Learn more about Search Results 6. 結論 - Page 55

- You may be interested
- 20/11〜26/11の間におけるコン...
- AWS Marketplace上のHugging Faceプラット...
- LangChainによるAIの変革:テキストデータ...
- 大規模言語モデルにおける文脈の長さの拡張
- 学校でのChatGPTの影響となぜ禁止されつつ...
- 「大規模言語モデルによってプログラミン...
- 「5つの最高のオープンソースLLM」
- ネットワークの強化:異常検出のためのML...
- 「ヘイスタックの中の針を見つける –...
- 「Andrej Karpathy LLM Paper Reading Lis...
- NVIDIA Studio LineupにRTX搭載のMicrosof...
- バイナリおよびマルチクラスのターゲット...
- 「AIの問題を定義する方法」
- 「悪魔に叫べ カプコンの『デビル メイ ク...
- 「Amazon Rekognition Custom LabelsとAWS...

ニューラルネットワークにおける活性化関数の種類
ニューラルネットワークの活性化関数は、ディープラーニングの重要な部分であり、トレーニングモデルの精度と効率を決定します。大規模なニューラルネットワークの作成や分割に使用されるモデルとディープラーニングモデルの出力を決定します。活性化関数は、関連するデータに焦点を当てながら、他のデータを破棄するため、ニューラルネットワークにとって貴重なツールです。他の関数と同様に、活性化関数(転送関数)は入力を受け取り、その入力に比例する出力を返します。ニューラルネットワークのノードの活性化関数は、特定の入力または入力グループに対するノードの出力を指定します。 意図した結果を達成するために、どのニューロンを活性化または非活性化するか効果的に選択します。入力も非線形に変換され、高度なニューラルネットワークでのパフォーマンスが向上します。1から-1までの情報は、活性化関数で出力を正規化することができます。ニューラルネットワークは通常、何百万ものデータポイントでトレーニングされるため、活性化関数が高速であり、結果を計算するために必要な時間を最小限に抑えることが重要です。 さて、ニューラルネットワークの構造を確認し、ニューラルネットワークアーキテクチャがどのように組み立てられ、ニューラルネットワークにどの要素が存在するかを見てみましょう。 人工ニューラルネットワークは、多くのリンクされた個々のニューロンを含んでいます。各ニューロンの活性化関数、バイアス、および重みが指定されます。 入力層 – ドメインの生データが入力層に送られます。この層は計算が行われる最も低いレベルです。これらのノードが行う唯一のことは、データを次の隠れ層に中継することです。 隠れ層 – 入力層から特徴を受け取った後、隠れ層はさまざまな計算を行い、結果を出力層に渡します。レイヤー2のノードは表示されず、基礎となるニューラルネットワークの抽象化レイヤーを提供します。 出力層 – ネットワークの隠れ層の出力がこの層でまとめられ、ネットワークの最終的な値が提供されます。 活性化関数の重要性 線形方程式は1次の多項式であるため、活性化関数を持たないニューラルネットワークは単なる線形回帰モデルです。解くのは簡単ですが、複雑な問題や高次の多項式に対処する能力は制限されています。 活性化関数は、ニューラルネットワークに非線形性を提供するために使用されます。活性化関数の計算は、順伝播の各層で追加のステップを行いますが、その手間は十分に報われます。 活性化関数がない場合、各ニューロンは重みとバイアスを使用して入力に対する線形変換を行います。2つの線形関数の合成は、それ自体が線形関数です。したがって、ニューラルネットワークの隠れ層の総数はその動作に影響を与えません。 活性化関数の種類 ニューラルネットワークは、異なる活性化関数が使用される3つの主要な部分に分類されます。 バイナリステップ関数 線形関数 非線形活性化関数 バイナリステップニューラルネットワークの活性化関数 バイナリステップ関数…

