Learn more about Search Results ( link - Page 59

- You may be interested
- 「勾配降下法:数学を用いた最適化への山...
- 人工知能による投資アドバイス – メ...
- 「医師がAIを活用して診療を変革する方法」
- 変形者への鎮魂曲?
- エンタープライズデータの力を活用するた...
- 『私をすばやく中心に置いてください:主...
- 「トップAIベースのアートインペインティ...
- 交通部門でのAIのトップ6の使用法
- ETHチューリッヒの研究者が、大規模な言語...
- 「ヒドラで実験を追跡し続けましょう」
- head()とtail()関数の説明と例、コード
- ロジスティック回帰における行列とベクト...
- ChatGPTを使用してバイラルになる方法
- デジタルアート保護の革命:不正なAIウェ...
- 「ExcelでのPython 高度なデータ分析への...

メタAIの研究者たちは、大規模な言語モデルの生成物を批評するための新しいAIモデルを紹介しました
I had trouble accessing your link so I’m going to try to continue without it. 大規模言語モデル(LLM)の能力は、一貫性のある、文脈に即した、意味のあるテキストを生成することがますます複雑になってきました。しかし、これらの進歩にもかかわらず、LLMはしばしば不正確で疑わしい、意味のない結果を提供します。そのため、継続的に評価し改善する技術は、より信頼性の高い言語モデルに向けて役立つでしょう。言語モデルの出力は、LLMの助けを借りて向上させられています。現在の研究の中には、情報検索型の対話タスクに対して自然言語フィードバックを与えるためにユーティリティ関数を訓練するものもあります。一方、他の研究では、指示プロンプトを使用して、さまざまなドメインのモデル生成テキストの多面的評価スコアを作成しています。 元の研究では、数学や推論などの複雑なタスクのモデル出力の生成についてのフィードバックを提供せず、出力応答に対して一般的なフィードバックのみを提供していましたが、最近の研究では、研究者がLLMを自己フィードバックするために指示を調整する方法を紹介しています。この研究では、Meta AI Researchの研究者がShepherdという、モデルによって生成された出力を評価するために特別に最適化された言語モデルを紹介しています。彼らは、さまざまな分野にわたってコメントを提供できる強力な批判モデルを開発することを目指していますが、以前の研究と同様の目標を共有しています。彼らのアプローチでは、事実性、論理的な欠陥、一貫性、整合性などの特定の問題を特定することができ、必要に応じて結果を改善するための修正を提案することもできます。 図1:Stack ExchangeとHuman Annotationからのトレーニングデータの例 具体的には、Shepherdは、深いトピック知識、改善の具体的な提案、広範な判断と推奨事項を含む自然言語のフィードバックを生成することができます。彼らはShepherdを改善し評価するために、2つのユニークなセットの高品質なフィードバックデータセットを開発しました:(1)オンラインフォーラムから収集されたコミュニティフィードバック、より多様な相互作用を捉えるためにキュレーションされたもの、および(2)多くのタスクにわたる生成物を収集した人間による注釈付き入力。図1を参照してください。これらのデータセットの組み合わせでトレーニングされたShepherdは、いくつかの下流タスクでChatGPTモデルを上回る優れたパフォーマンスを発揮しています。コミュニティデータは、人間による注釈付きデータよりも有用で多様です。ただし、コミュニティフィードバックと人間による注釈付きフィードバックデータの効果を詳しく調査した結果、コミュニティフィードバックの方が非公式な傾向があることがわかりました。 これらの微妙な違いにより、Shepherdはさまざまなタスクに対してフィードバックを提供することができ、高品質な人間による注釈付きデータを使用してモデルを微調整することでモデルのパフォーマンスを向上させることがわかりました。彼らはShepherdがAlpaca、SelFee、ChatGPTなどの最先端のベースラインと比較し、モデルベースと人間による評価を行いました。彼らはShepherdの批判が他のモデルの批判よりもよく受け入れられることが多いことを発見しました。たとえば、Alpacaはすべてのモデルの回答を補完する傾向があり、不正確なフィードバックが多く生成されます。SelFeeは、モデルの回答を無視したり、すぐにクエリに回答したりして、間違いを特定する可能性のあるフィードバックを提供しないことがよくあります。…

「Wall-Eのための経路探索アルゴリズムの探求」
以前、グラフ探索アルゴリズムの実装を統一する方法を示しました今回は、それをより視覚的に魅力的にし、パフォーマンスの違いを調べます

「ジェネラティブAIを用いたERPと大規模企業の拡張:フレームワークのステップ1」
編集者の注:ジェイソン・タンは、8月22日から23日にかけて行われるODSC APACのスピーカーです彼の講演「ジェネラティブAIアプリケーションの構築におけるフレームワークと得られた教訓」をぜひチェックしてください!AIのダイナミックな世界において、2022年11月30日のChatGPTの導入は画期的なターニングポイントとなりました...

