Learn more about Search Results Yi - Page 58

- You may be interested
- 神経協調フィルタリングでレコメンデーシ...
- 「接続の最適化:グラフ内の数理最適化」
- 「シームレスM4Tに出会ってください:Meta...
- テクノロジーを通じたアクセシビリティと...
- 「機械学習を使ったイタリアンファンタジ...
- 「データサイエンス30年:データサイエン...
- 大きな言語モデルはどれくらい透明性があ...
- 16/10から22/10の週の重要なLLM論文のトップ
- 「ODSC Europe 2023のトップバーチャルセ...
- MEMSセンサーデータの探索的分析
- 素晴らしいコマンドラインアプリを構築す...
- GPT-3:言語モデルの少数ショット学習?
- ディープラーニングライブラリーの紹介:P...
- 「影に注意:AIとダークパターンが私たち...
- スタートアップ企業向けの20の最高のChatG...

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…
「スパースなデータセットの扱い方に関する包括的ガイド」
はじめに ほとんどがnull値で構成されたデータセットを見たことがありますか?もしそうなら、あなたは一人ではありません。機械学習の中で最も頻繁に起こる問題の一つが、スパースなデータセットです。不適切な調査、欠損値のあるセンサーデータ、または欠損単語のあるテキストなど、いくつかの要因がこれらの存在を引き起こすことがあります。 スパースなデータセットで訓練された機械学習モデルは、比較的低い精度で結果を出力することがあります。これは、機械学習アルゴリズムがすべてのデータが利用可能であるという前提で動作するためです。欠損値がある場合、アルゴリズムは特徴間の相関関係を正しく判断できない可能性があります。欠損値のない大規模なデータセットで訓練すると、モデルの精度が向上します。したがって、スパースなデータセットにはランダムな値ではなく、おおよそ正しい値を埋めるために、特別な注意が必要です。 このガイドでは、スパースなデータセットの定義、理由、および取り扱いの技術について説明します。 学習目標 スパースなデータセットの理解とデータ分析におけるその影響を総合的に把握する。 欠損値を含むスパースなデータセットの処理に関するさまざまな技術、イミュータ、および高度な手法を探求する。 スパースなデータセット内に潜む隠れた洞察を明らかにするために、探索的データ分析(EDA)の重要性を発見する。 実際のデータセットとコード例を組み合わせたPythonを使用したスパースなデータセットの取り扱いに対する実用的なソリューションを実装する。 この記事はData Science Blogathonの一部として公開されました。 スパースなデータセットとは何ですか? 多くの欠損値を含むデータセットは、スパースなデータセットと言われます。欠損値の割合だけでデータセットをスパースと定義する具体的な閾値や固定の割合はありません。ただし、欠損値の割合が高い(通常50%以上)データセットは比較的スパースと見なされることがあります。このような大量の欠損値は、データ分析と機械学習において課題を引き起こす可能性があります。 例 オンライン小売業者からの消費者の購買データを含むデータセットがあると想像してみてください。データセットには2000行(消費者を表す)と10列(製品カテゴリ、購入金額、クライアントのデモグラフィックなどを表す)があるとします。 この例では、データセットのエントリの40%が欠損していると仮定しましょう。つまり、各クライアントごとに10の属性のうち約4つに欠損値があるということです。顧客がこれらの値を入力しなかった可能性があるか、データ収集に問題があったかもしれません。 明確な基準はありませんが、大量の欠損値(40%)があることで、このデータセットを非常にスパースと分類することができます。このような大量の欠損データは、分析とモデリングの信頼性と精度に影響を及ぼす可能性があります。 スパースなデータセットが課題となる理由 多くの欠損値が発生するため、スパースなデータセットはデータ分析とモデリングにいくつかの困難をもたらします。スパースなデータセットを取り扱う際に以下のような要素が課題となります: 洞察の不足:スパースなデータセットでは多くのデータが欠損しているため、モデリングに役立つ意味のある洞察が失われます。 バイアスのある結果:モデルがバイアスのある結果を出力すると、問題が生じます。スパースなデータセットでは、欠損データのためにモデルが特定の特徴カテゴリに依存する場合があります。 モデルの精度への大きな影響:スパースなデータセットは、機械学習モデルの精度に悪影響を与えることがあります。欠損値のある場合、モデルは誤ったパターンを学習する可能性があります。 スパースなデータセットの考慮事項…

