Learn more about Search Results このスクリプト - Page 5

- You may be interested
- MITとMeta AIからのこのAI研究は、高度な...
- 「新しいAI研究は、3D構造に基づいたタン...
- AIの革新的なイノベーションが開発者を強...
- ペンシルバニア大学の研究者が、軽量で柔...
- 新しいNVIDIA GPUベースのAmazon EC2イン...
- 「ハグフェース上のトップ10大きな言語モ...
- 「オートエンコーダを用いたMNIST画像の再...
- 「すべてのオンライン投稿は、AIの所有物...
- メタファーAPI:LLM向けに構築された革命...
- AIが私のいとこのような運動障害を持つ人...
- 「デジタル時代のユーザーセントリックデ...
- NVIDIAとUTオースティンの研究者がMimicGe...
- 「新しく進化したAmazon SageMaker Studio...
- お客様との関係を革新する:チャットとRea...
- Meta AIがAnyMALを紹介:テキスト、画像、...

🤗 Accelerate のご紹介
🤗 アクセラレート あらゆる種類のデバイスで、生の PyTorch のトレーニングスクリプトを実行できます。 PyTorch の上位レベルの多くのライブラリは、分散トレーニングや混合精度のサポートを提供していますが、それらが導入する抽象化により、ユーザーは基礎となるトレーニングループをカスタマイズするために新しい API を学ぶ必要があります。🤗 アクセラレートは、トレーニングループを完全に制御したい PyTorch ユーザーのために作成されましたが、分散トレーニング(複数のノード上のマルチ GPU、TPU など)、混合精度トレーニングに必要な骨格コードの記述(および保守)を行いたくないユーザーも対象です。今後の計画には、fairscale、deepseed、AWS SageMaker 特定のデータ並列処理とモデル並列処理のサポートも含まれます。 それは次の2つのことを提供します:骨格コードを抽象化するシンプルで一貫した API と、さまざまなセットアップでこれらのスクリプトを簡単に実行するための起動コマンドです。 簡単な統合! まずは例を見てみましょう: import torch import…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
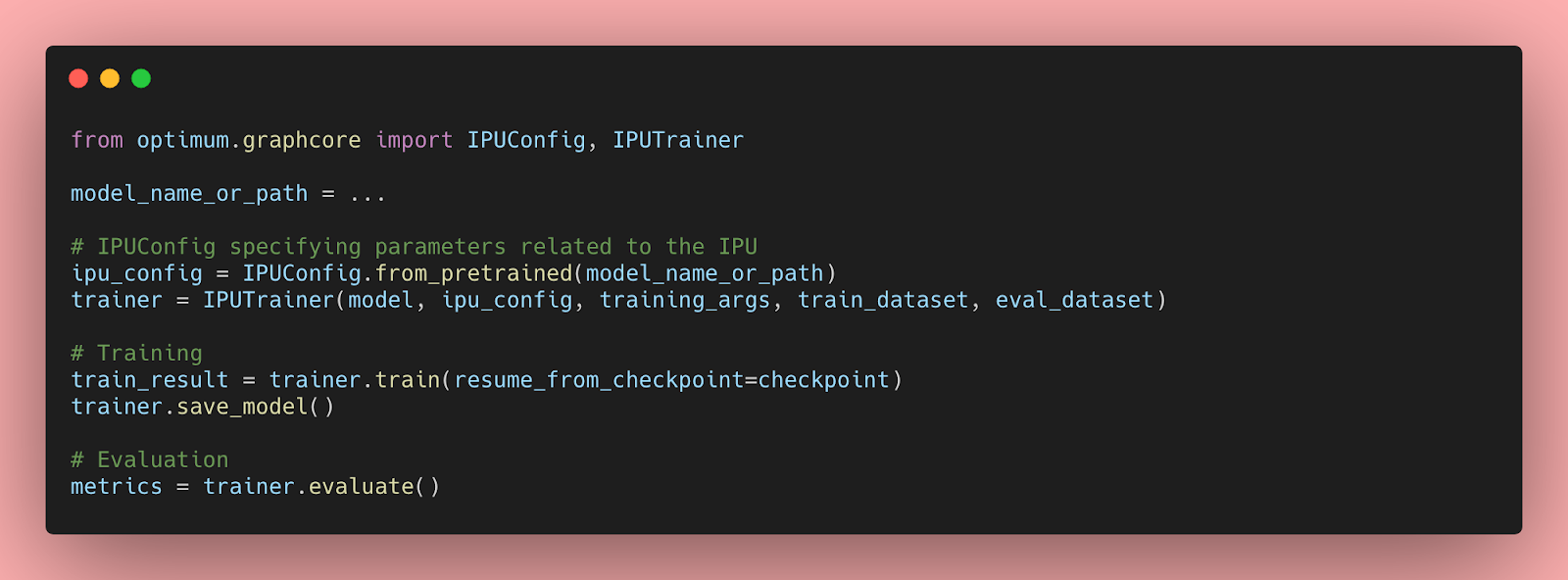
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

Hugging Face Transformers と Amazon SageMaker を使用して、GPT-J 6B を推論のためにデプロイします
約6ヶ月前の今日、EleutherAIはGPT-3のオープンソースの代替となるGPT-J 6Bをリリースしました。GPT-J 6BはEleutherAIs GPT-NEOファミリーの6,000,000,000パラメータの後継モデルであり、テキスト生成のためのGPTアーキテクチャに基づくトランスフォーマーベースの言語モデルです。 EleutherAIの主な目標は、GPT-3と同じサイズのモデルを訓練し、オープンライセンスの下で一般の人々に提供することです。 過去6ヶ月間、GPT-Jは研究者、データサイエンティスト、さらにはソフトウェア開発者から多くの関心を集めてきましたが、実世界のユースケースや製品にGPT-Jを本番環境に展開することは非常に困難でした。 