Learn more about Search Results 6. 結論 - Page 57

- You may be interested
- 効率的にPythonコードを書く方法:初心者...
- ウェブサイトのためにChatGPTに適切なテク...
- 「物理情報を持つニューラルネットワーク...
- 「OpenAI、マイクロソフトの支援を受けてG...
- 「トップ5のクラウドマシンラーニングプラ...
- 公正を実現する:生成モデルにおけるバイ...
- 「ショートGPTと出会おう:コンテンツ作成...
- テーラーは、ERPオペレーションに対する会...
- 「Amazon SageMakerを使用して、Rayベース...
- AIがあなたのように文章を書く方法(クロ...
- 「DALL-E 3とChatGPTを使って、私が一貫し...
- 「Google DeepMindの研究者が『プロンプト...
- 「もし私たちが複雑過ぎるモデルを簡単に...
- 「2024年に機械学習を学ぶ方法(もし最初...
- 「Scikit-Learnクラスを使用したカスタム...
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…

AWSが開発した目的に特化したアクセラレータを使用することで、機械学習ワークロードのエネルギー消費を最大90%削減できます
従来、機械学習(ML)エンジニアは、モデルの学習と展開コストとパフォーマンスのバランスを取ることに焦点を当ててきました最近では、持続可能性(エネルギー効率)が顧客にとって追加の目標となっていますこれは重要なことであり、MLモデルのトレーニングを行い、トレーニングされたモデルを使用して予測(推論)を行うことは、非常にエネルギーを消費するタスクであるためです加えて、さらに...
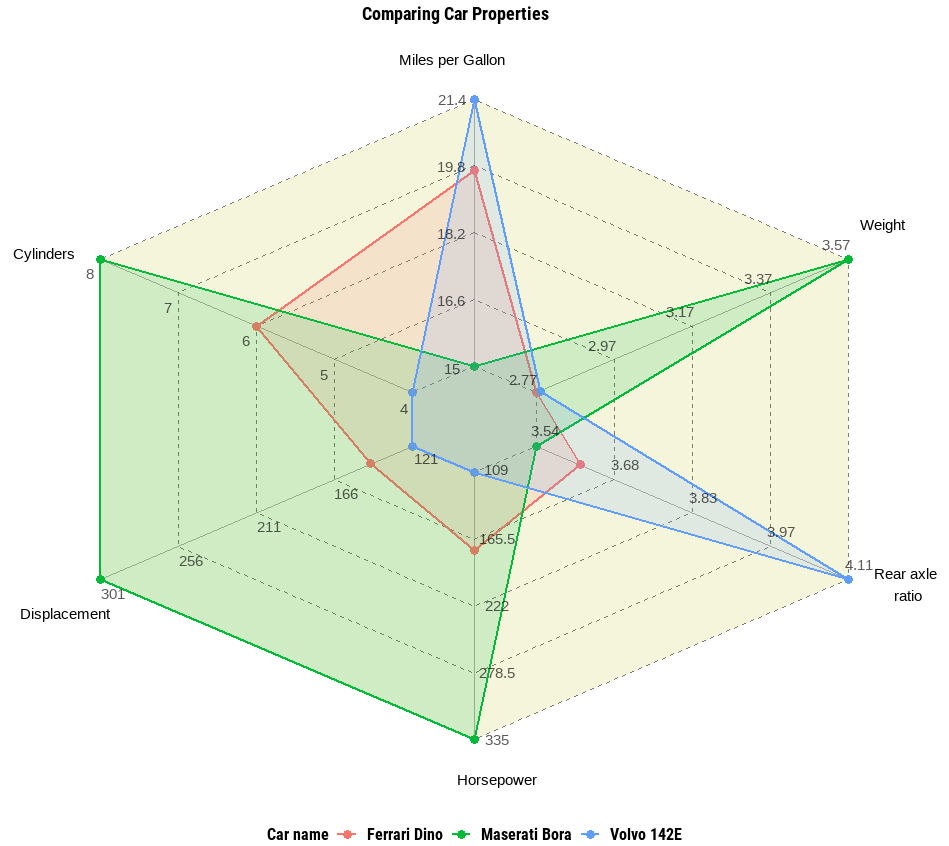
Rのggvancedパッケージを使用したスパイダーチャートと並列チャート
ggplot2パッケージの上に、スパイダーチャートや平行チャートなどの高度な多変数データ可視化を生成するためのパッケージ

あなたのLLMアプリケーションは公開に準備ができていますか?