「openCypher* はどんなリレーショナルデータベースに対しても使えます」
「Mindfulイニシアチブは、任意のリレーショナルデータベース上でのopenCypherグラフクエリの限定サブセットですこれらのクエリは読み取り専用であり、この段階ではメタグラフクエリはありませんMindfulはクローズドソースです...」
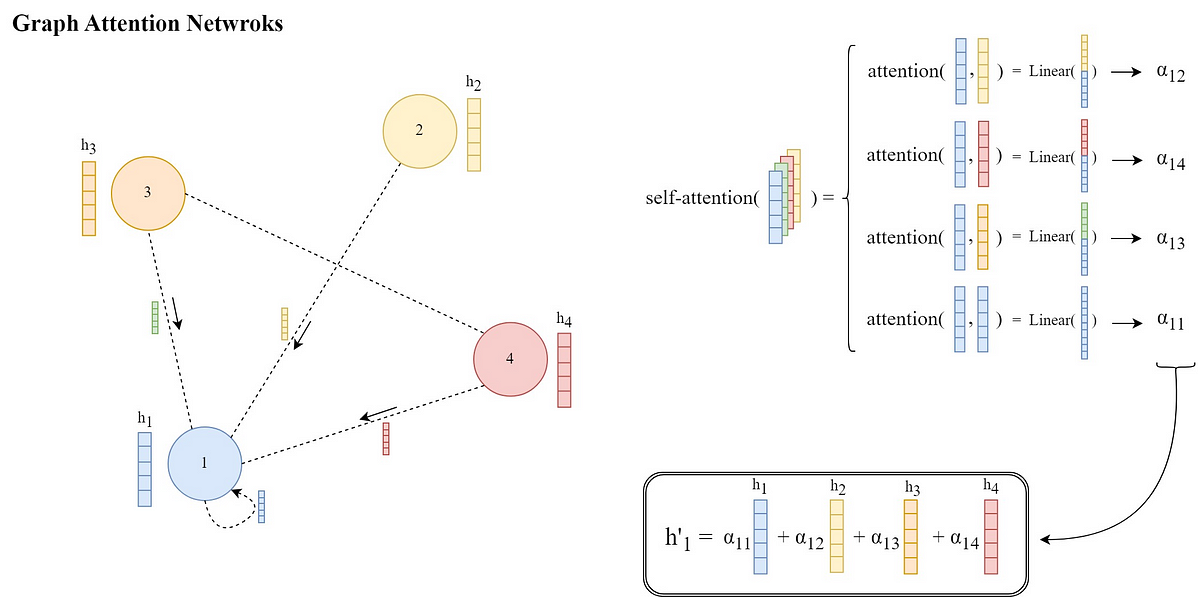
「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
グラフニューラルネットワーク(GNN)は、グラフ構造のデータに作用する強力なニューラルネットワークの一種ですノードのローカルな情報を集約することによって、ノードの表現(埋め込み)を学習します...
「spacy-llmを使用したエレガントなプロンプトのバージョニングとLLMモデルの設定」
「プロンプトの管理とOpenAIのリクエストの失敗への対処は困難な課題となることがあります幸いなことに、spaCyはspacy-llmをリリースしましたこれは強力なツールであり、プロンプトの管理を簡素化し、... 」

「現代の自然言語処理:詳細な概要パート3:BERT」
「トランスフォーマーとGPTについての以前の記事では、NLPのタイムラインと開発の体系的な分析を行ってきましたシーケンス対シーケンスモデリングからドメインがどのように進化したかを見てきました...」