Hugging Face Inference APIやEleutherAIs 6b playgroundなど、製品ワークロードでGPT-Jを使用するためのホステッドソリューションはいくつかありますが、自分自身の環境に簡単に展開する方法の例は少ないです。 このブログ記事では、Amazon SageMakerとHugging Face Inference Toolkitを使用して、数行のコードでGPT-Jを簡単に展開する方法を学びます。これにより、スケーラブルで信頼性の高いセキュアなリアルタイムの推論が可能な通常サイズのNVIDIA T4(約500ドル/月)のGPUインスタンスを使用します。 しかし、それに入る前に、なぜGPT-Jを本番環境に展開するのが困難なのかを説明したいと思います。 背景 6,000,000,000パラメータモデルの重みは、約24GBのメモリを使用します。float32でロードするためには、少なくとも2倍のモデルサイズのCPU RAMが必要です。初期重みのために1倍、チェックポイントのロードのために1倍です。したがって、GPT-Jをロードするには少なくとも48GBのCPU RAMが必要です。 モデルをよりアクセス可能にするために、EleutherAIはfloat16の重みを提供しており、transformersには大規模な言語モデルのロード時のメモリ使用量を削減する新しいオプションがあります。これらすべてを組み合わせると、モデルのロードにはおおよそ12.1GBのCPU…

高速なトレーニングと推論 Habana Gaudi®2 vs Nvidia A100 80GB
この記事では、Habana® Gaudi®2を使用してモデルのトレーニングと推論を高速化し、🤗 Optimum Habanaを使用してより大きなモデルをトレーニングする方法について説明します。さらに、BERTの事前トレーニング、Stable Diffusion推論、およびT5-3Bファインチューニングなど、第一世代のGaudi、Gaudi2、およびNvidia A100 80GBのパフォーマンスの違いを評価するためのいくつかのベンチマークを紹介します。ネタバレ注意 – Gaudi2はトレーニングと推論の両方でNvidia A100 80GBよりも約2倍高速です! Gaudi2は、Habana Labsが設計した第2世代のAIハードウェアアクセラレータです。単一のサーバには、各々96GBのメモリを持つ8つのアクセラレータデバイスが搭載されています(第一世代のGaudiでは32GB、A100 80GBでは80GB)。Habana SDKであるSynapseAIは、第一世代のGaudiとGaudi2の両方に共通しています。つまり、🤗 Optimus Habanaは、🤗 Transformersと🤗 DiffusersライブラリとSynapseAIの間の非常に使いやすいインターフェースを提供し、第一世代のGaudiと同じようにGaudi2でも動作します!ですので、既に第一世代のGaudi用の使用準備が整ったトレーニングや推論のワークフローがある場合は、何も変更することなくGaudi2で試してみることをお勧めします。 Gaudi2へのアクセス方法 IntelとHabanaがGaudi2を利用可能にするための簡単で費用効果の高い方法の1つは、Intel Developer Cloudで利用できるようになっています。そこでGaudi2を使用するためには、以下の手順に従う必要があります: Intel…

音声合成、音声認識、そしてSpeechT5を使ったその他の機能
