Learn more about Search Results Buffer - Page 5

- You may be interested
- IIoTとAI:工業の風景を変革するシナジス...
- GPT-3がMLOpsの将来に与える意味とは?デ...
- 「公正なAIアルゴリズムを活用した先進テ...
- 「VoAGIニュース、11月8日:Python、SQL、...
- 「5つのステップでPyTorchを始めましょう」
- 「AIを活用して国連の持続可能な開発目標...
- ロンドン大学の研究者がDSP-SLAMを紹介:...
- CMU、AI2、およびワシントン大学の研究グ...
- 「TikTokショップドロップシッピングでお...
- ドキュメント指向エージェント:ベクトル...
- 「OSMネットワークでの移動時間によって重...
- 「探索的データ解析中の繰り返しタスクの...
- 「企業におけるAIの倫理とESGへの貢献の探...
- 「AI言語モデルにおける迅速なエンジニア...
- 「機械学習を使用するかどうか」

LangChain 101 パート1. シンプルなQ&Aアプリの構築
LangChainは、テキストを生成し、質問に答え、言語を翻訳し、その他多くのテキスト関連の作業を行うアプリケーションを作成するための強力なフレームワークです私はLangChainと一緒に働いてから...
学習トランスフォーマーコード第2部 – GPTを間近で観察
私のプロジェクトの第2部へようこそここでは、TinyStoriesデータセットとnanoGPTを使用して、トランスフォーマーとGPTベースのモデルの複雑さについて探求しますこれらはすべて、古いゲーミングラップトップで訓練されました