何が合成データとは?その種類、機械学習とプライバシーにおける利用例及び応用について
データサイエンスと機械学習の分野は、毎日成長しています。新しいモデルやアルゴリズムが提案されるにつれて、これらの新しいアルゴリズムとモデルには、トレーニングやテストに膨大なデータが必要となります。ディープラーニングモデルは今日では非常に人気があり、これらのモデルもデータを大量に必要とします。異なる問題文脈の大量のデータを取得することは、非常に面倒で時間がかかり、コストがかかります。データは現実のシナリオから収集されるため、セキュリティの責任とプライバシーの懸念が高まります。データの大部分はプライバシー法や規制によって保護されており、組織間や場合によっては同一組織の異なる部門間でのデータ共有や移動を妨げ、実験や製品のテストを遅らせる原因となります。それでは、この問題をどのように解決できるでしょうか?どのようにして、誰かのプライバシーに関する懸念を引き起こすことなく、データをよりアクセスしやすくオープンにすることができるのでしょうか? この問題の解決策は、合成データ (Synthetic data)と呼ばれるものです。 では、合成データとは何でしょうか? 合成データとは、人工的またはアルゴリズム的に生成され、実際のデータの基本的な構造と特性に近いものです。合成データが良ければ、実際のデータと区別がつかないほどです。 合成データの種類は何種類あるのでしょうか? この質問の答えは非常にオープンエンドで、データは多様な形をとることができますが、主に以下のようなものがあります。 テキストデータ 音声またはビジュアルデータ (たとえば画像、動画、音声) 表形式のデータ 機械学習における合成データの利用例 ここでは、上記の3つのタイプの合成データの利用例について説明します。 NLPモデルのトレーニングに合成テキストデータを使用する 合成データは、自然言語処理の分野で応用されています。たとえば、AmazonのAlexa AIチームは、既存の顧客インタラクションデータが存在しない場合や十分でない場合に、NLUシステム (自然言語理解) のトレーニングセットを完成させるために合成データを使用しています。 ビジョンアルゴリズムのトレーニングに合成データを使用する ここでは、広く使用されているユースケースについて説明します。たとえば、画像内の顔の数を検出または数えるアルゴリズムを開発したい場合を考えてみましょう。ジェネレーティブネットワーク (GAN) またはその他の生成ネットワークを使用して、実際には存在しない現実的な人間の顔、つまり顔を生成してモデルをトレーニングすることができます。また、誰かのプライバシーを侵害することなく、これらのアルゴリズムから必要なだけデータを生成することができます。しかし、実際のデータには個人の顔が含まれているため、プライバシーポリシーによってそのデータを使用することが制限されています。 別のユースケースとして、シミュレートされた環境で強化学習を行うことが考えられます。たとえば、オブジェクトをつかんで箱に入れるために設計されたロボットアームをテストしたい場合、この目的のために強化学習アルゴリズムが設計されます。強化学習アルゴリズムが学習する方法は、実験を行うことです。実際のシナリオで実験を行うことは非常にコストがかかり、時間がかかり、異なる実験を行うことが制限されます。しかし、シミュレートされた環境で実験を行う場合、実験を設定するのは比較的安価で、ロボットアームのプロトタイプが必要なくなります。…

Pythonを使用して北極の氷の傾向を分析する
Pythonは、データサイエンスのための卓越したプログラミング言語として、計測データを収集・クリーニング・解釈することが容易になりますPythonを使って、予測をバックテストし、モデルを検証することができますそして...
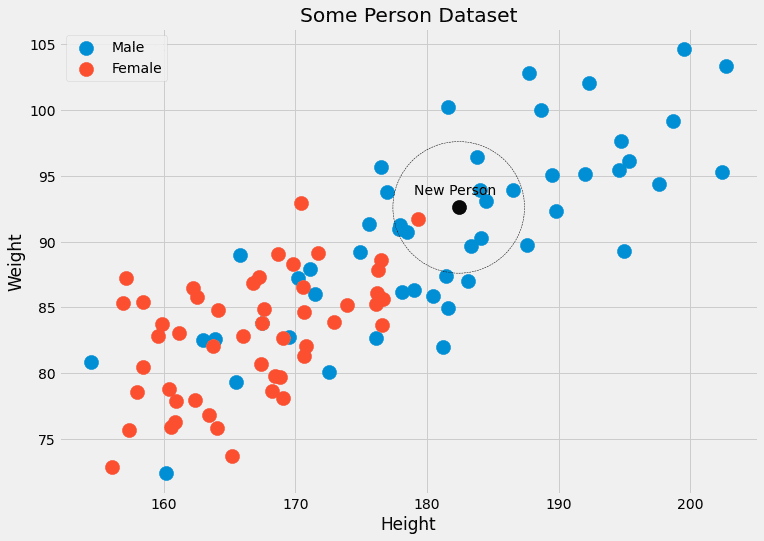
理論から実践へ:k最近傍法分類器の構築
k-最近傍法分類器は、新しいデータポイントを、k個の最も近い隣人の中で最も一般的なクラスに割り当てる機械学習アルゴリズムですこのチュートリアルでは、Pythonでこの分類器を構築および適用する基本的な手順を学びます