私たちは喜んでお知らせします。SpeechT5は🤗Transformersで利用可能になりました。これは最先端の機械学習モデルの簡単に使用できる実装を提供するオープンソースライブラリです。 SpeechT5はもともと、Microsoft Research Asiaによって開発された論文「SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing」で説明されています。論文の著者が公開した公式のチェックポイントはHugging Face Hubで利用可能です。 すぐに試してみたい場合は、以下のデモがあります: 音声合成(TTS) 音声変換 自動音声認識 はじめに SpeechT5は、1つのアーキテクチャに3つの異なる種類の音声モデルを組み込んでいます。 以下のことができます: 音声からテキストへの変換(自動音声認識や話者識別に使用) テキストから音声への変換(音声を合成) 音声から音声への変換(異なる声や音声の強調を行う) SpeechT5の基本的なアイデアは、テキストから音声、音声からテキスト、テキストからテキスト、音声から音声までのデータの混合で単一のモデルを事前学習することです。これにより、モデルはテキストと音声の両方から同時に学習します。この事前学習アプローチの結果は、テキストと音声の両方に共有される統一された隠れ表現の空間を持つモデルです。…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
イントロダクション TPUトレーニングは有用なスキルです:TPUポッドは高性能で非常にスケーラブルであり、数千万から数百億のパラメータまで、どんなスケールでもモデルをトレーニングすることが容易です。GoogleのPaLMモデル(5000億パラメータ以上!)は完全にTPUポッドでトレーニングされました。 以前、TensorFlowを使用した小規模なTPUトレーニングと、TPUでモデルを動作させるために理解する必要がある基本的なコンセプトを紹介するチュートリアルとColabの例を作成しました。今回は、TensorFlowとTPUを使用してマスクされた言語モデルをゼロからトレーニングするためのすべての手順、トークナイザのトレーニングとデータセットの準備から最終的なモデルのトレーニングとアップロードまでを詳しく説明します。これはColabだけでなく、専用のTPUノード(またはVM)が必要なタスクであり、そこに焦点を当てます。 Colabの例と同様に、TensorFlowの非常にクリーンなTPUサポートであるXLAとTPUStrategyを活用しています。また、🤗 Transformers内のほとんどのTensorFlowモデルが完全にXLA互換であるという利点もあります。そのため、TPU上で実行するために必要な作業はほとんどありません。 ただし、この例はColabの例とは異なり、実際のトレーニングランに近いスケーラブルな例です。デフォルトではBERTサイズのモデルしか使用していませんが、いくつかの設定オプションを変更することで、コードをより大きなモデルとより強力なTPUポッドスライスに拡張することができます。 動機 なぜ今このガイドを書いているのでしょうか?実際、🤗 Transformersは何年もの間TensorFlowをサポートしてきましたが、これらのモデルをTPUでトレーニングすることはコミュニティにとって主要な問題でした。これは以下の理由によるものです: 多くのモデルがXLA互換ではなかった データコレクターがネイティブのTF操作を使用していなかった 私たちはXLAが将来の技術であると考えています。それはJAXのコアコンパイラであり、TensorFlowでの一流のサポートを受けており、PyTorchからも使用できます。そのため、私たちはコードベースをXLA互換にするために大きな取り組みを行い、XLAとTPUの互換性に立ちはだかるその他の障害を取り除きました。これにより、ユーザーは私たちのほとんどのTensorFlowモデルをTPUで煩わずにトレーニングできるはずです。 