Learn more about Search Results エージェント - Page 58

- You may be interested
- Google AIはWeatherBench 2を紹介します:...
- 「サポートベクトルマシンの優しい入門」
- 「AI時代における学術的誠実性の再考:Cha...
- シカゴ大学と東京大学との量子コンピュー...
- 「データサイエンティストプロフェッショ...
- エンコーダー・デコーダーモデルのための...
- NVIDIAとテルアビブ大学の研究者が、効率...
- 「データの成熟度ピラミッド:レポートか...
- 9/10から15/10までの週のトップ...
- 希望、恐れ、そしてAI
- スタンフォード大学の研究者が、多様な視...
- コンピュータビジョンの進歩:画像認識の...
- Google Pub/SubからBigQueryへの簡単な方法
- このGoogleとUC BerkeleyのAI論文は、NeRF...
- 「データサイエンスの熱狂者にとっての必...

機械学習(ML)の実験トラッキングと管理のためのトップツール(2023年)
機械学習プロジェクトを行う際に、単一のモデルトレーニング実行から良い結果を得ることは一つのことです。機械学習の試行をきちんと整理し、信頼性のある結論を導き出すための方法を持つことは別のことです。 実験トラッキングはこれらの問題に対する解決策を提供します。機械学習における実験トラッキングとは、実施する各実験の関連データを保存することの実践です。 実験トラッキングは、スプレッドシート、GitHub、または社内プラットフォームを使用するなど、さまざまな方法でMLチームによって実装されています。ただし、ML実験の管理とトラッキングに特化したツールを使用することが最も効率的な選択肢です。 以下は、ML実験トラッキングと管理のトップツールです Weight & Biases 重みとバイアスと呼ばれる機械学習フレームワークは、モデルの管理、データセットのバージョン管理、および実験の監視に使用されます。実験トラッキングコンポーネントの主な目的は、データサイエンティストがモデルトレーニングプロセスの各ステップを記録し、モデルを可視化し、試行を比較するのを支援することです。 W&Bは、オンプレミスまたはクラウド上の両方で使用できるツールです。Weights & Biasesは、Keras、PyTorch環境、TensorFlow、Fastai、Scikit-learnなど、さまざまなフレームワークとライブラリの統合をサポートしています。 Comet Comet MLプラットフォームを使用すると、データサイエンティストはモデルのトレーニングから本番まで、実験とモデルの追跡、比較、説明、最適化を行うことができます。実験トラッキングでは、データセット、コードの変更、実験履歴、モデルを記録することができます。 Cometは、チーム、個人、学術機関、企業向けに提供され、誰もが実験を行い、作業を容易にし、結果を素早く可視化することができます。ローカルにインストールするか、ホステッドプラットフォームとして使用することができます。 Sacred + Omniboard Sacredは、オープンソースのプログラムであり、機械学習の研究者は実験を設定、配置、ログ記録、複製することができます。Sacredには優れたユーザーインターフェースがないため、Omniboardなどのダッシュボードツールとリンクすることができます(他のツールとも統合することができます)。しかし、Sacredは他のツールのスケーラビリティに欠け、チームの協力のために設計されていない(別のツールと組み合わせる場合を除く)が、単独の調査には多くの可能性があります。 MLflow MLflowと呼ばれるオープンソースのフレームワークは、機械学習のライフサイクル全体を管理するのに役立ちます。これには実験、モデルの保存、複製、使用が含まれます。Tracking、Model Registry、Projects、Modelsの4つのコンポーネントは、それぞれこれらの要素を代表しています。 MLflow TrackingコンポーネントにはAPIとUIがあり、パラメータ、コードバージョン、メトリック、出力ファイルなどの異なるログメタデータを記録し、後で結果を表示することができます。…

Google AIは、アーキテクチャシミュレータにさまざまな種類の検索アルゴリズムを接続するための、マシンラーニングのためのオープンソースのジム「ArchGym」を紹介しました