PyTorchを使用した効率的な画像セグメンテーション:パート3
この4部シリーズでは、PyTorchを使用して深層学習技術を使い、画像セグメンテーションをスクラッチからステップバイステップで実装しますこのパートでは、CNNベースラインモデルを最適化することに焦点を当てます
PyTorchを使用した効率的な画像セグメンテーション:Part 4
この4部構成のシリーズでは、PyTorchを使用した深層学習技術を使って、画像セグメンテーションをゼロからステップバイステップで実装しますこのパートでは、Vision Transformerをベースとしたモデルの実装に焦点を当てます
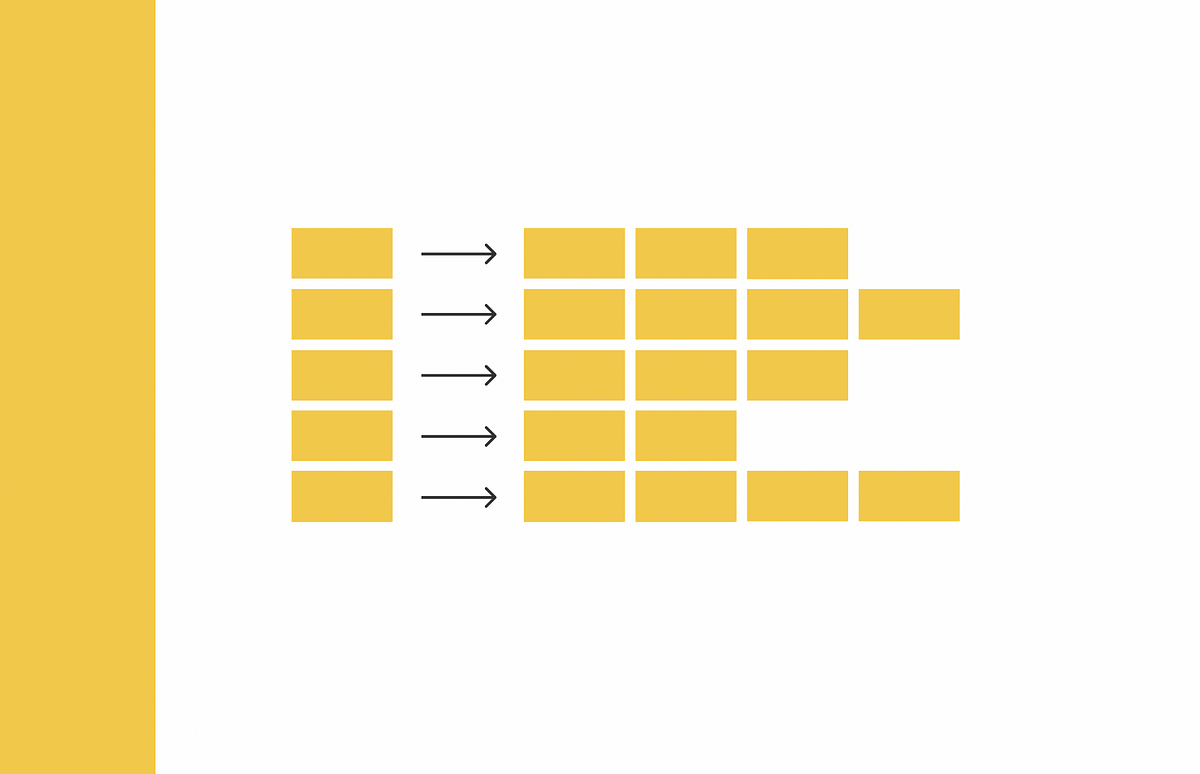
類似検索、パート5:局所性鋭敏ハッシュ(LSH)
類似度検索とは、クエリが与えられたときに、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目的とした問題ですデータサイエンスにおいては、類似度検索はしばしば自然言語処理において現れます...

7つの方法でChatGPTがあなたのコーディングをより良く、より速くします
プロジェクトの計画から本番用のコードの生成まで、ChatGPTは開発プロセス全体にわたって頼れるパートナーであり、一歩一歩有益なアシストを提供します
特徴量が多すぎる?主成分分析を見てみましょう
次元の呪いは、機械学習における主要な問題の1つです特徴量の数が増えると、モデルの複雑さも増しますさらに、十分なトレーニングデータがない場合、それは...

Amazon SageMaker Data WranglerのSnowflakeへの直接接続でビジネスインサイトまでの時間を短縮してください
Amazon SageMaker Data Wranglerは、1つのビジュアルインターフェイスで、コードを書くことなく機械学習(ML)ワークフローでデータの選択とクリーニング、特徴量エンジニアリングの実行に必要な時間を週から分単位に短縮することができ、データの準備を自動化することができますSageMaker Data Wranglerは、人気のあるSnowflakeをサポートしています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.