Learn more about Search Results トラクター - Page 5

- You may be interested
- テスト自動化のためのトップ5のAIパワード...
- 「大学は、量子の未来のためにエンジニア...
- 「機械学習における10種類のクラスタリン...
- 「Salesforce Data Cloudを使用して、Amaz...
- 2024年のインフラストラクチャー予測
- 2023年のトップDNSプライバシーツール
- 「パクストンAIの共同創業者兼CEO、タング...
- Gradient Checkpointing、LoRA、およびQua...
- 「LoRAとQLoRAを用いた大規模言語モデルの...
- ChatGPTでリードマグネットのアイデアをブ...
- デジタルCXチャンネルの調和:現代の組織...
- インクから洞察:ブックショップの分析を...
- RAGアプリケーションデザインにおける実用...
- 画像からテキストを抽出するためのトップ5...
- 「MITの研究者たちは、人工知能(AI)の技...
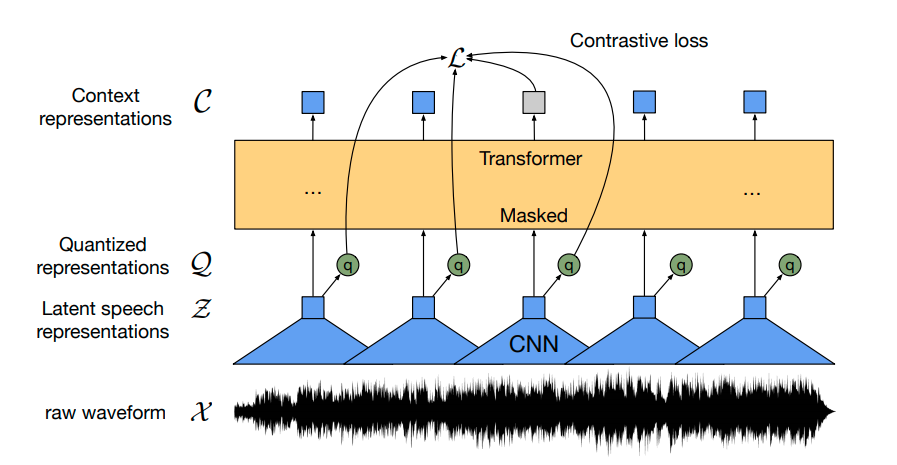
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…

教育のためのHugging Faceをご紹介します 🤗
機械学習がソフトウェア開発の圧倒的な割合を占めること、非技術的な人々がますますAIシステムに触れることを考えると、AIの主な課題の1つは従業員のスキルを適応・向上させることです。また、AIの倫理的および重要な問題を積極的に考慮するために教育スタッフをサポートする必要があります。 Hugging Faceは機械学習を民主化するオープンソース企業として、世界中のあらゆるバックグラウンドの人々に教育を提供することが重要だと考えています。 私たちは2022年3月にMLデモクラタイゼーションツアーを開始し、Hugging Faceの専門家が16カ国の1000人以上の学生に対して実践的な機械学習クラスを教えました。新しい目標は、「2023年末までに500万人に機械学習を教える」ことです。 このブログ記事では、教育に関する目標達成方法の概要を提供します。 🤗 すべての人のための教育 🗣️ 私たちの目標は、機械学習の可能性と限界を誰にでも理解してもらうことです。これによって、これらの技術の応用が社会全体にとって正味の利益につながる方向へ進化すると信じています。 私たちの既存の取り組みの一部の例: 私たちはMLモデルのさまざまな使い方(要約、テキスト生成、物体検出など)を非常にわかりやすく説明しています。 モデルページのウィジェットを通じて、誰でも直接ブラウザでモデルを試すことができるようにしています。そのため、それを行うための技術的なスキルの必要性を低下させています(例)。 システムで特定された有害なバイアスについてドキュメント化し、警告しています(GPT-2など)。 誰でも1クリックでMLの潜在能力を理解できるオープンソースのMLアプリを作成するためのツールを提供しています。 🤗 初心者向けの教育 🗣️ 私たちは、オンラインコース、実践的なワークショップ、その他の革新的な技術を提供することで、機械学習エンジニアになるためのハードルを下げたいと考えています。 私たちは自然言語処理(NLP)やその他のドメインについての無料コースを提供しています(近日中に)。これらのコースでは、Hugging Faceエコシステムの無料ツールやライブラリを使用して学ぶことができます。このコースの最終目標は、(ほぼ)どんな機械学習の問題にもTransformerを適用する方法を学ぶことです! 私たちはDeep Reinforcement Learningについての無料コースを提供しています。このコースでは、理論と実践でDeep…

