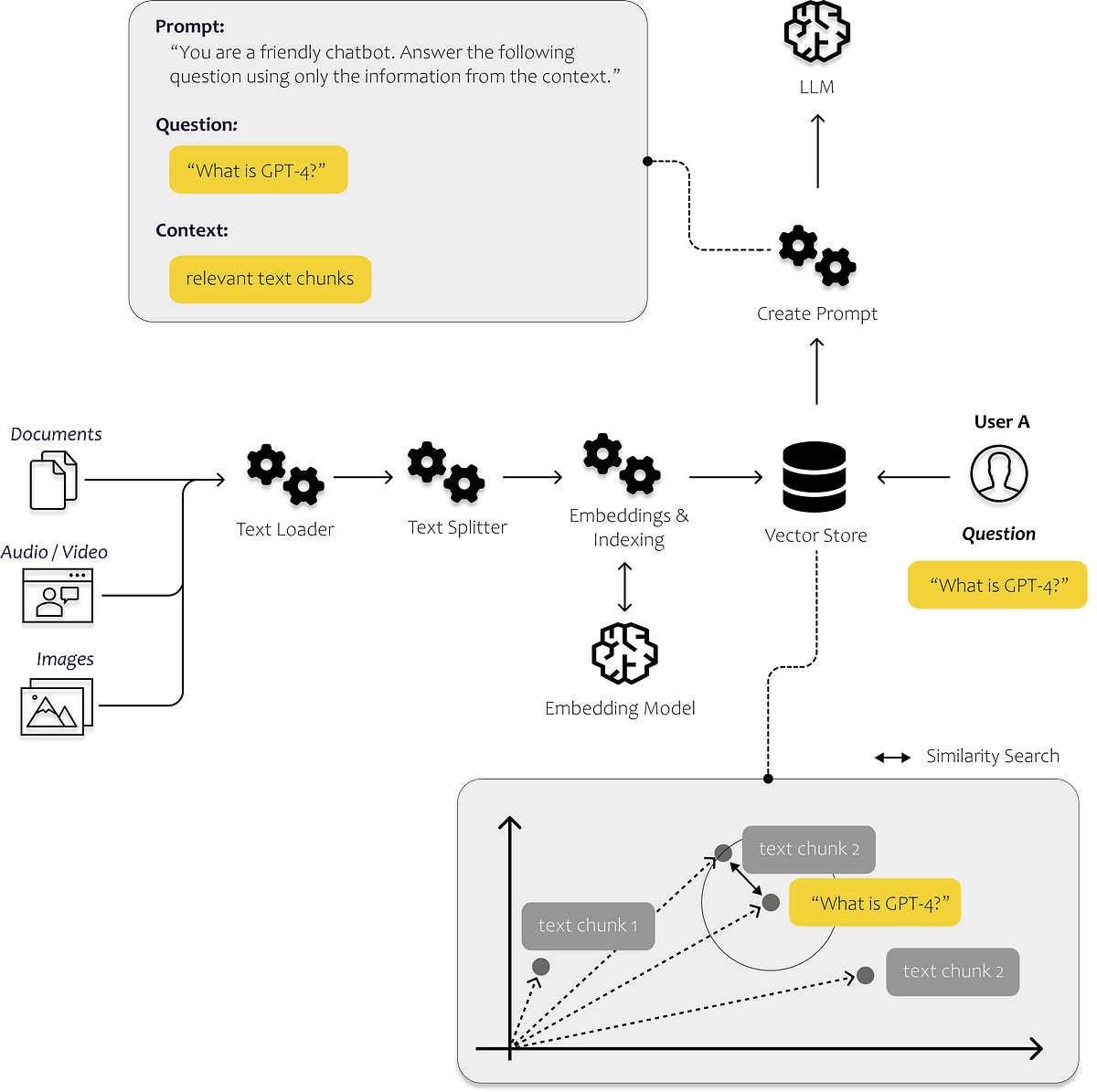
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.