Learn more about Search Results ブートストラップ - Page 5

- You may be interested
- 中国のこのAI研究は、AIの幻覚を探求する...
- 「データ冗長性とは何ですか?利点、欠点...
- 「Unblock Your Software Engineers With ...
- 「機械学習の方法の比較:従来の方法と費...
- 数学的な問題解決におけるLLMの潜在能力を...
- データプロジェクトが現実的な影響をもた...
- 「仮想マシンのゲームパフォーマンスを向...
- ランキング評価指標の包括的ガイド
- LLMOPS vs MLOPS AI開発における最良の選...
- 「Inside LlaVA GPT-4Vのオープンソースの...
- 研究者たちは「絶対的に安全な」量子デジ...
- AIはロボットが全身を使ってオブジェクト...
- Inflection AIは、テックの巨人や業界の巨...
- 04/12から10/12までの週のための重要なコ...
- 「動きのあるAIトレンドに対応するAPI戦略...

事前学習済みの拡散モデルによる画像合成
「テキストから画像への拡散モデルは、自然言語の説明に基づいて写実的な画像を生成することで驚異的なパフォーマンスを達成していますオープンソースの事前学習済みモデルのリリースにより…」

「データサイエンスの役割に関するGoogleのトップ50のインタビュー質問」
イントロダクション Googleでのキャリアを手に入れるためのコードを解読することは、多くのデータサイエンティスト志望者にとっての夢です。しかし、厳しいデータサイエンスの面接プロセスをクリアするにはどうすればよいのでしょうか?面接で成功するために、機械学習、統計学、プロダクトセンス、行動面をカバーするトップ50のGoogleのインタビュー質問の包括的なリストを作成しました。