Learn more about Search Results ベクトルストア - Page 5

- You may be interested
- 「文書理解の進展」
- ランチェーン101:パート2c PEFT、LORA、...
- 光ニューラルネットワークとトランスフォ...
- スタビリティAIによるステーブルオーディ...
- 商品化されたサービス101:フリーランサー...
- 「非構造化データファンネル」
- 「イギリス、ロシアが数年にわたり議員や...
- スピードは必要なすべてです:GPU意識の最...
- 「AIへの恐怖は迷信的なくだらないことだ」
- GoogleがNotebookLMを導入:あなた専用の...
- 「機械学習とAIが偽のレビューを迅速に検...
- 「目と耳を持つChatGPT:BuboGPTは、マル...
- LGBTQ+コミュニティをAI研究で支援する
- 効果的な小規模言語モデル:マイクロソフ...
- 「太陽エネルギーが新たな展開を迎える」

本番環境向けのベクトル検索の構築
ベクトルストアは、機械学習の進化において重要な役割を果たし、データの数値エンコーディングのための必須のリポジトリとして機能しますベクトルは、多次元空間におけるカテゴリカルなデータポイントを表すために使用される数学的なエンティティです機械学習の文脈では、ベクトルストアは、データの保存、取得、フィルタリングを行う手段を提供します

『LangChain & Flan-T5 XXL の解除 | 効率的なドキュメントクエリのガイド』
はじめに 大規模言語モデル(LLM)として知られる特定の人工知能モデルは、人間のようなテキストを理解し生成するために設計されています。”大規模”という用語は、それらが持つパラメータの数によってしばしば定量化されます。たとえば、OpenAIのGPT-3モデルは1750億個のパラメータを持っています。これらのモデルは、テキストの翻訳、質問への回答、エッセイの執筆、テキストの要約など、さまざまなタスクに使用することができます。LLMの機能を示すリソースやそれらとチャットアプリケーションを設定するためのガイダンスが豊富にありますが、実際のビジネスシナリオにおける適用可能性を徹底的に検討した試みはほとんどありません。この記事では、LangChain&Flan-T5 XXLを活用して、大規模言語ベースのアプリケーションを構築するためのドキュメントクエリングシステムを作成する方法について学びます。 学習目標 技術的な詳細に踏み込む前に、この記事の学習目標を確立しましょう: LangChainを活用して大規模言語ベースのアプリケーションを構築する方法を理解する テキスト対テキストフレームワークとFlan-T5モデルの簡潔な概要 LangChain&任意のLLMモデルを使用してドキュメントクエリシステムを作成する方法 これらの概念を理解するために、これらのセクションについて詳しく説明します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 LLMアプリケーションの構築におけるLangChainの役割 LangChainフレームワークは、チャットボット、生成型質問応答(GQA)、要約など、大規模言語モデル(LLM)の機能を活用したさまざまなアプリケーションの開発に設計されています。LangChainは、ドキュメントクエリングシステムを構築するための包括的なソリューションを提供します。これには、コーパスの前処理、チャンキングによるこれらのチャンクのベクトル空間への変換、クエリが行われたときに類似のチャンクを特定し、適切な回答にドキュメントを洗練するための言語モデルの活用が含まれます。 Flan-T5モデルの概要 Flan-T5は、Googleの研究者によって商業的に利用可能なオープンソースのLLMです。これはT5(Text-To-Text Transfer Transformer)モデルの派生モデルです。T5は、”テキスト対テキスト”フレームワークでトレーニングされた最先端の言語モデルです。さまざまなNLPタスクを実行するために、タスクをテキストベースの形式に変換することでトレーニングされます。FLANは、Finetuned Language Netの略です。 ドキュメントクエリシステムの構築に入りましょう LangChainとFlan-T5 XXLモデルを使用して、Google Colabの無料版でこのドキュメントクエリシステムを構築することができます。以下の手順に従ってドキュメントクエリシステムを構築しましょう: 1:必要なライブラリのインポート 以下のライブラリをインポートする必要があります:…
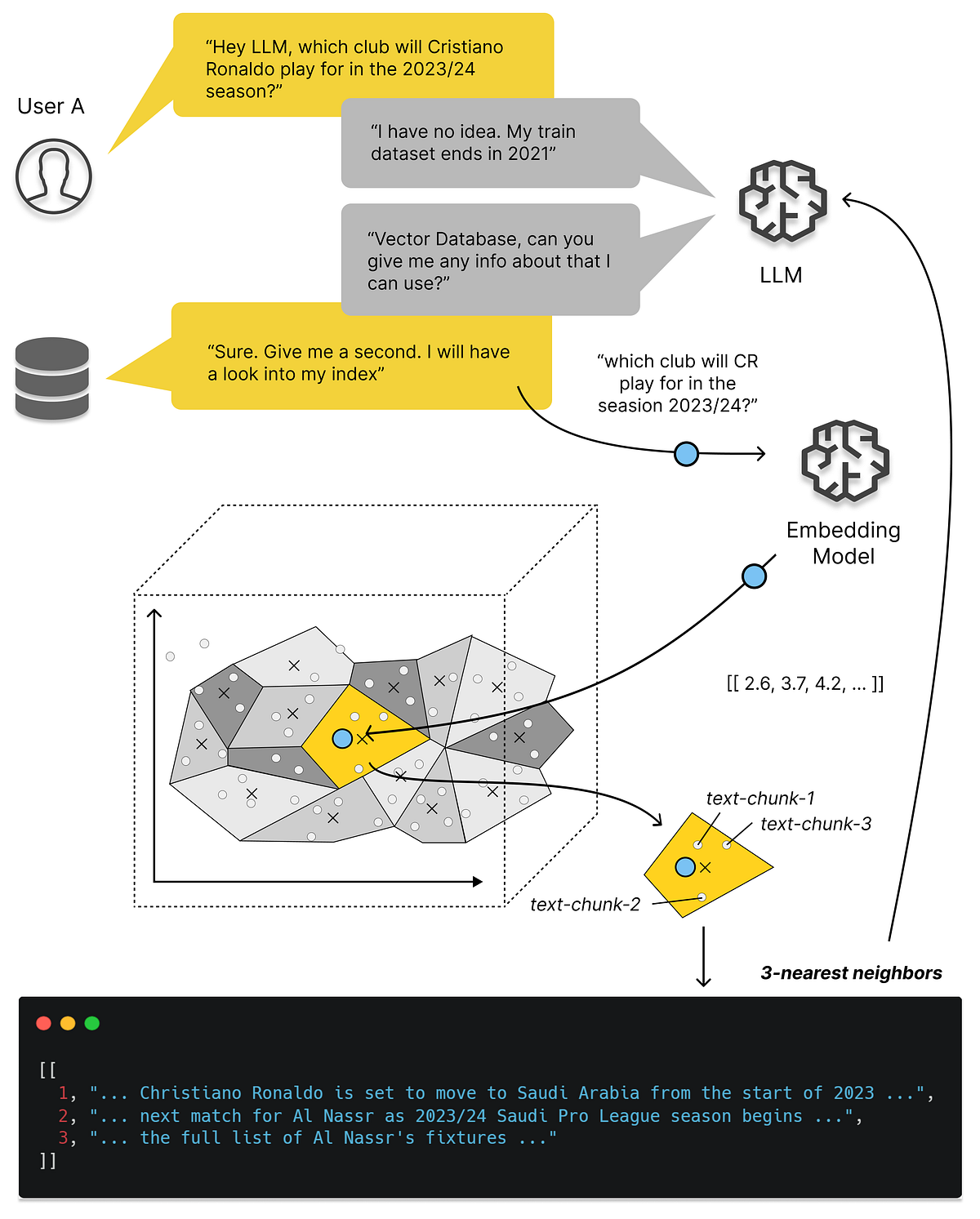
ベクトルデータベースについて知っておくべきすべてと、それらを使用してLLMアプリを拡張する方法
「ベクトルデータベースの特別な点は何ですか? 文の意味を数値表現にどのようにマッピングしますか? それが私たちのLLMアプリにどのように役立ちますか? なぜ私たちは単にLLMに持っているすべてのデータを与えることができないのですか…」

