Learn more about Search Results モード - Page 56

- You may be interested
- 『NYU研究者が提案するGPQA 生物学、物理...
- 単一のマシンで複数のCUDAバージョンを管...
- 「HuggingFaceを使用したLlama 2 7B Fine-...
- 「集中データ管理における感度の取り組み」
- 「ディープニューラルネットワークのデプ...
- このAIニュースレターはあなたが必要なも...
- 「Pythonの基礎 構文、データ型、制御構造」
- 「衛星データ、山火事、そしてAI:気候の...
- 「LLMはiPhone上でネイティブに動作できる...
- データ契約の裏側:消費者の責任の目覚め
- 「ODSC West Bootcamp Roadmapのご紹介 &#...
- 「LLMモニタリングと観測性 – 責任...
- 銀行の苦情に関する架空のデータ
- 『データサイエンスをマスターするための5...
- 「Pythonを学ぶための5つの無料大学講座」

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

高速なトレーニングと推論 Habana Gaudi®2 vs Nvidia A100 80GB
この記事では、Habana® Gaudi®2を使用してモデルのトレーニングと推論を高速化し、🤗 Optimum Habanaを使用してより大きなモデルをトレーニングする方法について説明します。さらに、BERTの事前トレーニング、Stable Diffusion推論、およびT5-3Bファインチューニングなど、第一世代のGaudi、Gaudi2、およびNvidia A100 80GBのパフォーマンスの違いを評価するためのいくつかのベンチマークを紹介します。ネタバレ注意 – Gaudi2はトレーニングと推論の両方でNvidia A100 80GBよりも約2倍高速です! Gaudi2は、Habana Labsが設計した第2世代のAIハードウェアアクセラレータです。単一のサーバには、各々96GBのメモリを持つ8つのアクセラレータデバイスが搭載されています(第一世代のGaudiでは32GB、A100 80GBでは80GB)。Habana SDKであるSynapseAIは、第一世代のGaudiとGaudi2の両方に共通しています。つまり、🤗 Optimus Habanaは、🤗 Transformersと🤗 DiffusersライブラリとSynapseAIの間の非常に使いやすいインターフェースを提供し、第一世代のGaudiと同じようにGaudi2でも動作します!ですので、既に第一世代のGaudi用の使用準備が整ったトレーニングや推論のワークフローがある場合は、何も変更することなくGaudi2で試してみることをお勧めします。 Gaudi2へのアクセス方法 IntelとHabanaがGaudi2を利用可能にするための簡単で費用効果の高い方法の1つは、Intel Developer Cloudで利用できるようになっています。そこでGaudi2を使用するためには、以下の手順に従う必要があります: Intel…

オーディオデータセットの完全ガイド
イントロダクション 🤗 Datasetsは、あらゆるドメインのデータセットをダウンロードして準備するためのオープンソースライブラリです。そのミニマリスティックなAPIにより、ユーザーはたった1行のPythonコードでデータセットをダウンロードして準備することができます。効率的な前処理を可能にするための一連の関数も提供されています。利用可能なデータセットの数は類を見ないものであり、ダウンロードできる最も人気のある機械学習データセットがすべて揃っています。 さらに、🤗 Datasetsにはオーディオ特化の機能も備わっており、研究者や実践者にとってもオーディオデータセットの取り扱いを容易にするものです。このブログでは、これらの機能をデモンストレーションし、なぜ🤗 Datasetsがオーディオデータセットのダウンロードと準備のためのベストな場所なのかをご紹介します。 目次 The Hub オーディオデータセットのロード ロードが簡単、処理も簡単 ストリーミングモード:銀の弾丸 The Hubのオーディオデータセットのツアー まとめ The Hub The Hugging Face Hubは、モデル、データセット、デモをホストするプラットフォームであり、すべてがオープンソースで公開されています。さまざまなドメイン、タスク、言語にわたるオーディオデータセットの成長するコレクションがあります。🤗 Datasetsとの緊密な統合により、Hubのすべてのデータセットを1行のコードでダウンロードすることができます。 Hubに移動して、タスクでデータセットをフィルタリングしましょう: Hubの音声認識データセット…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