これらの質問に慣れて、回答の練習をしてください。これにより、面接官に印象を与え、Googleでのポジションを確保する可能性が高まります。 データサイエンスのGoogle面接プロセス Googleのデータサイエンティストの面接を通過することは、あなたのスキルと能力を評価するエキサイティングな旅です。このプロセスには、データサイエンス、問題解決、コーディング、統計学、コミュニケーションなど、さまざまなラウンドが含まれています。以下は、あなたが期待できる内容の概要です: ステージ 説明 応募の提出 Googleのキャリアウェブサイトを通じて、採用プロセスを開始するために応募と履歴書を提出します。 テクニカルな電話スクリーン 選考された場合、コーディングスキル、統計学の知識、データ分析の経験を評価するためにテクニカルな電話スクリーンが行われます。 オンサイト面接 成功した候補者は、通常、データサイエンティストや技術的な専門家との複数のラウンドからなるオンサイト面接に進みます。これらの面接では、データ分析、アルゴリズム、統計学、機械学習の概念など、より深く掘り下げたトピックについて話し合います。 コーディングと分析の課題 プログラミングスキルを評価するためにコーディングの課題に取り組み、データから洞察を抽出する能力を評価するために分析の課題に直面します。 システム設計と行動面の面接 一部の面接ではシステム設計に焦点を当て、スケーラブルなデータ処理や分析システムの設計を期待されることがあります。また、行動面の面接では、チームワーク、コミュニケーション、問題解決のアプローチを評価します。 採用委員会の審査 面接のフィードバックは採用委員会によって審査され、最終的な採用の決定が行われます。 Googleデータサイエンティストになる方法についての詳細な応募と面接のプロセスについては、当社の記事をご覧ください! データサイエンスの役職に関するトップ50のGoogleインタビューの質問と回答をまとめました。 