Learn more about Search Results BART - Page 5

- You may be interested
- 「データ分析のためのトップ10のSQLプロジ...
- MIT-Pillar AI Collectiveが初めてのシー...
- NLP、NN、時系列:Google Trendsのデータ...
- グラフ、分析、そして生成AI グラフニュー...
- 「Amazon SageMakerを使用して、薬剤探索...
- 「データサイエンスの手法がビジネスの成...
- Jupyter × Hugging Face
- 「リンカーン研究所の4つの技術が2023年の...
- 大規模言語モデル(LLM)とは何ですか?LL...
- 「機械学習を学ぶにはどれくらいの時間が...
- Pic2Word:ゼロショット構成画像検索のた...
- マイクロソフト エージェントAIがIdea2Img...
- 「Amazon SageMakerを使用したフェデレー...
- ハグフェイスでの夏
- AIの今週、8月18日:OpenAIが財政的な問題...

「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。 この投稿は以下のセクションに分かれています: テキスト生成の概要 ライセンス Hugging FaceエコシステムのLLMサービス用ツール パラメータ効率の良いファインチューニング(PEFT) テキスト生成の概要 テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。 次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。 因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。 例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。 Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。 テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。 より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging…

自動化された進化が厳しい課題に取り組む
強化学習は、ラベルのないデータを好みの集合にグループ化することを目指し、人間による評価関数から得られる累積報酬を最大化することを目指しています

BentoML入門:統合AIアプリケーションフレームワークの紹介
この記事では、統合されたAIアプリケーションフレームワークであるBentoMLを使用して、機械学習モデルの展開を効率化する方法について探求します
「BentoML入門:統合AIアプリケーションフレームワーク」
この記事では、統合されたAIアプリケーションフレームワークであるBentoMLを使用して、機械学習モデルの展開を効率化する方法について探求します

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。 このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します! 以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています: P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…
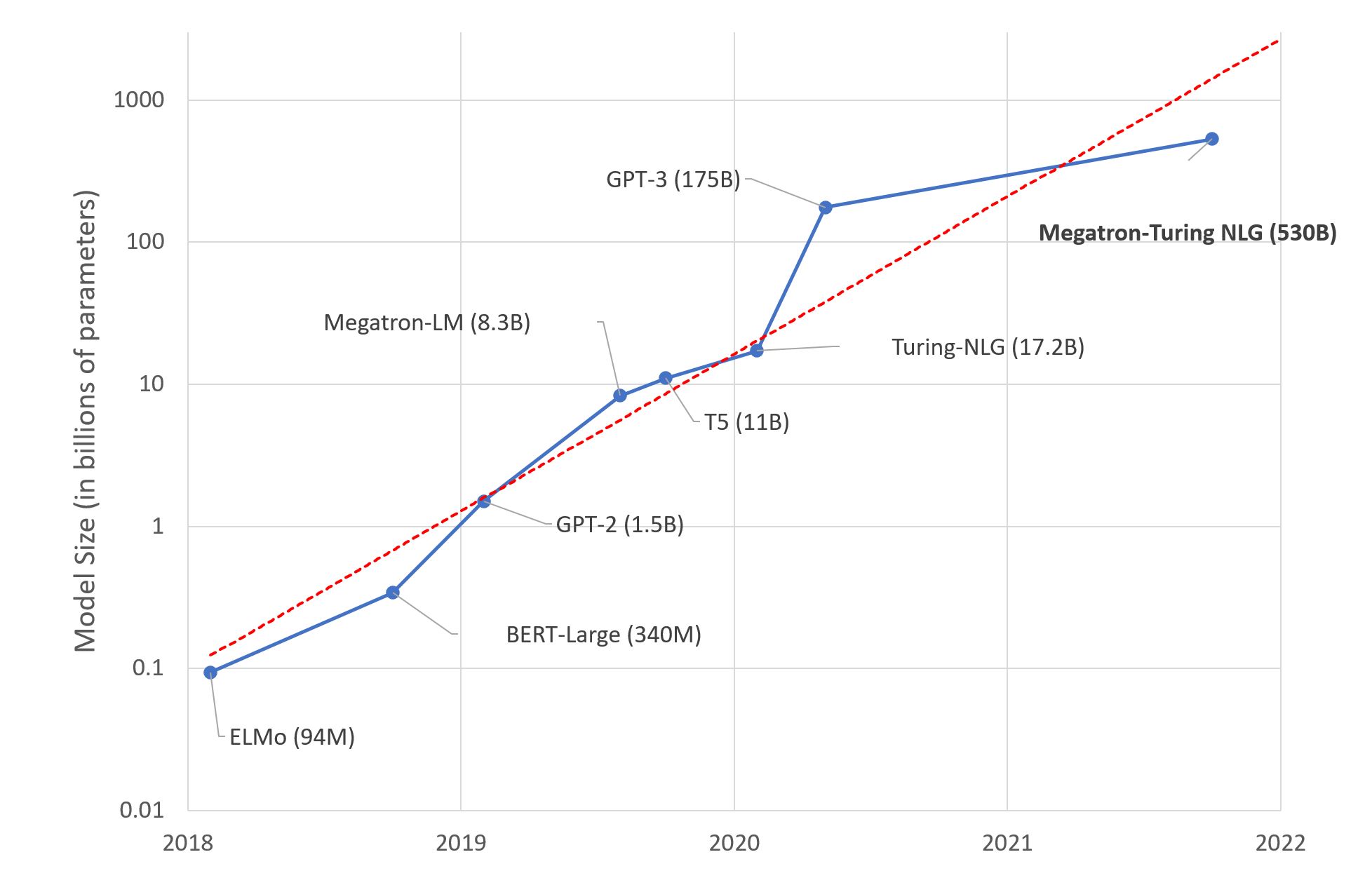
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.