Google Cloud上のサーバーレストランスフォーマーパイプラインへの私の旅
コミュニティメンバーのマクサンス・ドミニシによるゲストブログ投稿 この記事では、Google Cloudにtransformers感情分析パイプラインを展開するまでの道のりについて説明します。まず、transformersの簡単な紹介から始め、実装の技術的な部分に移ります。最後に、この実装をまとめ、私たちが達成したことについてレビューします。 目標 Discordに残された顧客のレビューがポジティブかネガティブかを自動的に検出するマイクロサービスを作成したかったです。これにより、コメントを適切に処理し、顧客の体験を向上させることができます。たとえば、レビューがネガティブな場合、顧客に連絡し、サービスの品質の低さを謝罪し、サポートチームができるだけ早く連絡し、問題を修正するためにサポートすることができる機能を作成できます。1か月あたり2,000件以上のリクエストは予定していないため、時間と拡張性に関してはパフォーマンスの制約を課しませんでした。 Transformersライブラリ 最初に.h5ファイルをダウンロードしたとき、少し混乱しました。このファイルはtensorflow.keras.models.load_modelと互換性があると思っていましたが、実際にはそうではありませんでした。数分の調査の後、ファイルがケラスモデルではなく重みのチェックポイントであることがわかりました。その後、Hugging Faceが提供するAPIを試して、彼らが提供するパイプライン機能についてもう少し調べました。