最近の投稿では、第4世代のIntel Xeon CPU(コードネーム:Sapphire Rapids)とその新しいAdvanced Matrix Extensions(AMX)命令セットについて紹介しました。Amazon EC2上で動作するSapphire Rapidsサーバーのクラスタと、Intel Extension for PyTorchなどのIntelライブラリを組み合わせることで、スケールでの効率的な分散トレーニングを実現し、前世代のXeon(Ice Lake)に比べて8倍の高速化とほぼ線形スケーリングを達成する方法を紹介しました。 この投稿では、推論に焦点を当てます。PyTorchで実装された人気のあるHuggingFaceトランスフォーマーと共に、Ice Lakeサーバーでの短いおよび長いNLPトークンシーケンスのパフォーマンスを測定します。そして、Sapphire RapidsサーバーとHugging Face Optimum Intelの最新バージョンを使用して同じことを行います。Hugging Face Optimum Intelは、Intelプラットフォームのハードウェアアクセラレーションに特化したオープンソースのライブラリです。 さあ、始めましょう! CPUベースの推論を検討すべき理由 CPUまたはGPUで深層学習の推論を実行するかどうかを決定する際には、いくつかの要素を考慮する必要があります。最も重要な要素は、モデルのサイズです。一般に、より大きなモデルはGPUによって提供される追加の計算能力からより多くの利益を得ることができますが、より小さいモデルはCPU上で効率的に実行することができます。…

時間をかけて生存者を助け、機械学習を利用して競争する
2023年2月6日、トルコ南東部でマグニチュード7.7と7.6の地震が発生し、10の都市に影響を及ぼし、2月21日現在で4万2000人以上が死亡し、12万人以上が負傷しました。 地震の数時間後、プログラマーのグループが「アフェタリタ」と呼ばれるアプリケーションを展開するためのDiscordサーバーを立ち上げました。このアプリケーションは、捜索救助チームとボランティアが生存者を見つけて支援するために使用されます。このようなアプリの必要性は、生存者が自分の住所や必要なもの(救助を含む)をテキストのスクリーンショットとしてソーシャルメディアに投稿したことから生じました。一部の生存者は、自分が生きていることと救助を必要としていることを、ツイートで伝え、それにより親族が知ることができました。これらのツイートから情報を抽出する必要があり、私たちはこれらを構造化されたデータに変換するためのさまざまなアプリケーションを開発し、展開するために時間との競争をしました。 Discordサーバーに招待されたとき、私たちは(ボランティアとして)どのように運営し、何をするかについてかなりの混乱がありました。私たちは共同でモデルをトレーニングするために、モデルとデータセットのレジストリが必要でした。私たちはHugging Faceの組織アカウントを開設し、MLベースのアプリケーションを受け取り、情報を処理するためのプルリクエストを通じて共同作業しました。 他のチームのボランティアから、スクリーンショットを投稿し、スクリーンショットから情報を抽出し、それを構造化してデータベースに書き込むアプリケーションの需要があることを聞きました。私たちは、与えられた画像を取得し、まずテキストを抽出し、そのテキストから名前、電話番号、住所を抽出し、これらの情報を権限付与された当局に提供するデータベースに書き込むアプリケーションの開発を開始しました。さまざまなオープンソースのOCRツールを試した後、OCR部分には「easyocr」を使用し、このアプリケーションのインターフェースの構築には「Gradio」を使用しました。OCRからのテキスト出力は、トランスフォーマーベースのファインチューニングされたNERモデルを使用して解析されます。 