コンピュータアーキテクチャの研究は、コンピュータシステムの設計を評価および影響するためのシミュレータやツールを生み出す長い歴史があります。例えば、1990年代後半には、SimpleScalarシミュレータが開発され、科学者が新しいマイクロアーキテクチャの概念をテストすることができました。コンピュータアーキテクチャの研究は、gem5、DRAMSysなどのシミュレーションやツールの普及により大きな進歩を遂げてきました。その後、学術およびビジネスレベルでの共有リソースとインフラの広範な提供のおかげで、この学問は大きく進展しました。 産業界と学界は、厳しい特定ドメインの要件を満たすために、コンピュータアーキテクチャ研究において機械学習(ML)最適化にますます焦点を当てています。これには、コンピュータアーキテクチャのためのML、TinyMLアクセラレーションのためのML、DNNアクセラレータデータパスの最適化、メモリコントローラ、消費電力、セキュリティ、プライバシーなどが含まれます。以前の研究では、設計最適化におけるMLの利点が示されていますが、異なる手法間での公平かつ客観的な比較を妨げる堅牢で再現性のあるベースラインの不足など、まだ採用には障害があります。一貫した開発には、これらの障害に対する理解と共同攻撃が必要です。 ドメイン固有のアーキテクチャの設計空間を探索するために機械学習(ML)を使用することは広く行われています。ただし、設計空間をMLを使用して探索することは困難を伴います: 成長するMLテクニックのライブラリから最適なアルゴリズムを見つけることは困難です。 手法の相対的なパフォーマンスとサンプル効率を評価する明確な方法はありません。 MLを支援したアーキテクチャの設計空間の探索と再現可能なアーティファクトの生成は、異なる手法間での公平で再現性のある客観的な比較のための統一されたフレームワークの欠如により妨げられています。 これらの問題に対処するため、Googleの研究者はArchGymを発表しました。これは、様々な検索手法をビルディングシミュレータと統合する柔軟でオープンソースのジムです。 機械学習によるアーキテクチャの研究:主な課題 機械学習の支援を受けてアーキテクチャを研究する際には、多くの障害が存在します。 コンピュータアーキテクチャの問題(例:DRAMコントローラの最適なソリューションの特定)に対して、最適な機械学習(ML)アルゴリズムやハイパーパラメータ(学習率、ウォームアップステップなど)をシステマチックに決定する方法はありません。設計空間探索(DSE)は、ランダムウォークから強化学習(RL)まで、さまざまなMLおよびヒューリスティック手法を使用することができます。これらの手法は、選択したベースライン以上のパフォーマンスを明らかに向上させますが、これが最適化アルゴリズムの選択された手法または設定ハイパーパラメータによるものかは明確ではありません。 コンピュータアーキテクチャシミュレータは、アーキテクチャの進歩に不可欠ですが、探索フェーズにおいて精度、効率、経済性のバランスを取ることについての懸念があります。使用されるモデルの具体的な仕様によって(例:サイクル精度 vs MLベースのプロキシモデル)、シミュレータは大きく異なるパフォーマンスの推定値を提供することがあります。解析的またはMLベースのプロキシモデルは、低レベルの特徴を無視することができるため、アジャイルですが、通常、予測誤差が高いです。また、商用ライセンスによってシミュレータの使用頻度が制限されることもあります。総じて、これらの制限によるパフォーマンス対サンプル効率のトレードオフは、設計探索に選択される最適化アルゴリズムに影響を与えます。 最後になりますが、MLアルゴリズムの環境は迅速に変化しており、一部のMLアルゴリズムは適切に機能するためにデータに依存しています。また、デザイン空間に関する洞察を得るために、データセットなどの関連アーティファクトでDSEの出力を視覚化することも重要です。 ArchGymによるデザイン ArchGymは、さまざまなMLベースの検索アルゴリズムを一貫して比較および対比するための統一された方法を提供することで、これらの問題を解決します。主要なパーツは次の2つです: 1) ArchGymの設定 2) ArchGymのエージェント 環境は、アーキテクチャのコストモデルと目的のワークロードをカプセル化し、特定のアーキテクチャパラメータのセットに対してワークロードの実行にかかる計算コストを計算するために使用されます。エージェントにはハイパーパラメータと、検索に使用されるMLアルゴリズムを指示するポリシーが含まれています。ハイパーパラメータは、最適化されているモデルにとって重要であり、結果に大きな影響を与えることがあります。一方、ポリシーは、エージェントが時間の経過に伴って目標を最適化するためにどのパラメータを選択するかを指定します。 