APIおよびパイプラインの結果が素晴らしかったため、自分自身のサーバーでモデルをパイプラインを通じて提供することができると判断しました。 以下は、TransformersのGitHubページの公式の例です。 from transformers import pipeline # 感情分析のためのパイプラインを割り当てる classifier = pipeline('sentiment-analysis') classifier('We are very happy to include…
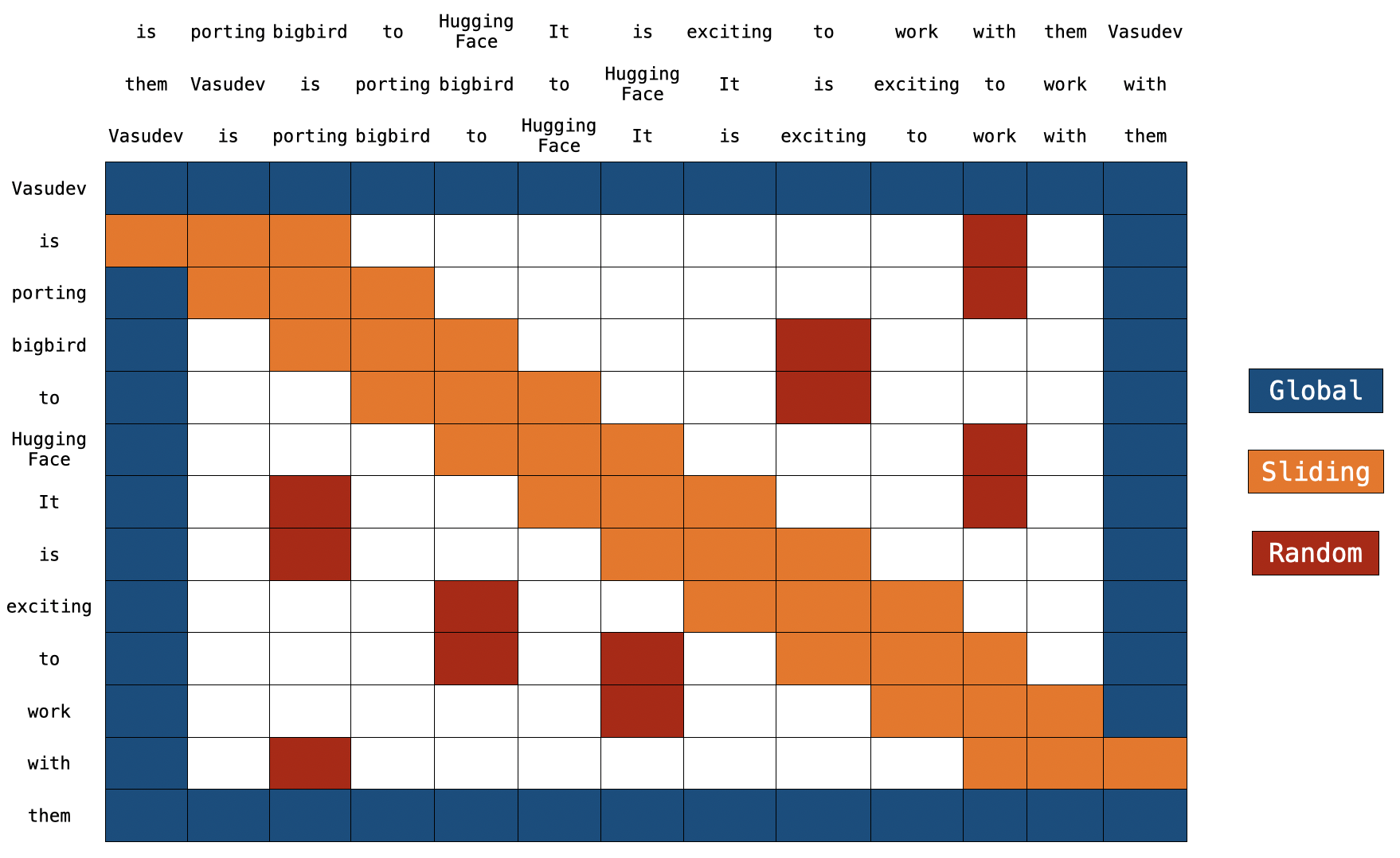
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…
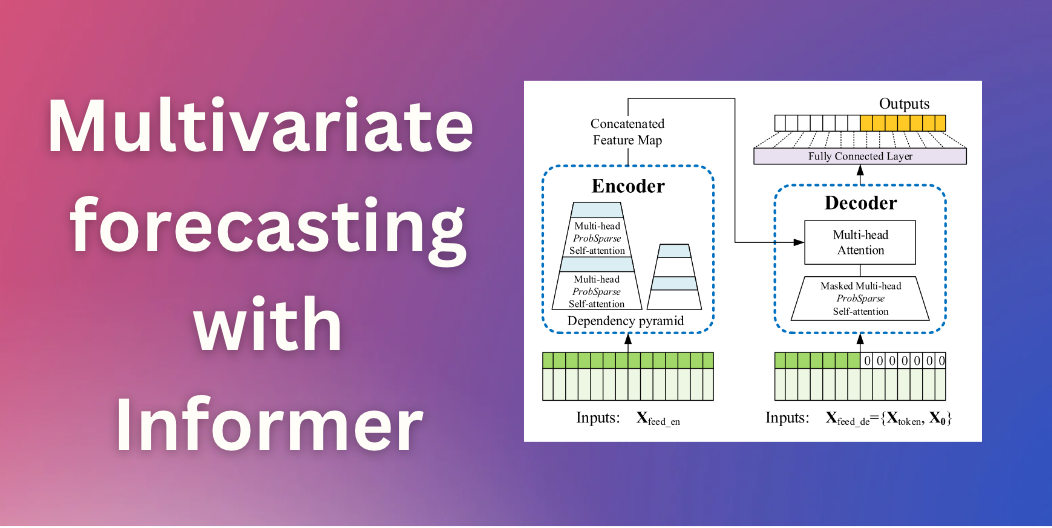
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…
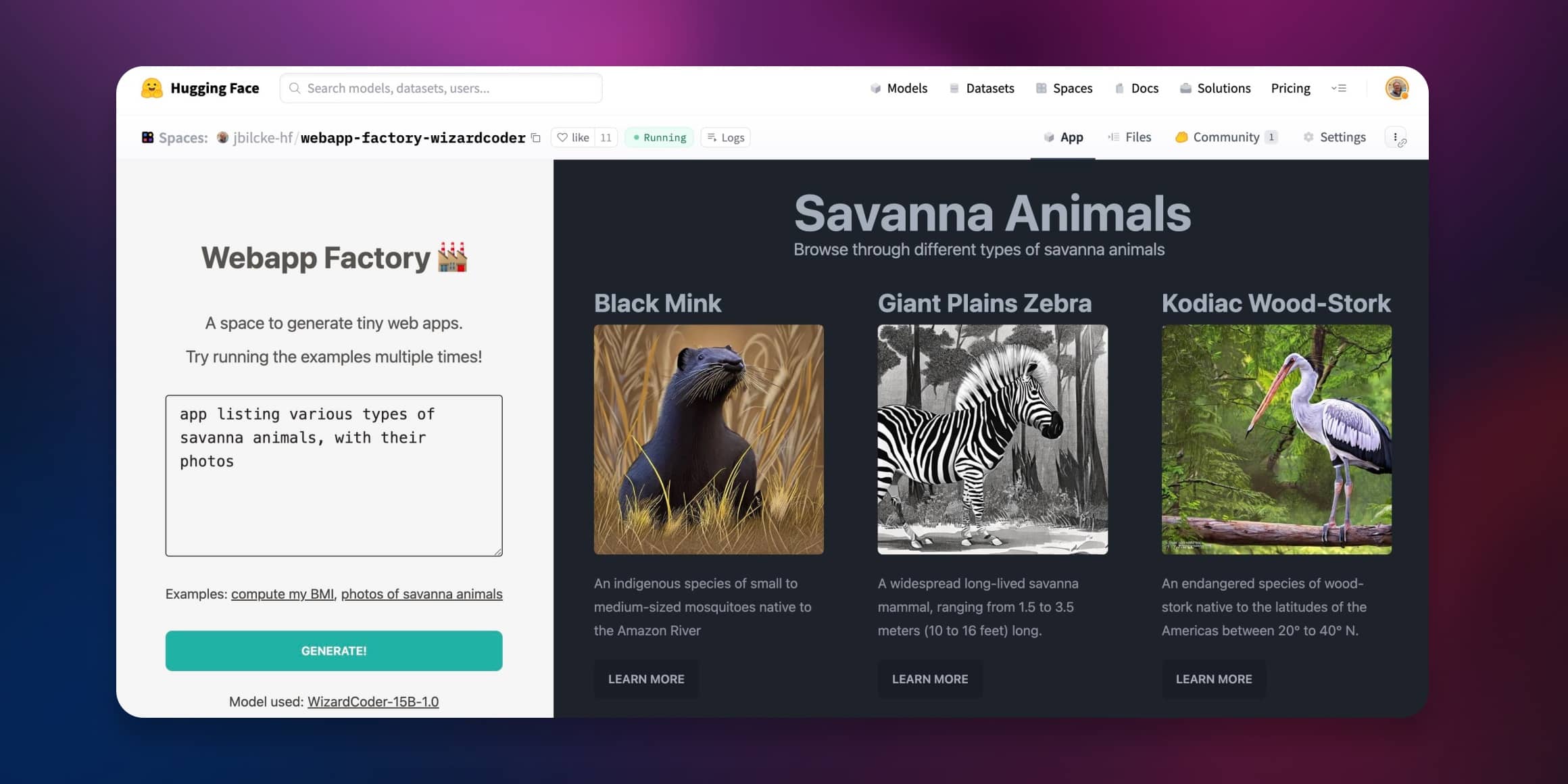
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…
Taipy:ユーザーフレンドリーな本番用データサイエンティストアプリケーションを構築するためのツール
データサイエンティストとして、データの視覚化のためのダッシュボードを作成したり、データを視覚化したり、さらにはビジネスアプリケーションを実装して利害関係者が実行可能な意思決定を行うのをサポートするかもしれません
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.