大規模言語モデル(LLM)は、現代の自然言語処理アプリケーションにおいてパンとバターとなり、固有表現認識モデルなどのより専門的なツールの多様性を多くの面で置き換えています

データサイエンティストのための必須ガイド:探索的データ分析
データを完全に理解するためのベストプラクティス、技術、ツール

UCサンディエゴとクアルコムの研究者たちは「Natural Program」を公開しましたそれは自然言語での厳密な推論チェーンの容易な検証にとって強力なツールであり、AIにおける大きな転換点となります
人工知能の領域で最も驚くべき進歩の一つは、大規模言語モデル(LLM)の開発です。GPT 3.5とGPT 4アーキテクチャに基づくOpenAIが開発した非常に有名なChatGPTは、人間と同じようにコンテンツを生成し、質問に答えることで大いに役立っており、その創造的で正確なコンテンツ生成能力により、ほぼすべての産業における問題解決に取り組むことができます。Chain-of-Thought(CoT)プロンプティングの追加により、GPT 3.5の影響力は向上し、情報処理産業に大きな変革をもたらしました。CoTはLLMを強化し、中間段階でより包括的で詳細な推論プロセスを生成するのに役立ちます。 CoTには多くの利点がありますが、中間推論段階に重点を置くことで、幻覚や複雑化したエラーが発生することがあり、モデルが一貫した正確な推論プロセスを生成するのが困難になることがあります。人間が問題を解決するために故意の推論的論理推論手順に従う方法から着想を得て、LLMが明示的で厳密な演繹的推論を行うことを可能にするために、多くの努力が払われてきました。これらの課題に対処するため、研究者チームは、自然言語に基づく演繹的推論形式であるナチュラルプログラムを導入し、演繹的推論を達成するために自然言語の固有の力を利用する方法を提案しました。 チームは、このアプローチが推論検証プロセスをいくつかの連続したサブプロセスに分解することを示しました。各サブプロセスには、特定のステップに必要な文脈と前提条件のみが提供され、分解により検証プロセスがよりアプローチ可能になります。著者らは、OpenAIのGPT-3.5-turbo(175B)などの公開モデルを使用して、自然言語に基づく演繹的推論形式を実行するための算術および常識のデータセットのトライアルを実行し、その効果を示しました。アウトカムは、彼らの戦略が大規模言語モデルによって生成される推論プロセスの信頼性を高めるのにどのように優れているかを示しています。 ナチュラルプログラム形式により、言語モデルは正確な推論ステップを生成し、後続のステップがより厳密に前のステップに基づいていることを確認します。この構造を使用して、言語モデルはステップバイステップで推論自己検証を実行し、推論段階は各演繹的推論のレベルに検証手順が統合されているため、より厳密で信頼性が高くなります。 チームが述べた主な貢献のいくつかは次のとおりです。 ナチュラルプログラム形式の導入により、チームは、検証に適した厳密な演繹的推論のフレームワークを提案し、コンテキスト内学習により簡単に生成できるようにしました。 提案されたナチュラルプログラム形式で書かれた長大な演繹的推論プロセスは、必要な文脈と前提条件のみをカバーするステップバイステップのサブプロセスを使用して信頼性が高く自己検証できることが示されました。 実験により、フレームワークがLLMによる推論段階とソリューションの正確性、信頼性、解釈性をどのように効果的に向上させるかが示されました。 結論として、このフレームワークは、言語モデルの演繹的推論能力を向上させるために有望です。

オッターに会いましょう:大規模データセット「MIMIC-IT」を活用した最先端のAIモデルであり、知覚と推論のベンチマークにおいて最新の性能を実現しています