「LangchainとDeep Lakeでドキュメントを検索してください!」
イントロダクション langchainやdeep lakeのような大規模言語モデルは、ドキュメントQ&Aや情報検索の分野で大きな進歩を遂げています。これらのモデルは世界について多くの知識を持っていますが、時には自分が何を知らないかを知ることに苦労することがあります。それにより、知識の欠落を埋めるためにでたらめな情報を作り出すことがありますが、これは良いことではありません。 しかし、Retrieval Augmented Generation(RAG)という新しい手法が有望です。RAGを使用して、プライベートな知識ベースと組み合わせてLLMにクエリを投げることで、これらのモデルをより良くすることができます。これにより、彼らはデータソースから追加の情報を得ることができ、イノベーションを促進し、十分な情報がない場合の誤りを減らすことができます。 RAGは、プロンプトを独自のデータで強化することによって機能し、大規模言語モデルの知識を高め、同時に幻覚の発生を減らします。 学習目標 1. RAGのアプローチとその利点の理解 2. ドキュメントQ&Aの課題の認識 3. シンプルな生成とRetrieval Augmented Generationの違い 4. Doc-QnAのような業界のユースケースでのRAGの実践 この学習記事の最後までに、Retrieval Augmented Generation(RAG)とそのドキュメントの質問応答と情報検索におけるLLMのパフォーマンス向上への応用について、しっかりと理解を持つことができるでしょう。 この記事はデータサイエンスブログマラソンの一環として公開されました。 はじめに ドキュメントの質問応答に関して、理想的な解決策は、モデルに質問があった時に必要な情報をすぐに与えることです。しかし、どの情報が関連しているかを決定することは難しい場合があり、大規模言語モデルがどのような動作をするかに依存します。これがRAGの概念が重要になる理由です。…