データサイエンスのためのトップ50のGoogleインタビュー質問 機械学習、統計学、コーディングなどをカバーするトップ50のインタビュー質問の包括的なリストで、Googleのデータサイエンスの面接に備えてください。これらの質問をマスターし、あなたの専門知識を示して、Googleでのポジションを確保しましょう。 Googleの機械学習とAIに関するインタビューの質問 1.…
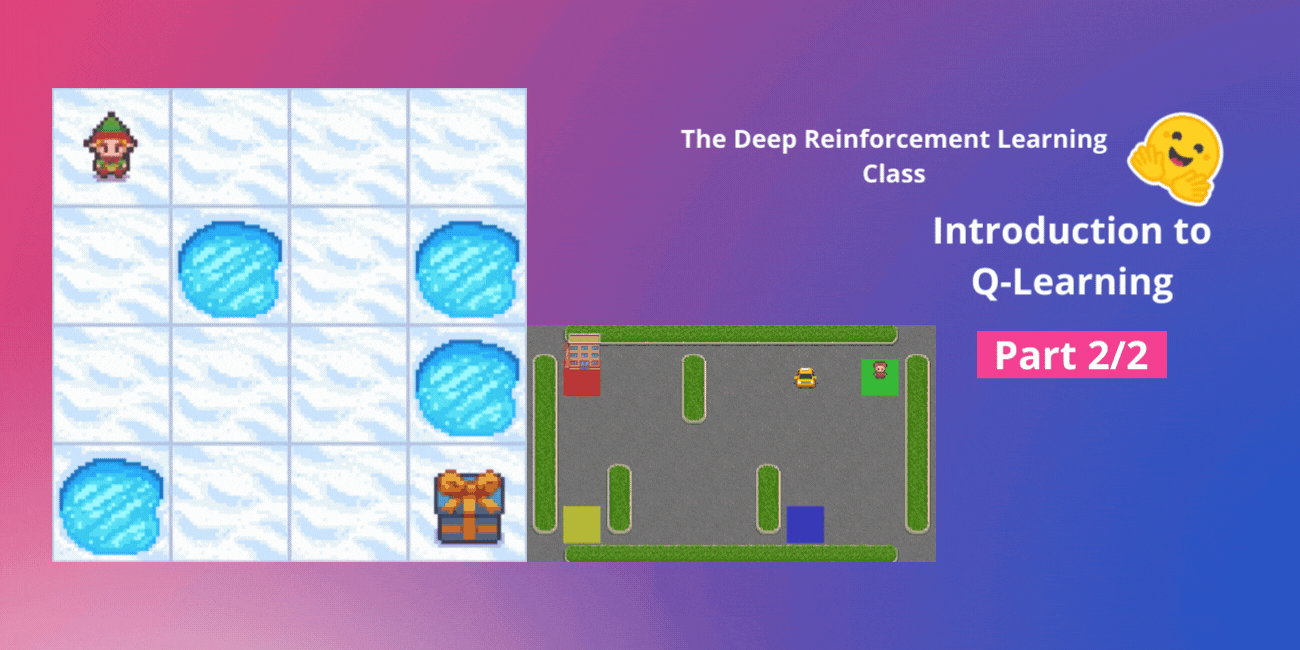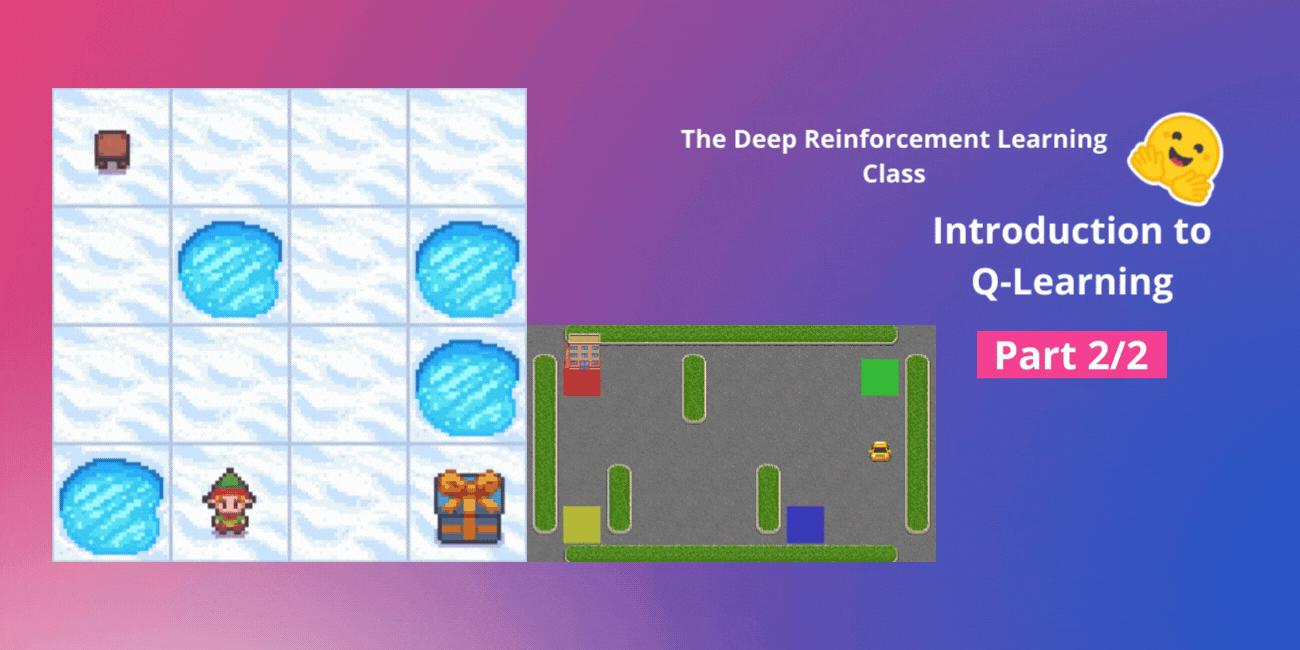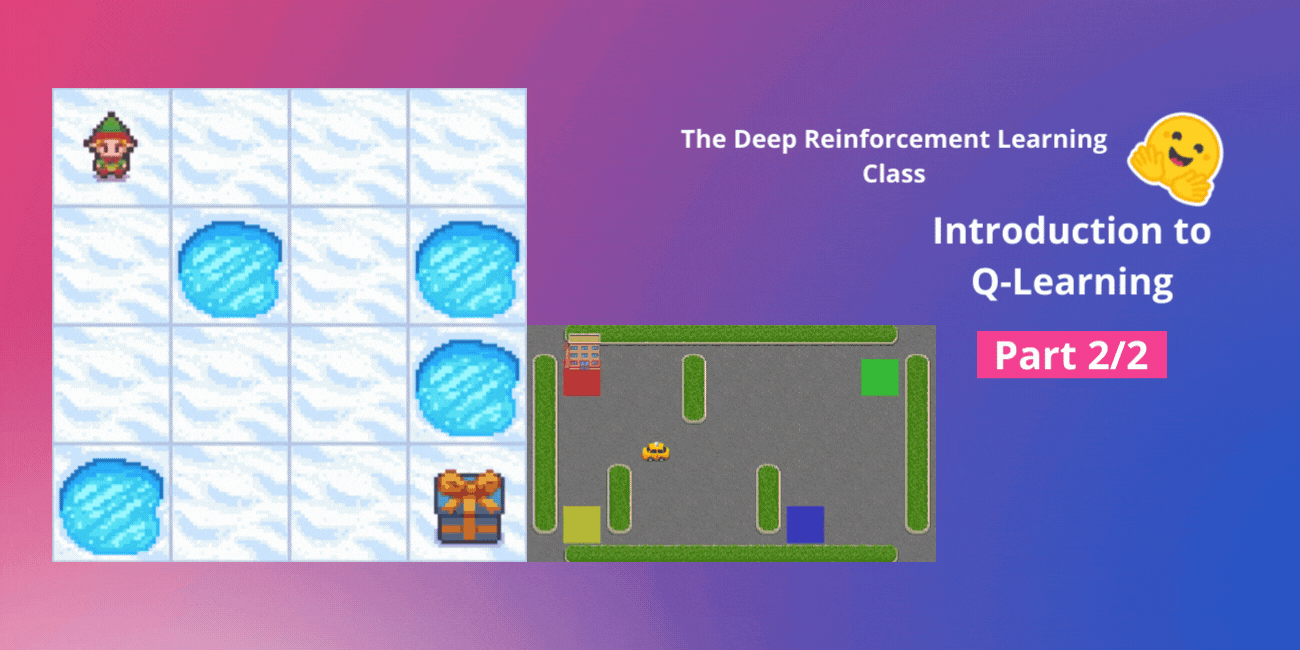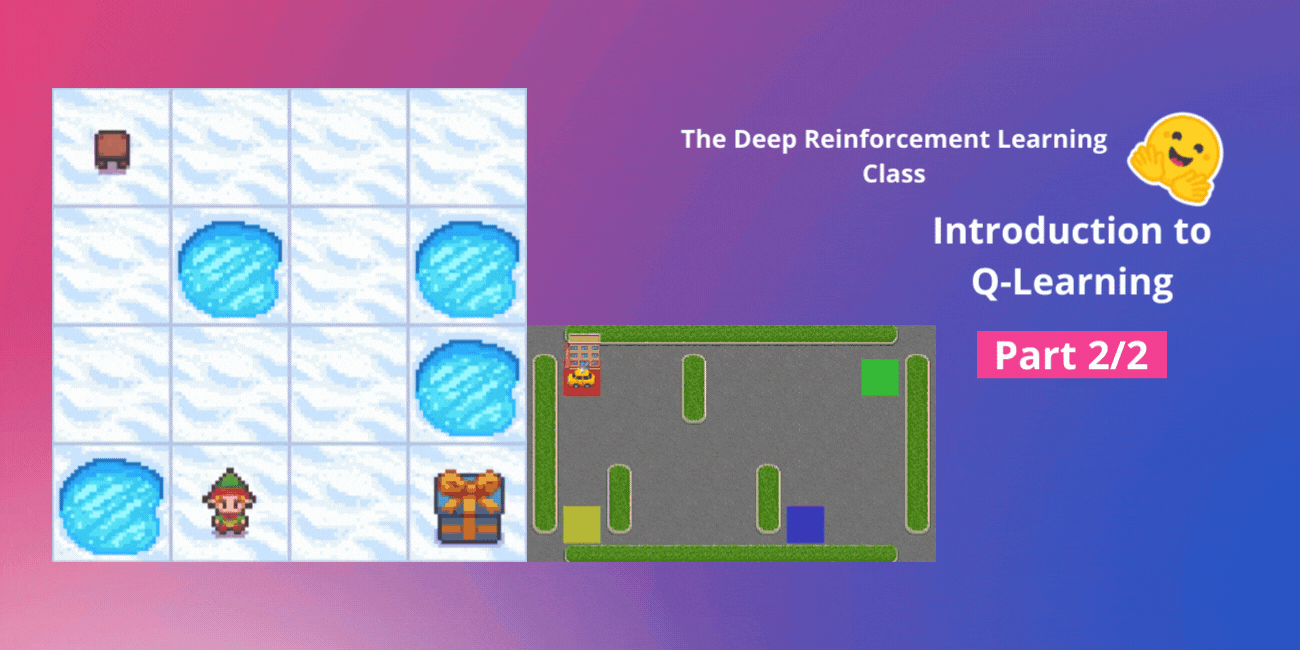
Q-Learningの紹介 パート2/2
ディープ強化学習クラスのユニット2、パート2(Hugging Faceと共に) ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 このユニットの第1部では、価値ベースの手法とモンテカルロ法と時差学習の違いについて学びました。 したがって、第2部では、Q-Learningを学び、スクラッチから最初のRLエージェントであるQ-Learningエージェントを実装し、2つの環境でトレーニングします: 凍った湖 v1 ❄️:エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)に移動する必要があります。 自律運転タクシー 🚕:エージェントは都市をナビゲートし、乗客を地点Aから地点Bに輸送する必要があります。 このユニットは、ディープQ-Learning(ユニット3)で作業を行うためには基礎となるものです。 では、始めましょう! 🚀 Q-Learningの紹介 Q-Learningとは?…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