マルチファセットモデルは、書かれた言語、写真、動画などの様々なソースからのデータを統合し、さまざまな機能を実行することを目指しています。これらのモデルは、視覚とテキストデータを融合させたコンテンツを理解し、生成することにおいて、かなりの可能性を示しています。 マルチファセットモデルの重要な構成要素は、ナチュラルランゲージの指示に基づいてモデルを微調整する指示チューニングです。これにより、モデルはユーザーの意図をより良く理解し、正確で適切な応答を生成することができます。指示チューニングは、GPT-2やGPT-3のような大規模言語モデル(LLMs)で効果的に使用され、実世界のタスクを達成するための指示に従うことができるようになりました。 マルチモーダルモデルの既存のアプローチは、システムデザインとエンドツーエンドのトレーニング可能なモデルの観点から分類することができます。システムデザインの観点では、ChatGPTのようなディスパッチスケジューラを使用して異なるモデルを接続しますが、トレーニングの柔軟性が欠けているため、コストがかかる可能性があります。エンドツーエンドのトレーニング可能なモデルの観点では、他のモダリティからモデルを統合しますが、トレーニングコストが高く、柔軟性が制限される可能性があります。以前のマルチモーダルモデルにおける指示チューニングのデータセットには、文脈に沿った例が欠けています。最近、シンガポールの研究チームが提案した新しいアプローチは、文脈に沿った指示チューニングを導入し、このギャップを埋めるための文脈を持つデータセットを構築しています。 この研究の主な貢献は以下の通りです。 マルチモーダルモデルにおける指示チューニングのためのMIMIC-ITデータセットの導入。 改良された指示に従う能力と文脈的学習能力を持ったオッターモデルの開発。 より使いやすいOpenFlamingoの最適化実装。 これらの貢献により、研究者には貴重なデータセット、改良されたモデル、そしてより使いやすいフレームワークが提供され、マルチモーダル研究を進めるための貴重な資源となっています。 具体的には、著者らはMIMIC-ITデータセットを導入し、OpenFlamingoの文脈的学習能力を維持しながら、指示理解能力を強化することを目的としています。データセットには、文脈的関係を持つ画像とテキストのペアが含まれており、OpenFlamingoは文脈的例に基づいてクエリされた画像-テキストペアのテキストを生成することを目指しています。MIMIC-ITデータセットは、OpenFlamingoの指示理解力を向上させながら、文脈的学習を維持するために導入されました。これには、画像-指示-回答の三つ組と対応する文脈が含まれます。OpenFlamingoは、画像と文脈的例に基づいてテキストを生成するためのフレームワークです。 トレーニング中、オッターモデルはOpenFlamingoのパラダイムに従い、事前学習済みのエンコーダーを凍結し、特定のモジュールを微調整しています。トレーニングデータは、画像、ユーザー指示、GPTによって生成された回答、および[endofchunk]トークンを含む特定の形式に従います。モデルは、クロスエントロピー損失を使用してトレーニングされます。著者らは、Please view this post in your web browser to complete the quiz.トークンで予測目標を区切ることにより、トレーニングデータを分離しています。 著者らは、OtterをHugging Face Transformersに統合し、研究者がモデルを最小限の努力で利用できるようにしました。彼らは、4×RTX-3090…

中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