「カタストロフィックな忘却を防ぎつつ、タスクに微調整されたモデルのファインチューニングにqLoRAを活用する:LLaMA2(-chat)との事例研究」
大規模言語モデル(LLM)のAnthropicのClaudeやMetaのLLaMA2などは、さまざまな自然言語タスクで印象的な能力を示していますしかし、その知識とタスク固有の...
大規模言語モデルのコード解読:Databricksが教えてくれたこと
「ファインチューニング、フラッシュアテンション、LoRa、AliBi、PEFTなどの技術を使用して、カスタムモデルを開発することにより、自分自身のエンドツーエンドのプロダクションレディなLLMワークフローの構築を学びましょう」
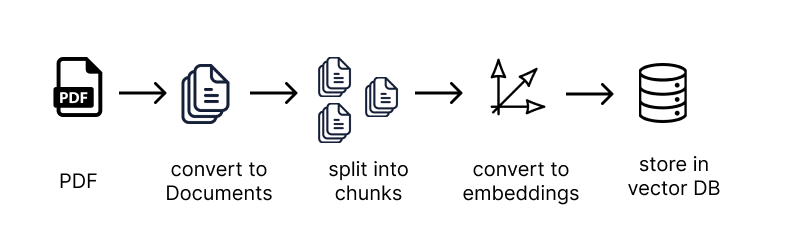
「ワイルドワイルドRAG…(パート1)」
「RAG(Retrieval-Augmented Generation)は、外部の知識源を取り込むことで言語モデルによって生成された応答の品質を向上させるAIフレームワークですこれにより、…のギャップを埋める役割を果たします」

「Langchainとは何ですか?そして、大規模言語モデルとは何ですか?」
この包括的な記事では、LangChainとLarge Language Modelsの両方を探求します両方を理解するために、簡単なチュートリアルを進めていきます

このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
最近、機械学習の検索分野において、深層ニューラルネットワークを応用することで大きな進歩がありました。特に、バイエンコーダーアーキテクチャ内の表現学習に重点を置いています。このフレームワークでは、クエリ、パッセージ、さらには画像などのマルチメディアなど、さまざまな種類のコンテンツが、密なベクトルとして表されるコンパクトで意味のある「埋め込み」として変換されます。このアーキテクチャに基づいて構築されたこれらの密な検索モデルは、大規模な言語モデル(LLM)内の検索プロセスの強化の基盤として機能します。このアプローチは人気があり、現在の生成的AIの広い範囲でLLMの全体的な能力を高めるのに非常に効果的であることが証明されています。 この論文では、多くの密なベクトルを処理する必要があるため、企業は「AIスタック」に専用の「ベクトルストア」または「ベクトルデータベース」を組み込むべきだと示唆しています。一部のスタートアップ企業は、これらのベクトルストアを革新的で不可欠な現代の企業アーキテクチャの要素として積極的に推進しています。有名な例には、Pinecone、Weaviate、Chroma、Milvus、Qdrantなどがあります。一部の支持者は、これらのベクトルデータベースが従来のリレーショナルデータベースをいずれ置き換える可能性さえ示しています。 この論文では、この説に対して反論を示しています。その議論は、既存の多くの組織で存在し、これらの機能に大きな投資がなされているという点を考慮した、簡単なコスト対効果分析を中心に展開されています。生産インフラストラクチャは、Elasticsearch、OpenSearch、Solrなどのプラットフォームによって主導されている、オープンソースのLucene検索ライブラリを中心とした広範なエコシステムによって支配されています。 https://arxiv.org/abs/2308.14963 上記の画像は、標準的なバイエンコーダーアーキテクチャを示しており、エンコーダーがクエリとドキュメント(パッセージ)から密なベクトル表現(埋め込み)を生成します。検索はベクトル空間内のk最近傍探索としてフレーム化されています。実験は、ウェブから抽出された約880万のパッセージから構成されるMS MARCOパッセージランキングテストコレクションに焦点を当てて行われました。評価には、標準の開発クエリとTREC 2019およびTREC 2020 Deep Learning Tracksのクエリが使用されました。 調査結果は、今日ではLuceneを直接使用してOpenAIの埋め込みを使用したベクトル検索のプロトタイプを構築することが可能であることを示唆しています。埋め込みAPIの人気の増加は、私たちの主張を支持しています。これらのAPIは、コンテンツから密なベクトルを生成する複雑なプロセスを簡素化し、実践者にとってよりアクセスしやすくしています。実際には、今日の検索エコシステムを構築する際に必要なのはLuceneだけです。しかし、時間が経って初めて正しいかどうかがわかります。最後に、これはコストと利益を比較することが主要な考え方であり続けることを思い起こさせてくれるものです。急速に進化するAIの世界でも同様です。

「PDF、txt、そしてウェブページとして、あなたのドキュメントと話しましょう」
LLMsを使用してPDF、TXT、さらにはウェブページなどのドキュメントに質問をすることができるウェブと知能を作成するための完全ガイド
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.