このPythonライブラリ「Imitation」は、PyTorchでの模倣と報酬学習アルゴリズムのオープンソース実装を提供します
明確な報酬関数が定義されたゲームのような領域では、強化学習(RL)は人間のパフォーマンスを上回っています。残念ながら、現実世界の多くのタスクでは報酬関数を手続き的に設計することは困難か不可能です。代わりに、ユーザーフィードバックから報酬関数やポリシーを即座に吸収する必要があります。さらに、ゲームでエージェントが勝つ場合など、報酬関数を定式化できたとしても、RLが効果的に解くためには、得られる目標がよりスパースになる必要がある場合があります。そのため、RLの最先端の結果では、しばしば模倣学習がポリシーの初期化に使用されます。 本記事では、7つの報酬と模倣学習アルゴリズムの優れた、信頼性の高い、モジュラーな実装を提供するライブラリであるimitationについて説明します。重要なことは、彼らのアルゴリズムのインターフェースが一貫しているため、さまざまな方法をトレーニングして比較することが容易になることです。また、PyTorchやStable Baselines3などの最新のバックエンドを使用してimitationを構築しています。それに対して、以前のライブラリは複数のアルゴリズムをサポートしていることが多く、更新されていないことがあり、時代遅れのフレームワークで構築されていました。imitationは実験のベースラインとして多くの重要なアプリケーションを持っています。以前の研究によると、模倣学習アルゴリズムの実装の細かい部分はパフォーマンスに大きな影響を与えることがあります。 imitationは、信頼性のあるベースラインを提供するだけでなく、新しい報酬と模倣学習アルゴリズムの作成プロセスを簡素化することを目指しています。不適切な実験ベースラインを使用すると、誤って肯定的な結果が報告される可能性があります。彼らの技術は慎重にベンチマーク化され、この困難を克服するために以前のソリューションと比較されています。また、彼らは静的型チェックを実施し、コードの98%をカバーするテストを行っています。彼らの実装はモジュラーであり、コードを変更せずに報酬またはポリシーネットワークのアーキテクチャ、RLアルゴリズム、およびオプティマイザを柔軟に変更することができます。 必要なメソッドをサブクラス化してオーバーライドすることで、アルゴリズムを拡張することができます。また、imitationはロールアウトの収集などのルーチンな活動に取り組むための実用的な方法を提供しており、完全に新しいアルゴリズムの作成を促進します。PyTorchやStable Baselines3などの最先端のフレームワークを使用してモデルが構築されているという利点もあります。これに対して、現在の模倣学習や報酬学習アルゴリズムの多くは数年前に公開され、最新の状態に保たれていません。これは、GAILやAIRLのコードベースなど、元の論文と一緒に提供される参照実装に特に当てはまります。 他のアルゴリズムとの模倣比較 しかし、Stable Baselines2などの人気のあるライブラリももはやアクティブに開発されていません。上記の表では、さまざまな指標で代替ライブラリを比較しています。模倣学習と報酬学習アルゴリズムのすべての実装を含めることはできませんが、この表は彼らの知識に基づいて広く使用されている模倣学習ライブラリをすべて含んでいます。彼らは、模倣学習がすべての指標で他の選択肢と同等または優れていることを発見しています。APRelスコアは高く評価されていますが、低次元の特徴から学習する好み比較アルゴリズムに重点を置いています。これは、モデルとは補完的であり、より広範なアルゴリズムを提供し、実装の複雑さを増す代わりにスケーラビリティを重視しています。PyTorchの実装はGitHubで見つけることができます。
「データアナリストがよく遭遇するであろう10の一般的な質問—それに対する回答方法」
データ分析の早い世界では、新しい役割に飛び込む際にデジャブを経験することは珍しくありません同じ質問が繰り返されるパターンに気付いたことがあるかもしれません...

「ODSC APAC 2023の最初のセッションが発表されました」
8月22日から23日にかけてバーチャルで開催されるODSC APACまで、あとわずか数週間です私たちは、カンファレンスセッションの一部をお見せできることをとても楽しみにしていますあなたの経験レベルに関係なく、専門家によるワークショップ、チュートリアル、講演があります以下をチェックしてくださいデータ駆動型のワークフォースの構築...