機械学習洞察のディレクター
機械学習のテーブルの席は、技術的なスキル、問題解決能力、ビジネスの洞察力など、ディレクターのような役職にしかないものです。 機械学習および/またはデータサイエンスのディレクターは、しばしばMLシステムの設計、数学の深い知識、MLフレームワークの熟知、リッチなデータアーキテクチャの理解、実世界のアプリケーションへのMLの適用経験、優れたコミュニケーションスキルを持つことが求められます。また、業界の最新動向に常に精通していることも期待されています。これは大変な注文です! これらの理由から、私たちはこのユニークなMLディレクターのグループにアクセスし、ヘルスケアからファイナンス、eコマース、SaaS、研究、メディアなど、さまざまな産業における彼らの現在のMLの洞察と業界のトレンドについての記事シリーズを作成しました。たとえば、あるディレクターは、MLを使用して空の空転トラック運転(約20%の時間が発生)をわずか19%に減らすことで、約10万人のアメリカ人の炭素排出量を削減できると指摘しています。注意:これは元ロケット科学者によって行われた即興の計算ですが、私たちはそれを受け入れます。 この最初のインストールでは、地中に埋まった地雷を検出するために地中レーダーを使用している研究者、元ロケット科学者、ツォンカ語に堪能なアマチュアゲーマー(クズ=こんにちは!)、バン生活を送っていた科学者、まだ実践的な高性能データサイエンスチームのコーチ、関係性、家族、犬、ピザを大切にするデータ実践者など、豊富なフィールドの洞察を持つ機械学習ディレクターの意見を紹介します。 🚀 さまざまな産業における機械学習ディレクターのトップと出会い、彼らの見解を聞いてみましょう: アーキ・ミトラ – Buzzfeedの機械学習ディレクター 背景:ビジネスにおけるMLの約束にバランスをもたらす。プロセスよりも人。希望よりも戦略。AIの利益よりもAIの倫理。ブラウン・ニューヨーカー。 興味深い事実:ツォンカ語を話すことができます(Googleで検索してください!)そしてYouth for Sevaを支援しています。 Buzzfeed:デジタルメディアに焦点を当てたアメリカのインターネットメディア、ニュース、エンターテイメント会社。 1. MLがメディアにポジティブな影響を与えたのはどのような点ですか? 顧客のためのプライバシー重視のパーソナライゼーション:すべてのユーザーは個別であり、長期的な関心事は安定していますが、短期的な関心事は確率的です。彼らはメディアとの関係がこれを反映することを期待しています。ハードウェアアクセラレーションの進歩と推奨のためのディープラーニングの組み合わせにより、この微妙なニュアンスを解読し、ユーザーに適切なコンテンツを適切なタイミングで適切なタッチポイントで提供する能力が解き放たれました。 メディア製作者のための支援ツール:メディアにおける制作者は限られた資産ですが、MLによる人間-ループアシストツールにより、彼らの創造的な能力を保護し、協力的なマシン-人間のフライホイールを解き放つことができました。適切なタイトル、画像、ビデオ、および/またはコンテンツに合わせて自動的に提案するだけの簡単なことでも、協力的なマシン-人間のフライホイールを解き放つことができます。 テストの締め付け:資本集約型のメディアベンチャーでは、ユーザーの共感を得る情報を収集する時間を短縮し、即座に行動する必要があります。ベイジアンテクニックのさまざまな手法と強化学習の進歩により、時間だけでなくそれに関連するコストも大幅に削減することができました。 2. メディア内の最大のMLの課題は何ですか? プライバシー、編集の声、公平な報道:メディアは今以上に民主主義の重要な柱です。MLはそれを尊重し、他のドメインや業界では明確に考慮されない制約の中で操作する必要があります。編集によるカリキュレーションされたコンテンツとプログラミングとMLによる推奨のバランスを見つけることは、依然として課題です。BuzzFeedにとってももう1つのユニークな課題は、インターネットは自由であるべきだと信じているため、他の企業とは異なり、ユーザーを追跡していないことです。 3. メディアへのMLの統合を試みる際に、よく見かける間違いは何ですか?…