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…

「Nvidiaが革命的なAIチップを発表し、生成型AIアプリケーションを急速に強化する」
技術が常に限界を押し上げる時代において、Nvidiaは再びその名を刻みました。同社はGH200 Grace Hopper Superchipを発売しました。この先進のAIチップは、生成型AIアプリケーションを強化するために特別に設計されています。この最新のイノベーションは、AIを革新し、パフォーマンス、メモリ、機能を向上させ、AIを新たな高みへと導くことを約束しています。 また読む:中国の強力なNvidia AIチップの隠れた市場 GH200 Grace Hopperの公開:新たなAIの時代 Nvidiaは、世界に先駆けて次世代のAIチップであるGH200 Grace Hopperプラットフォームを紹介しました。このプラットフォームは、複雑な言語モデルから推薦システムや複雑なベクトルデータベースまで、最も複雑な生成型AIのワークロードに対応します。 また読む:NVIDIAがAIスーパーコンピュータDGX GH200を構築 Grace Hopper Superchipの一端 GH200 Grace Hopperプラットフォームの中心には、革新的なGrace Hopper Superchipがあります。この画期的なプロセッサは、世界初のHBM3e(High Bandwidth Memory…

大規模言語モデルとは何ですか?
人工知能の世界は、大規模言語モデル(LLM)の出現によって革命を遂げましたこれらの最先端のモデルは、自然言語処理という基礎に築かれています
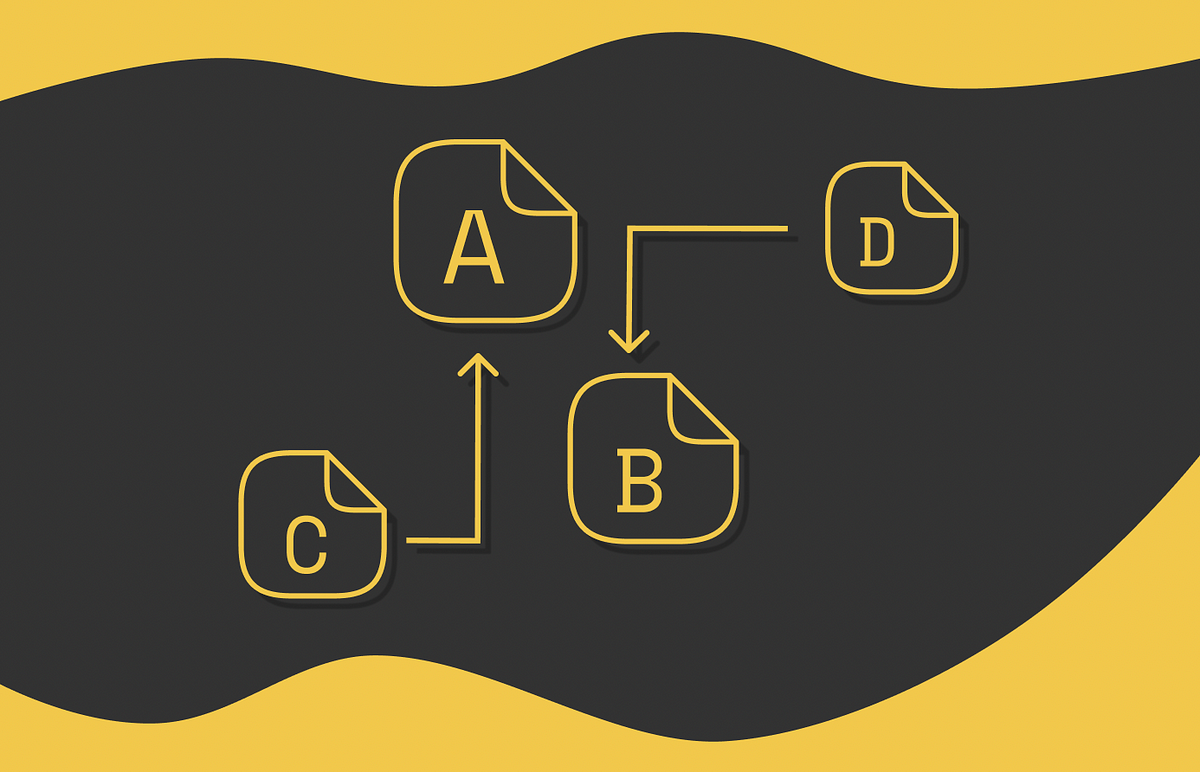
PageRankによる大規模グラフの分析
ランキングは機械学習において重要な問題です与えられたドキュメントの集合に対して、特定の基準に基づいてそれらを特定の順序で並べることが目標ですランキングは情報検索で広く使用されています…
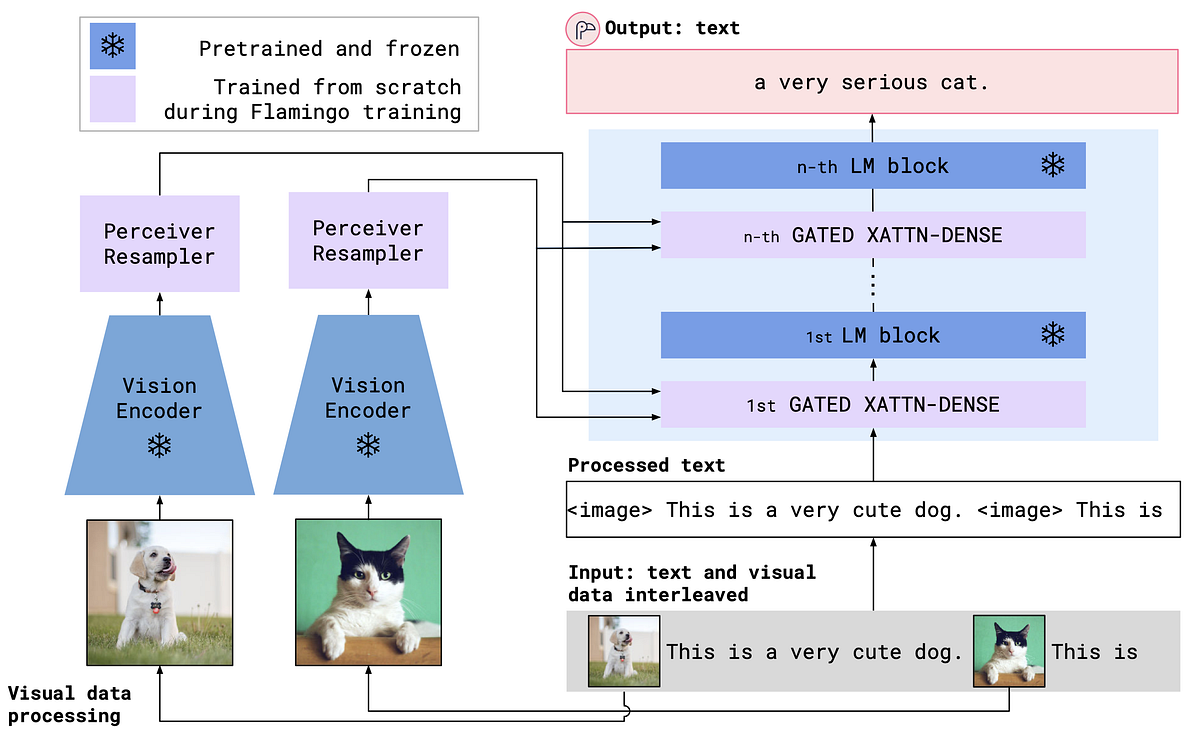
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」
「AIがPowerPointと出会う」
この記事では、2023年5月のSnowflake SummitのStreamlit Hackathonで3位を獲得したオープンソースプロジェクトである「Instant Insight」アプリのバックエンドの仕組みについて詳しく説明しますウェブ...