ArchGymの標準化されたインタフェースは、これらの2つの部分を結びつけ、ArchGymデータセットはすべての探索情報が保存される場所です。インタフェースを構成する3つの主要なシグナルは、ハードウェアの状態、パラメータ、およびメトリックスです。これらのシグナルは、エージェントとその周囲との信頼性のある通信路を確立するために最低限必要なものです。これらのシグナルにより、エージェントはハードウェアの状態を監視し、設定の調整を推奨して(顧客指定の)報酬を最大化するようにします。報酬は、ハードウェアの効率のいくつかの指標に比例します。 研究者はArchGymを使用して、少なくとも1つのハイパーパラメータの組み合わせが他のML手法と同じハードウェアパフォーマンスをもたらすことを経験的に示し、これはさまざまな最適化ターゲットとDSEの状況にわたって成り立ちます。MLアルゴリズムのハイパーパラメータまたはベースラインの任意の選択によって、MLアルゴリズムのファミリーのどれが優れているかについて誤った結論が導かれる可能性があります。彼らは、ランダムウォーク(RW)を含むさまざまな探索アルゴリズムが、適切なハイパーパラメータの調整で最適な報酬を見つけることができることを示しています。ただし、最適なハイパーパラメータの組み合わせを特定するには、多くの作業または運が必要な場合もあることを覚えておいてください。 ArchGymは、MLアーキテクチャDSEのための共通で拡張可能なインターフェースを提供し、オープンソースソフトウェアとして利用できます。ArchGymはまた、コンピュータアーキテクチャの研究問題に対するより堅牢なベースラインを可能にし、さまざまなML技術の公正かつ再現可能な評価を行うことができます。研究者たちは、コンピュータアーキテクチャの分野で研究者が集まり、機械学習を利用して作業を加速し、新しい創造的な設計のアイデアを生み出す場所があれば、大きな進歩となると考えています。

「機械学習支援コンピュータアーキテクチャ設計のためのオープンソースジムナジウム」
Amir Yazdanbakhsh氏、研究科学者およびVijay Janapa Reddi氏、訪問研究者、Google Research コンピュータアーキテクチャの研究は、コンピュータシステムの設計を評価し形成するためのシミュレータとツールの開発の長い歴史があります。たとえば、SimpleScalarシミュレータは1990年代末に導入され、さまざまなマイクロアーキテクチャのアイデアを探索することができました。gem5、DRAMSysなどのコンピュータアーキテクチャのシミュレータとツールは、コンピュータアーキテクチャの研究の進歩において重要な役割を果たしてきました。その後、これらの共有リソースとインフラストラクチャは、産業界と学界の両方に利益をもたらし、研究者がお互いの業績を体系的に積み重ねることを可能にし、この分野での重要な進展をもたらしました。 それにもかかわらず、コンピュータアーキテクチャの研究は進化し続けており、産業界と学界は機械学習(ML)最適化に向かって進んでいます。これには、コンピュータアーキテクチャのためのML、TinyMLアクセラレーションのためのML、DNNアクセラレータデータパス最適化、メモリコントローラ、消費電力、セキュリティ、プライバシーなど、厳格な特定のドメイン要件が含まれます。以前の研究は、設計最適化におけるMLの利点を示していますが、強力で再現性のあるベースラインの欠如は、異なる方法間での公平で客観的な比較を妨げ、展開にいくつかの課題を提起しています。着実な進歩を確保するためには、これらの課題を共同で理解し対処することが重要です。 これらの課題を緩和するために、「ArchGym:機械学習支援アーキテクチャ設計のためのオープンソースジム」というタイトルでISCA 2023で採用された論文において、ArchGymを紹介しました。ArchGymにはさまざまなコンピュータアーキテクチャシミュレータとMLアルゴリズムが含まれています。ArchGymの利用により、十分な数のサンプルがあれば、さまざまなMLアルゴリズムのいずれかが各ターゲット問題の最適なアーキテクチャ設計パラメータセットを見つけることができることが示されています。どの解決策も必ずしも他の解決策よりも優れているわけではありません。これらの結果はまた、与えられたMLアルゴリズムの最適なハイパーパラメータを選択することが、最適なアーキテクチャ設計を見つけるために不可欠であることを示していますが、それらを選択することは容易ではありません。私たちは、複数のコンピュータアーキテクチャシミュレーションとMLアルゴリズムを含むコードとデータセットを公開します。 