一般的に、オープンエンドの遊びから優れたエージェントが生まれる
近年、人工知能エージェントは複雑なゲーム環境で成功を収めています例えば、AlphaZeroは、プレイ方法の基本ルールを知らないままスタートし、チェス、将棋、囲碁の世界チャンピオンプログラムに勝利しました強化学習(RL)を通じて、この単一のシステムは、試行錯誤の反復的なプロセスを通じて、ゲームのラウンドごとにプレイすることで学習しましたしかし、AlphaZeroはまだ各ゲームごとに別々にトレーニングを行いましたRLのプロセスをゼロから繰り返さなければ、別のゲームやタスクを単純に学習することはできませんでしたAtari、Capture the Flag、StarCraft II、Dota 2、Hide-and-Seekなど、RLの他の成功も同様ですDeepMindの使命である科学と人類の進歩のための知能の解決策を見つけるために、私たちはこの制限を克服する方法を探求しました一度に1つのゲームを学習する代わりに、これらのエージェントは完全に新しい条件に反応し、見たこともないゲームやタスクを含む、さまざまなゲームやタスクをプレイできるようになるはずです
合成データのフィールドガイド
データを扱いたい場合、どのような選択肢がありますか?できるだけざっくりした回答をお伝えします実際のデータを入手するか、偽のデータを入手するかのどちらかです前回の記事では、私たちは...

ロッテン・トマト映画評価予測のデータサイエンスプロジェクト:最初のアプローチ
数値およびカテゴリカルな特徴に基づく映画の状態予測
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.