ウェブ3.0とブロックチェーンの進化による洞察力の向上
イントロダクション ウェブ3.0とブロックチェーンに関する洞察を提供するコミュニティThird Blockを構築した熱心な人物であるアビシェク・カテリヤ氏との対話の中で、彼の前職でのJPモルガンでのデータアナリストとしての経験、コミュニティの力、そしてこの分野で成功するためのキャリア構築の視点について共有していただく予定です。 インタビューを始めましょう AV: 自己紹介とバックグラウンドについて教えてください。 アビシェク氏 : 私はアビシェク・カテリヤと申します。フルスタックソフトウェアエンジニアで、JPモルガン&チェースで3年間働いた後、カリフォルニア拠点のAIトレードファイナンススタートアップのTradeSunに参画しました。その間、非営利セクターでの経験も豊富にあります。私はRoti Bank Foundationの創設メンバーであり、ムンバイ周辺の飢えた人々に食事を提供するための食品回収モデルの構築に取り組んできました。設立から3年間で100万食に達するために、ハイデラバード、アラ、パトナ、ナグプル、プネなどの都市にも支部を展開しました。また、ムンバイの工学大学との協力プロジェクトとして、腐った食べ物の警告装置やムンバイのハンガーマップの開発も行いました。 また、Coding4all.inというイニシアチブの一環として、高校生に無料で基本的なプログラミングを教える活動にも参加しました。5ヶ月間で200人のコホートに到達しました。学生たちがラップトップやコンピュータを持たずにオンラインで学ぶことを可能にし、世界中のテック業界のエキスパートたちが講師として参加しています。これら以外にも、Web3とブロックチェーン技術に興味を持ち始め、JPモルガンのデジタル通貨であるJPMコインプロジェクトに取り組みました。仕事の傍ら、旅行やトレッキングが好きで、インスタグラム(@abhikuchbhi_blog)にストーリーを投稿したり、MBAの進学記録を(@mbabhikuchbhi)に投稿しています。 AV: テクノロジーとビジネスマネジメントのMBAを追求していますが、MBAの取得を促した要因は何ですか? アビシェク氏: COVIDの間にMBAの計画を諦めましたが、MBAを取得するためにウォートンに行きたいと思っていました。しかし、すべての選択肢を比較する中で、インドは今後の時代において本当に適切な場所であり、Masters’ Unionは私がインドのスタートアップエコシステムに関与するための有望なオプションとして浮かび上がりました。私はあまり考えずにMUに応募し、ヒマラヤでトレッキングに行きました。戻ってきた時にはインタビューの呼び出しがあり、1ヶ月後には入学が決まりました。私はここに来てスタートアップエコシステムをより深く理解し、私のネットワークに価値ある人材を追加するためです。これは本当に素晴らしい旅であり、賢明な決断でした。 AV: キャリアに影響を与えた人物をいくつか挙げていただけますか?どのように影響を受けましたか? アビシェク氏: 小さい頃、私はいつも「バットマン」と答えていました。アイドルやメンターを持つことの意味を理解することはありませんでしたが、私は常にグリットと努力に感銘を受けたバットマンを尊敬していました。だから、常に前進し、もっとやることを私にはバットマンがインスピレーションを与えています。その他に、私の父でありシリアルアントレプレナーでもあるプラフルクマールさん。彼のベンチャーは成功しなかったものの、彼の忍耐力とグリットは今でも私に「失敗したから何だ」と言い続けてくれます。Masters’ Unionの創設者、プラサム・ミッタルさん。彼は若く、エネルギッシュであり、何でも持っていると言っても過言ではありません。しかし、彼が仕事に注ぐ熱意、エネルギー、努力は本当に素晴らしく、私にとっては確かにインスピレーションです。 起業のインスピレーション AV:…