大規模言語モデル(LLM)には、GPT-3、PaLM、OPT、BLOOM、GLM-130Bなどが含まれます。これらのモデルは、言語に関してコンピュータが理解し、生成できる可能性の限界を大きく押し上げています。最も基本的な言語アプリケーションの一つである質問応答も、最近のLLMの突破によって大幅に改善されています。既存の研究によると、LLMのクローズドブックQAおよびコンテキストに基づくQAのパフォーマンスは、教師ありモデルのものと同等であり、LLMの記憶容量に対する理解に貢献しています。しかし、LLMにも有限な容量があり、膨大な特別な知識が必要な問題に直面すると、人間の期待には及びません。したがって、最近の試みでは、検索やオンライン検索を含む外部知識を備えたLLMの構築に集中しています。 たとえば、WebGPTはオンラインブラウジング、複雑な問い合わせに対する長い回答、同等に役立つ参照を行うことができます。人気があるにもかかわらず、元のWebGPTアプローチはまだ広く採用されていません。まず、多数の専門家レベルのブラウジング軌跡の注釈、よく書かれた回答、および回答の優先順位のラベリングに依存しており、これらは高価なリソース、多くの時間、および広範なトレーニングが必要です。第二に、システムにウェブブラウザとのやり取り、操作指示(「検索」、「読む」、「引用」など)を与え、オンラインソースから関連する材料を収集させる行動クローニングアプローチ(すなわち、模倣学習)は、基本的なモデルであるGPT-3が人間の専門家に似ている必要があります。 最後に、ウェブサーフィンのマルチターン構造は、ユーザーエクスペリエンスに対して過度に遅いことがあり、WebGPT-13Bでは、500トークンのクエリに対して31秒かかります。本研究の清華大学、北京航空航天大学、Zhipu.AIの研究者たちは、10億パラメータのジェネラル言語モデル(GLM-10B)に基づく、高品質なウェブエンハンスド品質保証システムであるWebGLMを紹介します。図1は、その一例を示しています。このシステムは、効果的で、手頃な価格で、人間の嗜好に敏感であり、最も重要なことに、WebGPTと同等の品質を備えています。システムは、LLM-拡張検索器を含む、いくつかの新しいアプローチや設計を使用して、良好なパフォーマンスを実現しています。精製されたリトリーバーと粗い粒度のウェブ検索を組み合わせた2段階のリトリーバーである。 GPT-3のようなLLMの能力は、適切な参照を自発的に受け入れることです。これは、小型の密集リトリーバーを改良するために洗練される可能性があります。引用に基づく適切なフィルタリングを使用して高品質のデータを提供することで、LLMはWebGPTのように高価な人間の専門家に頼る必要がありません。オンラインQAフォーラムからのユーザーチャムアップシグナルを用いて教えられたスコアラーは、さまざまな回答に対する人間の多数派の嗜好を理解することができます。 図1は、WebGLMがオンラインリソースへのリンクを含むサンプルクエリに対する回答のスナップショットを示しています。 彼らは、適切なデータセットアーキテクチャがWebGPTの専門家ラベリングに比べて高品質のスコアラーを生成できることを示しています。彼らの定量的な欠損テストと詳細な人間評価の結果は、WebGLMシステムがどれだけ効率的かつ効果的かを示しています。特に、WebGLM(10B)は、彼らのチューリングテストでWebGPT(175B)を上回り、同じサイズのWebGPT(13B)よりも優れています。Perplexity.aiの唯一の公開可能なシステムを改善するWebGLMは、この投稿時点で最高の公開可能なウェブエンハンスドQAシステムの一つです。結論として、著者らは次のことを提供しています。・人間の嗜好に基づく、効果的なウェブエンハンスド品質保証システムであるWebGLMを構築しました。WebGPT(175B)と同等のパフォーマンスを発揮し、同じサイズのWebGPT(13B)よりもはるかに優れています。 WebGPTは、LLMsと検索エンジンによって動力を与えられた人気システムであるPerplexity.aiをも凌駕します。•彼らは、WebGLMの現実世界での展開における制限を特定しています。彼らは、ベースラインシステムよりも効率的でコスト効果の高い利点を実現しながら、高い精度を持つWebGLMを可能にするための新しい設計と戦略を提案しています。•彼らは、Web強化QAシステムを評価するための人間の評価メトリックを定式化しています。広範な人間の評価と実験により、WebGLMの強力な能力が示され、システムの将来的な開発についての洞察が生成されました。コードの実装はGitHubで利用可能です。