機械学習支援アーキテクチャ研究の課題 機械学習支援アーキテクチャ研究には、次のようないくつかの課題があります: 特定の機械学習支援コンピュータアーキテクチャ問題(たとえば、DRAMコントローラの最適な解を見つける)に対して、最適なMLアルゴリズムやハイパーパラメータ(学習率、ウォームアップステップなど)を特定するための体系的な方法がありません。ランダムウォークから強化学習(RL)まで、MLとヒューリスティックな手法の幅広い範囲がDSEのために使用される可能性があります。これらの手法は、ベースラインの選択に比べて顕著な性能向上を示していますが、最適化アルゴリズムやハイパーパラメータの選択が改善の要因であるかどうかは明確ではありません。したがって、ML支援アーキテクチャDSEの再現性を確保し、普及を促進するために、体系的なベンチマーキング方法を明示する必要があります。 コンピュータアーキテクチャシミュレータは、アーキテクチャのイノベーションの基盤となっていましたが、アーキテクチャの探索における正確性、速度、コストのトレードオフに対応する必要が出てきています。性能推定の正確性と速度は、サイクル精度とMLベースのプロキシモデルなどの基礎となるモデリングの詳細によって大きく異なります。解析的またはMLベースのプロキシモデルは詳細なレベルの詳細を捨てることによって俊敏性を持ちますが、一般に高い予測エラーを抱えます。また、商業ライセンスにより、シミュレータから収集された実行回数には厳しい制限がある場合があります。全体として、これらの制約は、パフォーマンスとサンプル効率のトレードオフに影響を与え、アーキテクチャ探索のための最適化アルゴリズムの選択に影響を与えるものです。これらの制約の下でさまざまなMLアルゴリズムの効果を体系的に比較する方法を明確にすることは困難です。 最後に、MLアルゴリズムの状況は急速に変化しており、一部のMLアルゴリズムはデータを必要とします。また、DSEの結果をデータセットなどの有意義な成果物に変換することは、設計空間に関する洞察を得るために重要です。この急速に変化するエコシステムでは、探索アルゴリズムのオーバーヘッドをどのように分散するかが重要です。基礎となる探索アルゴリズムには無関係に、探索データをどのように活用するかは明白ではなく、体系的に研究されていません。 ArchGymの設計 ArchGymは、異なるMLベースの探索アルゴリズムを公平に評価するための統一されたフレームワークを提供することによって、これらの課題に対処しています。主なコンポーネントは2つあります:1)ArchGym環境、および2)ArchGymエージェントです。環境は、アーキテクチャのコストモデルをカプセル化しています。これには、レイテンシ、スループット、面積、エネルギーなどが含まれます。アーキテクチャパラメータのセットに基づいて、ワークロードを実行するための計算コストを決定するためのものです。エージェントは、探索に使用されるMLアルゴリズムをカプセル化しています。これにはハイパーパラメータとガイドポリシーが含まれます。ハイパーパラメータは、最適化されるモデルに固有のアルゴリズムにとって内在的なものであり、パフォーマンスに大きな影響を与えることがあります。一方、ポリシーは、エージェントが反復的にパラメータを最適化するためにどのように選択するかを決定します。 特に、ArchGymにはこれらの2つのコンポーネントを接続する標準化されたインターフェースも含まれており、同時に探索データをArchGymデータセットとして保存します。インターフェースは、ハードウェアの状態、ハードウェアのパラメータ、およびメトリックスという3つの主要なシグナルから成り立っています。これらのシグナルを使用して、エージェントはハードウェアの状態を観測し、ハードウェアのパラメータのセットを提案し、(ユーザー定義の)報酬を反復的に最適化します。報酬は、パフォーマンス、エネルギー消費などのハードウェアのパフォーマンスメトリックスの関数です。 ArchGymは、ArchGym環境とArchGymエージェントの2つの主要なコンポーネントで構成されています。ArchGym環境はコストモデルをカプセル化し、エージェントはポリシーとハイパーパラメーターの抽象化です。これらの2つのコンポーネントを接続する標準化されたインターフェースにより、ArchGymは異なるMLベースの探索アルゴリズムを公平に評価する統一されたフレームワークを提供し、探索データをArchGymデータセットとして保存します。 MLアルゴリズムはユーザー定義のターゲット仕様を満たすために同様に好ましいです ArchGymを使用して、さまざまな最適化目標とDSE問題において、他のMLアルゴリズムと同じハードウェアのパフォーマンスをもたらす少なくとも1つのハイパーパラメータのセットが存在することを実証的に示します。