現在のLLM(言語モデル)と生成AIの最近の重要な進歩により、モデルのトレーニングに対する一般の関心が高まり、最新のGPUにアクセスすることが非常に困難になりました。TPUでのトレーニング方法を知っていると、超高性能な計算ハードウェアへのアクセスする別の方法を手に入れることができます。それは、eBayで最後のH100の入札戦に敗れてデスクで醜い泣きをするよりもずっと品位があります。あなたにはもっと良いものがふさわしいのです。そして経験から言えることですが、TPUでのトレーニングに慣れると、戻りたくなくなるかもしれません。 予想されること WikiTextデータセット(v1)を使用してRoBERTa(ベースモデル)をゼロからトレーニングします。モデルのトレーニングだけでなく、トークナイザをトレーニングし、データをトークン化してTFRecord形式でGoogle Cloud Storageにアップロードし、TPUトレーニングでアクセスできるようにします。コードはこのディレクトリにあります。ある種の人にとっては、このブログ投稿の残りをスキップして、コードに直接ジャンプすることもできます。ただし、しばらくお付き合いいただければ、コードベースのいくつかのキーポイントについて詳しく見ていきます。 ここで紹介するアイデアの多くは、私たちのColabの例でも触れられていましたが、それらをすべて組み合わせて実際に動作するフルエンドツーエンドの例をユーザーに示したかったのです。次の図は、🤗 Transformersを使用した言語モデルのトレーニングに関わる手順の概要を図解したものです。TensorFlowとTPUを使用しています。 データの取得とトークナイザのトレーニング 先述のように、WikiTextデータセット(v1)を使用しました。データセットの詳細については、Hugging Face Hubのデータセットページにアクセスして調べることができます。 データセットは既に互換性のある形式でHubに利用可能なので、🤗 datasetsを使用して簡単にロードして操作することができます。ただし、この例ではトークナイザをゼロから学習しているため、以下のような手順を踏んでいます:…

Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
この投稿では、安定拡散を教えるための指示調整について説明します。この方法では、入力画像と「指示」(例:自然画像に漫画フィルタを適用する)を使用して、安定拡散を促すことができます。 ユーザーの指示に従って安定拡散に画像編集を実行させるアイデアは、「InstructPix2Pix: Learning to Follow Image Editing Instructions」で紹介されました。InstructPix2Pixのトレーニング戦略を拡張して、画像変換(漫画化など)や低レベルな画像処理(画像の雨除去など)に関連するより具体的な指示に従う方法について説明します。以下をカバーします: 指示調整の紹介 この研究の動機 データセットの準備 トレーニング実験と結果 潜在的な応用と制約 オープンな問い コード、事前学習済みモデル、データセットはこちらで見つけることができます。 導入と動機 指示調整は、タスクを解決するために言語モデルに指示を従わせる教師ありの方法です。Googleの「Fine-tuned Language Models Are Zero-Shot Learners (FLAN)」で紹介されました。最近では、AlpacaやFLAN V2などの作品が良い例であり、指示調整がさまざまなタスクにどれだけ有益であるかを示しています。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.