アプリケーションを共同で改善するために、Hugging Face Spacesにホストし、アプリケーションを維持するためのGPUグラントを受け取りました。Hugging Face HubチームはCIボットをセットアップしてくれたので、プルリクエストがSpaceにどのように影響を与えるかを見ることができ、プルリクエストのレビュー中に役立ちました。 その後、さまざまなチャンネル(Twitter、Discordなど)からラベル付けされたコンテンツが提供されました。これには、助けを求める生存者のツイートの生データと、それらから抽出された住所と個人情報が含まれていました。私たちは、まずはHugging Face Hub上のオープンソースのNLIモデルと、クローズドソースの生成モデルエンドポイントを使用したフューショットの実験から始めました。私たちは、xlm-roberta-large-xnliとconvbert-base-turkish-mc4-cased-allnli_trというモデルを試しました。NLIモデルは特に役立ちました。候補ラベルを使用して直接推論でき、データのドリフトが発生した際にラベルを変更できるため、生成モデルはバックエンドへの応答時にラベルを作り上げる可能性があり、不一致を引き起こす可能性がありました。最初はラベル付けされたデータがなかったので、何でも動くでしょう。 最終的に、私たちは独自のモデルを微調整することにしました。1つのGPUでBERTのテキスト分類ヘッドを微調整するのに約3分かかります。このモデルをトレーニングするためのデータセットを開発するためのラベリングの取り組みがありました。モデルカードのメタデータに実験結果を記録し、後でどのモデルを展開するかを追跡するためのリーダーボードを作成しました。ベースモデルとして、bert-base-turkish-uncasedとbert-base-turkish-128k-casedを試しましたが、bert-base-turkish-casedよりも優れたパフォーマンスを発揮することがわかりました。リーダーボードはこちらでご覧いただけます。 課題とデータクラスの不均衡を考慮し、偽陰性を排除することに焦点を当て、すべてのモデルの再現率とF1スコアをベンチマークするためのスペースを作成しました。これには、関連するモデルリポジトリにメタデータタグdeprem-clf-v1を追加し、このタグを使用して記録されたF1スコアと再現率を自動的に取得し、モデルをランク付けしました。漏れを防ぐために別のベンチマークセットを用意し、モデルを一貫してベンチマークしました。また、各モデルをベンチマークし、展開用の各ラベルに対して最適な閾値を特定しました。 NERモデルを評価するために、データラベラーが改善された意図データセットを提供するために取り組んでいるため、クラウドソーシングの取り組みとしてNERモデルを評価するためのラベリングインターフェースを設定しました。このインターフェースでは、ArgillaとGradioを使用して、ツイートを入力し、出力を正しい/正しくない/曖昧などのフラグで示すことができます。 後で、データセットは重複を排除してさらなる実験のベンチマークに使用されました。 機械学習の別のチームは、特定のニーズを得るために生成モデル(ゲート付きAPIの背後)と連携し、テキストとして自由なテキストを使用し、各投稿に追加のコンテキストとしてテキストを渡すためにAPIエンドポイントを別のAPIとしてラップし、クラウドに展開しました。少数のショットのプロンプティングをLLMsと組み合わせて使用することで、急速に変化するデータのドリフトの存在下で細かいニーズに対応するのに役立ちます。調整する必要があるのはプロンプトだけであり、ラベル付けされたデータは必要ありません。 これらのモデルは現在、生存者にニーズを伝えるためにボランティアや救助チームがヒートマップ上のポイントを作成するために本番環境で使用されています。 Hugging Face Hubとエコシステムがなかったら、私たちはこのように迅速に協力し、プロトタイプを作成し、展開することはできませんでした。以下は住所認識および意図分類モデルのためのMLOpsパイプラインです。 このアプリケーションとその個々のコンポーネントには何十人ものボランティアがおり、短期間でこれらを提供するために寝ずに働きました。 リモートセンシングアプリケーション…
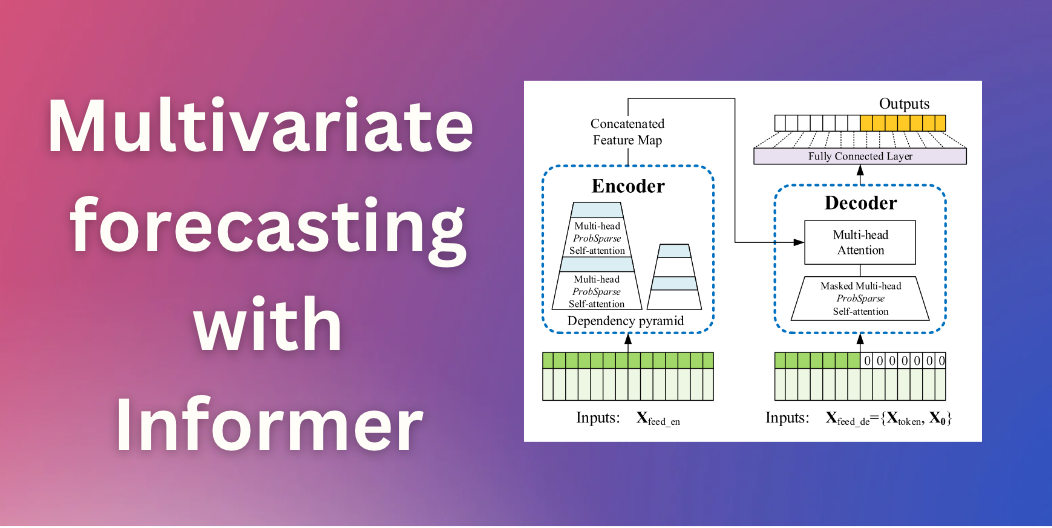
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