MLアルゴリズムまたはそのベースラインの適切に選択されていない(ランダムな選択)ハイパーパラメータは、特定のMLアルゴリズムの特定のファミリーが他のアルゴリズムよりも優れているという誤った結論につながる可能性があります。私たちは、十分なハイパーパラメータの調整により、ランダムウォーク(RW)を含むさまざまな探索アルゴリズムが最良の報酬を特定できることを示します。ただし、適切なハイパーパラメータのセットを見つけるには、徹底的な探索または運も必要な場合があります。 十分な数のサンプルがあれば、一連の探索アルゴリズムにわたって同じパフォーマンスをもたらす少なくとも1つのハイパーパラメータのセットが存在します。ここで、破線は最大の正規化報酬を示しています。Cloud-1、cloud-2、stream、randomはDRAMSys(DRAMサブシステム設計空間探索フレームワーク)の4つの異なるメモリトレースを示しています。 データセットの作成と高精度プロキシモデルのトレーニング ArchGymを使用して統一されたインターフェースを作成することは、アーキテクチャシミュレーションの速度を向上させるためのデータ駆動型のMLベースのプロキシアーキテクチャコストモデルの設計に使用できるデータセットの作成を可能にします。アーキテクチャコストを近似するためのMLモデルを評価するために、ArchGymはDRAMSysからの各ランのデータを記録する能力を活用して、4つのデータセットバリアントを作成します。各バリアントには、2つのカテゴリを作成します:(a)異なるエージェント(ACO、GA、RW、BO)から収集されたデータを表す「多様なデータセット」と、(b)ACOエージェントのみから収集されたデータを示す「ACOのみ」。これらのデータセットはArchGymとともにリリースされます。私たちは、各データセットでランダムフォレスト回帰を使用してプロキシモデルをトレーニングし、DRAMシミュレータの設計のレイテンシを予測することを目的としています。私たちの結果は次のとおりです: データセットのサイズを増やすと、平均正規化二乗平均誤差(RMSE)はわずかに減少します。…

自動化された進化が厳しい課題に取り組む
強化学習は、ラベルのないデータを好みの集合にグループ化することを目指し、人間による評価関数から得られる累積報酬を最大化することを目指しています

13分でハミルトンを使用したメンテナブルでモジュラーなLLMアプリケーションスタックの構築
この投稿では、オープンソースのフレームワークであるHamiltonが、大規模な言語モデル(LLM)アプリケーションスタックのために、モジュール化されて保守性の高いコードの作成をサポートする方法を共有しますHamiltonは素晴らしいです...

「人工知能と自由意志」
人工知能の非凡な能力は今や明白です例えば、チェスをプレイするような特定のことは、AIがどんな人間よりも優れて行えますし、多くのことにおいても、典型的な人間よりも優れた成果を収めることができます...
認知的燃焼の引火:認知アーキテクチャとLLMの融合による次世代コンピュータの構築
「技術はシステムに統合されることで飛躍的な進展を遂げますこの記事では、言語モデルを統合したアーキテクチャの取り組みについて探求し、コンピューティングの次の飛躍を引き起こす可能性を検討します」
認知的な燃焼を引き起こす:認知アーキテクチャとLLMの融合による次世代コンピュータの構築
技術はシステムに統合されることで、ブレークスルーとなりますこの記事では、言語モデルを統合する取り組みについて探求し、次のコンピューティングのブレークスルーを引き起こす可能性のあるアーキテクチャについて説明します

思考の木の探索 AIが探索を通じて理由付けを学ぶ方法の探求
新しいアプローチは、大規模な言語モデルに対する推論ステップの検索として問題解決を表現し、左から右へのデコーディングを超えた戦略的な探索と計画を可能にしますこれにより、数学パズルや創造的な文章作成などの課題におけるパフォーマンスが向上し、LLMの解釈性と適用性が向上します
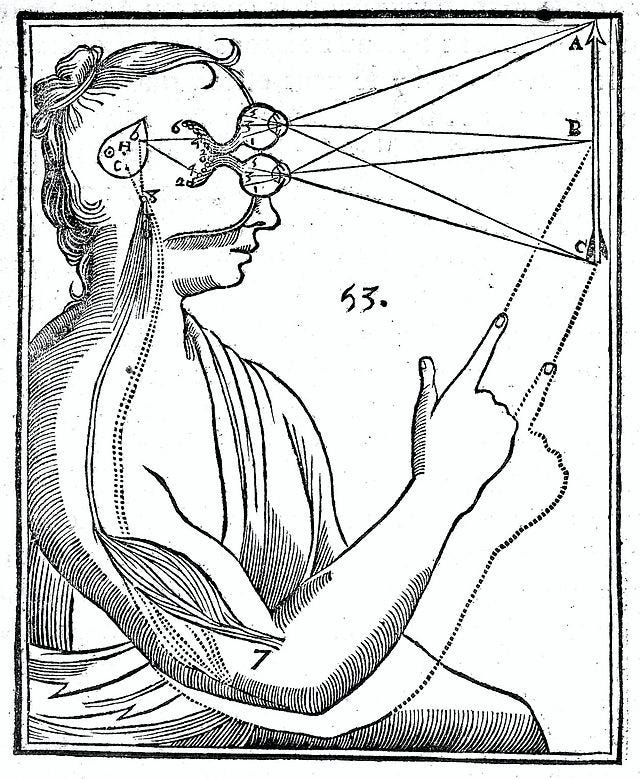
「先天性とは何か、そしてそれは人工知能にとって重要なのか?(パート1)」
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの概念とその応用についての二部構成の詳細な解説は、状況を明確にするのに役立つかもしれません...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.