AIAgentに会ってみましょう:APIキーを必要とせず、GPT4によって動力を得るWebベースのAutomateGPT
AIAgentは、ユーザーが特定のタスクや目標に合わせてカスタマイズされたAIエージェントを作成する力を与える強力なWebベースのアプリケーションです。このアプリケーションは、目標を小さなタスクに分解し、それらを個別に完了することで機能します。このアプリの利点には、複数のAIエージェントを同時に実行できることや、最先端の技術を民主化することが挙げられます。 AIエージェントを使用することで、ユーザーはAIにタスクを指示することができます。たとえば、製品の競合他社を検索し、調査結果のレポートを作成したり、コードスニペットではなく、完全なアプリケーションを作成したりすることができます。 GPT-4の機能とインターネットアクセスを備えたAIAgentは、SEO最適化を伴うブログの自動化、ポッドキャストのトピックの研究などに最適です。APIキーは必要せず、クリーンでシンプルなユーザーインターフェイスを備えているため、AIエージェントとの作業がより簡単になります。 AIAgentは、ファイルの読み取りと書き込みができるため、ユーザーのドキュメントワークフローを効率化することができます。また、構文のハイライトを備えたインラインコードブロックや、サードパーティプラットフォームとのシームレスなコラボレーションなどの機能も備えています。 このツールの現在のバージョンは、ユーザーがGPT-3.5モデルを利用できる無料ティアを提供しています。ただし、GPT-4モデルにアクセスするためには、月額料金が必要です。 使用例 AIAgentは、SEO最適化が最優先事項であるブログコンテンツの調査や執筆を自動化するのに最適です。 ユーザーは、ツールを使用してTwitterの投稿スケジュールを明確に定義し、常にオーディエンスと価値あるコンテンツを共有することができます。 AIAgentは、インターネットアクセスを備えているため、ポッドキャストのトピックの研究に貴重なリソースとなります。さまざまなオンラインソースから重要な情報を取得し、ポッドキャストを充実させることができます。 このツールは、マーケティング分野で、経験豊富な専門家から戦略を学ぶことができます。マーケティングのプロフェッショナルからの記事や専門家の意見にアクセスして分析し、成功したマーケティング技術に関する洞察を得ることができます。 利点 AIAgentは、最新の自然言語処理と理解の最新技術を取り入れたGPT-4モデルによって動作します。 APIキーが不要であるため、シームレスで手間のかからない体験を提供できます。 シンプルでクリーンなユーザーインターフェイス(UI)により、ユーザーがシステムをスムーズに操作できます。 ツールにはインターネットアクセスがあり、オンラインリソースを活用してリアルタイム情報を取得することができます。 個人は、特定のニーズや好みに応じてタスクを完全にカスタマイズおよび変更することができます。 結論 以上より、AIAgentは、様々なタスクにカスタマイズされたAIエージェントを作成することができる強力なWebベースのアプリケーションです。高度なGPT-4モデルとインターネットアクセスにより、ブログの自動化、ポッドキャストのトピックの研究、マーケティング戦略の学習などの利点があります。AIAgentのユーザーフレンドリーなインターフェース、APIキーの不要性、複数のAIエージェントを同時に実行できる能力により、AIツールの分野でChatGPT、AutoGPT、AgentGPTなどの類似プラットフォームとの競合力が高まっています。
医療分野におけるAI-革新的なユースケースとアプリケーション
人工知能(AI)は、数多くの産業を変革する画期的な技術として現れ、医療業界も例外ではありませんAIは、その能力によって医療現場を変革しています...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.