サムスンのAI研究者が、ニューラルヘアカットを紹介しましたこれは、ビデオや画像から人間の髪の毛のストランドベースのジオメトリを再構築するための新しいAI手法です
サムスンAIセンター、Rockstar Games、FAU Erlangen-Nurnberg、およびCinemersive Labsの研究者たちは、写真やビデオフレームのいくつかのビューから人間の髪を抽出することができる画像ベースのモデリングのための新しい技術を提案しています。髪の再構築は、非常に複雑な幾何学、物理学、反射を持つため、人間の3Dモデリングにおける最も困難なタスクの1つです。それにもかかわらず、ゲーム、遠隔会議、特殊効果を含む多くのアプリケーションにとって重要です。3Dポリラインまたはストランドは、コンピュータグラフィックスで髪を描写する最も一般的な方法です。これらは物理モデリングやリアルなレンダリングに使用できます。現代の画像およびビデオベースの人間再構築システムは、より少ない自由度を持つデータ構造を使用して髪型をシミュレートすることがよくあり、これにより推定が簡単になります。これにはボリューメトリックな表現やセットされたトポロジを持つメッシュなどが含まれます。 その結果、これらの技術はしばしば過度に滑らかな髪のジオメトリを生成し、ヘアスタイルのコア構造を捉えることはできません。光ステージ、制御された照明装置、および同期カメラを備えた密なキャプチャシステムを使用すると、正確なストランドベースの髪の再構築が可能です。最近では、整理されたまたは一貫した照明とカメラキャリブレーションに依存して再構築プロセスを高速化することで、驚くべき結果が得られました。最新の取り組みでは、髪の成長方向に関するフレームごとの手動注釈も使用して、物理的に信頼性のある再構築を行っています。複雑なキャプチャセットアップと労力のかかる前処理の要件により、これらの技術は優れた品質にもかかわらず、多くの実用的なアプリケーションでは実用的ではありません。 図1: 提案された2段階プロセス ヘアスタイルモデリングのためのいくつかの学習ベースのアルゴリズムは、ストランドベースの合成データから発見されたヘアプライオリを使用して取得プロセスを高速化します。しかし、訓練データセットの量はこれらのアプローチの精度の自然な決定要因です。既存のデータセットのほとんどは数百のサンプルしか含んでいないため、人間のヘアスタイルの多様性を適切に扱うためにはより大きなデータセットが必要であり、再構築品質が低下します。この研究では、未制御の照明環境で動作し、さらなるユーザーアノテーションなしで画像またはビデオベースのデータを使用するヘアモデリングの技術を提供しています。彼らはそれを行うための2段階の再構築プロセスを作成しました。最初のステップでの粗いボリューメトリックな髪の復元は完全にデータ駆動型であり、暗黙的なボリューメトリック表現を使用します。第二段階であるファインストランドベースの再構築は、個々の髪のストランドのレベルで作業し、主に小さな合成データセットから発見されたプライオリに依存します。髪と胸(頭部と肩)領域では、最初のステップで暗黙の表面表現を再作成します。 さらに、トレーニング画像または2D方向マップで示される髪の方向と比較することで、異方性投影を使用して髪の成長方向のフィールドを学習することができます。このフィールドは、髪の形状のより正確なフィッティングに役立つことができますが、その主な適用は第二段階の髪のストランドの最適化を制限することです。彼らは、入力フレームから髪の方向マップを生成するために、画像の勾配に基づく従来の方法を使用しています。 ストランドベースの再構築を行うために、第二段階では事前にトレーニングされたプライオリを使用します。彼らは、自己符号化器を使用して合成データからトレーニングされたパラメトリックモデルを使用して個々の髪のストランドとその共同分布またはヘアスタイル全体を表現します。したがって、最適化手順を介して、この段階では前の段階で達成された粗い髪の再構築を学習ベースのプライオリと調和させます。最後に、異方性レンダリングを使用した新しいヘアレンダラを使用して、再構築されたヘアスタイルのリアリズムを高めます。 要約すると、彼らの貢献は次のとおりです: • ストランドプライオリの改善されたトレーニングアプローチ • 頭部および髪の領域における人間の3D再構築方法(ヘアの方向を含む) • ラテント拡散ベースのプライオリを使用したグローバルヘアスタイルモデリング(パラメトリックストランドプライオリと「インターフェース」する) • 従来のレンダリング技術よりもより正確な再構成を実現する、微分可能なソフトヘアラスタリゼーションの手法。 • ストランドレベルでの人間の髪の優れた再構成を実現するために、上記の要素をすべて組み合わせたストランドフィッティングの手法。 彼らの技術の効果を人工および実世界のデータでテストするために、スマートフォンの単眼フィルムと無制限な照明設定で動作する3Dスキャナからの多視点写真を使用しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.