あなたの次の夢の役割(2023年)を見つけるのに役立つ、最高のAIツール15選
Resumaker.ai Resumaker.aiは、数分で履歴書を作成するのを支援するウェブサイトです。ポータルは、いくつかのカスタマイズ可能なデザイナー製履歴書テンプレートと直感的なツールを提供して、夢の仕事に就くのを手助けします。他の履歴書ビルダーとは異なり、Resumaker.aiの人工知能(AI)エンジンは、ユーザーのためにデータを自動的に完了・入力することで、履歴書作成プロセスを簡素化します。Resumaker.aiは、SSL暗号化などの対策を講じて、ユーザーデータを不正アクセスから保護します。ツールのライティングガイドとレコメンデーションを使用して、競合から目立つ履歴書をデザインすることができます。ユーザーは、投稿されたポジションの要件を反映させ、自己紹介を行い、自分の資格に関する主張を裏付けるために数字を活用することができます。 Interviewsby.ai 人工知能によって駆動されるプラットフォームであるInterviewsby.aiを使用することで、求職者はインタビューに備えることができます。ユーザーに合わせた模擬面接中に、人間の言葉を認識・解釈することができる言語モデルであるChatGPTがリアルタイムのフィードバックを提供します。希望する雇用に関する情報を入力することにより、アプリケーションはユーザーに適切で現実的なインタビューの質問を生成することができます。質問を作成する機能により、ユーザーが古くなったり関係のない素材でトレーニングする可能性がなくなります。Interviewsby.aiを使用することで、ユーザーはコントロールされた環境で面接スキルを磨き、自分の強みと弱みに注目した具体的なフィードバックを即座に受けることができます。 Existential ユーザーの興味、才能、価値観を評価することで、AIにより駆動される職業探索ツールであるExistentialは、ユーザーのプロフェッショナルな道筋について具体的な提言を行います。目的は、ユーザーにとって刺激的で挑戦的で満足のいく職業を示唆することです。アプリケーションには簡単な発見プロセスがあり、理想的な仕事に関する特定の質問に答えた後、プログラムはユーザーの興味に最も合った推奨事項を提供します。コミットする前に、ユーザーはこれらの選択肢について詳しく学び、自分の目的に合うかどうかを確認することができます。Existentialは、個人が自分の運命を形作り、仕事に意味を見出すことを目指しています。 Jobscan 求職者は、人工知能(AI)によって駆動されるJobscan ATS Resume CheckerおよびJob Search Toolsを使用することで、面接を受ける可能性を高めることができます。プログラムは、求人情報と応募者の履歴書を分析し、関連する資格を分離するための独自の人工知能アルゴリズムを使用します。応募者の履歴書を分析した後、プログラムは、応募者の強みと改善の余地がある部分を詳細に説明したマッチ率レポートを生成します。Jobscan ATS Resume Checkerの助けを借りて、あなたの履歴書をApplicant Tracking Systems(ATS)に最適化し、注目される可能性を高めることができます。 Aragon 人工知能(AI)によって駆動されるプログラムであるAragon Professional Headshotsは、写真家に行かずに、ヘアメイクに時間をかけずに、修正を待たずに、洗練されたヘッドショットを撮影できるようにするツールです。ユーザーは10枚のセルフィーをアップロードし、ツールは瞬時に40枚の高精細写真を返します。さらに、アプリケーションは、AES256でデータを暗号化し、SOC 2およびISO 27001の認定を取得したサービスプロバイダーにのみデータを保存することにより、ユーザーのプライバシーを保護します。ただし、18歳未満の人は利用しないでください。これは利用規約の違反となります。…

Btech卒業後に何をすべきですか?
Btechの後に何をすべきですか?このよくある質問は、最終学年や最近卒業した学生にとって悩みの種です。多くの人々が従来のキャリアパスを選ぶ一方、一部の人々は新しい分野でのキャリアを研究し探求することを決めます。より多くの選択肢を探索し、スキル開発に重点を置き、継続的な学習、進化する技術について常に最新情報を得ることにより、個人は速いペースのBtechの後の旅で成功することができます。この記事では、Btechの後の最良のキャリアオプションについて説明しています。 Btech卒業生の従来のキャリアパス エンジニアの仕事 ソフトウェアエンジニア/開発者: コンピューターサイエンスのBTechを持つソフトウェアエンジニアは、オンラインやモバイルアプリ、データベース管理、ソフトウェアアーキテクチャの開発に参加します。 ハードウェアエンジニア: ハードウェアエンジニアは、コンピューターハードウェアコンポーネントを作成、開発、テストし、最適な動作を確保します。 機械エンジニア: 製品設計、ロボット、産業機械など多様な産業で機械システムを開発、分析、構築します。 電気エンジニア: 電力発電、エレクトロニクス、通信、再生可能エネルギーシステムを計画、開発、維持します。 土木エンジニア: 建設、構造の安全性、環境持続性を維持しながら、インフラプロジェクトの計画、設計、構築、維持を行います。 宇宙航空エンジニア: 航空機、宇宙船、関連技術の設計、開発、テストの責任を担います。 化学エンジニア: 石油化学、医薬品、環境工学、材料科学など、幅広い産業でプロセスを作成、管理します。 環境エンジニア: 環境保護、持続可能性、廃棄物管理のソリューションを提供し、規制に適合します。 大学院研究と研究 MTechまたはME: BTech卒業生は、MTechまたはMEなどの大学院課程を追求することができます。これらには研究の可能性、高度なコースワーク、エンジニアリングの専門分野が含まれます。 MS: BTech卒業生は、研究、コースワーク、協力、論文の達成に焦点を当てた工学のMaster…

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。

最高のAIジョブコース(2023年)
健康、経済、教育、セキュリティなどの分野を改善する機会を提供する最高のAIジョブコースに飛び込んでください
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.