テキストからビデオへのモデルの深掘り
ModelScopeで生成されたビデオサンプルです。 テキストからビデオへの変換は、生成モデルの驚くべき進歩の長いリストの中で次に来るものです。その名前の通り、テキストからビデオへの変換は、時間的にも空間的にも一貫性のある画像のシーケンスをテキストの説明から生成する、比較的新しいコンピュータビジョンのタスクです。このタスクは、テキストから画像への変換と非常によく似ているように思えるかもしれませんが、実際にははるかに難しいものです。これらのモデルはどのように動作し、テキストから画像のモデルとはどのように異なり、どのようなパフォーマンスが期待できるのでしょうか? このブログ記事では、テキストからビデオモデルの過去、現在、そして未来について論じます。まず、テキストからビデオとテキストから画像のタスクの違いを見直し、条件付きと非条件付きのビデオ生成の独特の課題について話し合います。さらに、テキストからビデオモデルの最新の開発について取り上げ、これらの方法がどのように機能し、どのような能力があるのかを探ります。最後に、Hugging Faceで取り組んでいるこれらのモデルの統合と使用を容易にするための取り組みや、Hugging Face Hub内外でのクールなデモやリソースについて話します。 さまざまなテキストの説明を入力として生成されたビデオの例、Make-a-Videoより。 テキストからビデオ対テキストから画像 最近の開発が非常に多岐にわたるため、テキストから画像の生成モデルの現在の状況を把握することは困難かもしれません。まずは簡単に振り返りましょう。 わずか2年前、最初のオープンボキャブラリ、高品質なテキストから画像の生成モデルが登場しました。VQGAN-CLIP、XMC-GAN、GauGAN2などの最初のテキストから画像のモデルは、すべてGANアーキテクチャを採用していました。これらに続いて、2021年初めにOpenAIの非常に人気のあるトランスフォーマーベースのDALL-E、2022年4月のDALL-E 2、Stable DiffusionとImagenによって牽引された新しい拡散モデルの新たな波が続きました。Stable Diffusionの大成功により、DreamStudioやRunwayML GEN-1などの多くの製品化された拡散モデルや、Midjourneyなどの既存製品との統合が実現しました。 テキストから画像生成における拡散モデルの印象的な機能にもかかわらず、拡散および非拡散ベースのテキストからビデオモデルは、生成能力においてはるかに制約があります。テキストからビデオは通常、非常に短いクリップで訓練されるため、長いビデオを生成するためには計算コストの高いスライディングウィンドウアプローチが必要です。そのため、これらのモデルは展開とスケーリングが困難であり、文脈と長さに制約があります。 テキストからビデオのタスクは、さまざまな面で独自の課題に直面しています。これらの主な課題のいくつかには以下があります: 計算上の課題:フレーム間の空間的および時間的な一貫性を確保することは、長期的な依存関係を伴い、高い計算コストを伴います。そのため、このようなモデルを訓練することは、ほとんどの研究者にとって手の届かないものです。 高品質なデータセットの不足:テキストからビデオの生成のためのマルチモーダルなデータセットは希少で、しばしばスパースに注釈が付けられているため、複雑な動きのセマンティクスを学ぶのが難しいです。 ビデオのキャプションに関する曖昧さ:モデルが学習しやすいようにビデオを記述する方法は未解決の問題です。完全なビデオの説明を提供するためには、複数の短いテキストプロンプトが必要です。生成されたビデオは、時間の経過に沿って何が起こるかを物語る一連のプロンプトやストーリーに基づいて条件付ける必要があります。 次のセクションでは、テキストからビデオへの進展のタイムラインと、これらの課題に対処するために提案されたさまざまな手法について別々に議論します。高レベルでは、テキストからビデオの作業では以下のいずれかを提案しています: 学習しやすいより高品質なデータセットの作成。 テキストとビデオのペアデータなしでこのようなモデルを訓練する方法。 より計算効率の良い方法で長く、高解像度のビデオを生成する方法。 テキストからビデオを生成する方法…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.