ベントMLを使用したHugging Faceモデルのデプロイ:DeepFloyd IFのアクション
Hugging Faceは、モデルを簡単にアップロード、共有、展開することができるHubプラットフォームを提供しています。これにより、モデルをゼロからトレーニングするために必要な時間と計算リソースを開発者が節約することができます。ただし、実世界のプロダクション環境やクラウドネイティブの方法でモデルを展開することはまだ課題があります。 ここでBentoMLが登場します。BentoMLは、機械学習モデルのサービングと展開のためのオープンソースプラットフォームです。これは、従来の、事前トレーニング済みの、生成モデルおよび大規模言語モデルを組み込んだ本番向けのAIアプリケーションを構築、出荷、スケーリングするための統一されたフレームワークです。以下は、BentoMLフレームワークを高レベルで使用する方法です: モデルの定義:BentoMLを使用するには、機械学習モデル(または複数のモデル)が必要です。このモデルは、TensorFlowやPyTorchなどの機械学習ライブラリを使用してトレーニングできます。 モデルの保存:トレーニング済みのモデルをBentoMLのローカルモデルストアに保存します。これは、すべてのトレーニング済みモデルをローカルで管理し、サービングにアクセスするために使用されます。 BentoMLサービスの作成:モデルをラップし、サービスのロジックを定義するためにservice.pyファイルを作成します。これは、モデルの推論をスケールで実行するためのランナーを指定し、入力と出力の処理方法を定義するAPIを公開します。 Bentoのビルド:構成YAMLファイルを作成することで、すべてのモデルとサービスをパッケージ化し、コードと依存関係を含む展開可能なアーティファクトであるBentoを作成します。 Bentoの展開:Bentoが準備できたら、Bentoをコンテナ化してDockerイメージを作成し、Kubernetes上で実行することができます。または、Bentoを直接Yataiに展開することもできます。Yataiは、Kubernetes上での機械学習デプロイメントを自動化および実行するためのオープンソースのエンドツーエンドソリューションです。 このブログ投稿では、上記のワークフローに従ってDeepFloyd IFをBentoMLと統合する方法をデモンストレーションします。 目次 DeepFloyd IFの簡単な紹介 環境の準備 BentoMLモデルストアへのモデルのダウンロード BentoMLサービスの開始 Bentoのビルドとサービスの提供 サーバーのテスト 次のステップ DeepFloyd IFの簡単な紹介 DeepFloyd IFは、最先端のオープンソースのテキストから画像へのモデルです。Stable Diffusionのような潜在的な拡散モデルとは異なる運用戦略とアーキテクチャを持っています。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.