Learn more about Search Results Yi - Page 54

- You may be interested
- NLPの探求- NLPのキックスタート(ステッ...
- LinkedInのフィード進化:より詳細かつパ...
- 「SQLにおけるSUBSTRING関数とは何ですか...
- アルゴリズムの効率をマスターする
- 「AIがキーストロークを聞く:新たなデー...
- チャレンジを受け入れました:アニメータ...
- Hugging Faceは、Microsoftとの協力により...
- 「プロンプトチューニングとは何ですか?」
- 「データは言語モデルの基盤です」
- AIアドバイザーと計画ツール:金融、物流...
- NVIDIAのGPUはAWS上でOmniverse Isaac Sim...
- 「エンコーディングからエンベディングへ」
- 「なぜマイクロソフトのOrca-2 AIモデルは...
- 神経協調フィルタリングでレコメンデーシ...
- バードは論理と推論力においてますます上...
「あなたのLLMアプリを守る必読です!」
「大規模言語モデルアプリケーションのOWASPトップ10プロジェクトは、開発者、デザイナー、アーキテクト、マネージャー、そして組織に、展開および...」
「Hugging Face Transformersライブラリを解剖する」
これは、実践的に大規模言語モデル(LLM)を使用するシリーズの3番目の記事ですここでは、Hugging Face Transformersライブラリについて初心者向けのガイドを提供しますこのライブラリは、簡単で...
「データフレームのマージに使用される3つのPandas関数」
データ作業では、データソースから複数のデータセットを持ったり、データ分析の結果として持ったりすることが一般的ですデータセットのマージは、Pandasパッケージの利用可能な関数で可能ですIn...
『過学習から卓越へ:正則化の力を活用する』
機械学習に関して言えば、私たちの目的は、訓練されていないデータに対して最も正確な予測を行うMLモデルを見つけることですそのために、訓練データでMLモデルを訓練し、どのように機能するかを確認します
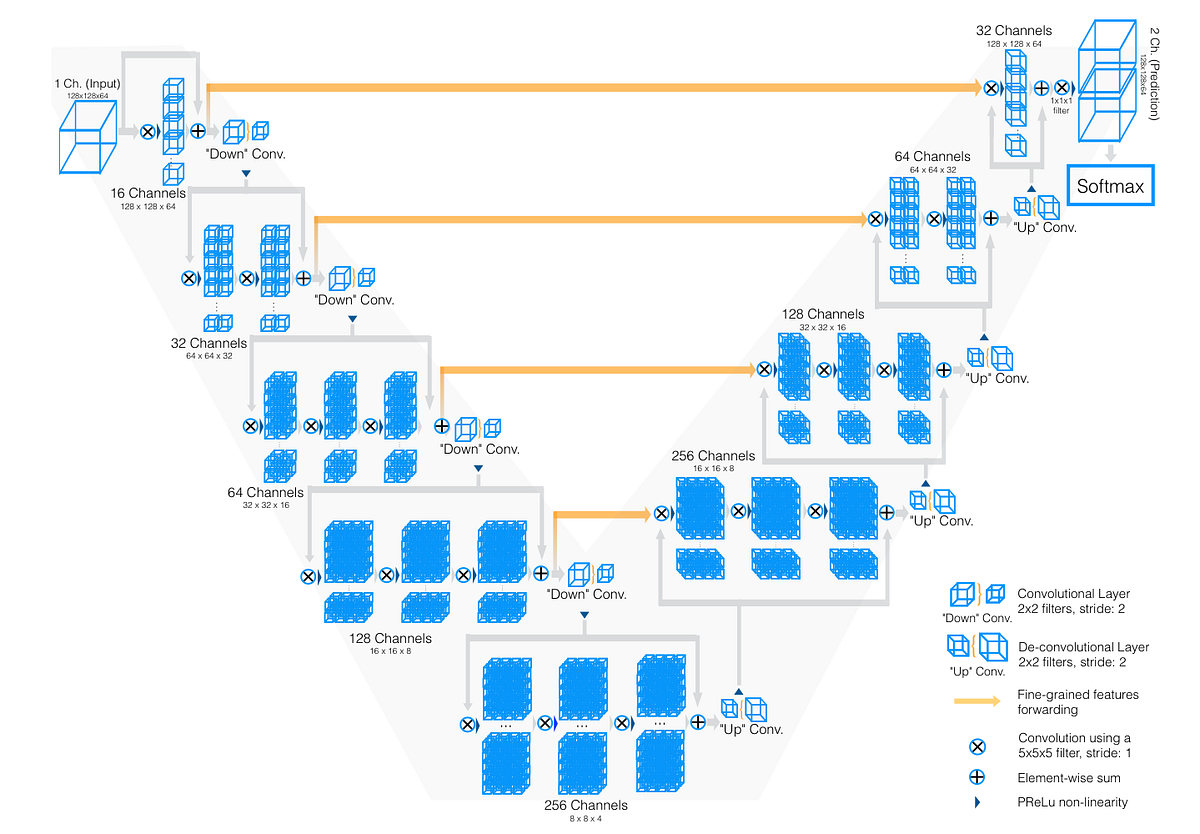
「V-Net、イメージセグメンテーションにおけるU-Netの兄貴」
イメージセグメンテーションと医療画像のためのV-Net、U-Netの兄弟分についてのレビューと紹介データサイエンティストや医療関係者に最適です
データ駆動型のディスパッチ
「現代のスピーディーな世界において、データに基づく意思決定がディスパッチ応答システムにおいて不可欠となっていますディスパッチャーは、通話を聞いて優先順位を付けるという一種のトリアージを行います...」

『私をすばやく中心に置いてください:主題拡散は、オープンドメインのパーソナライズされたテキストから画像生成を実現できるAIモデルです』
テキストから画像へのモデルは、過去1年間のAIの議論の中心でした。この分野の進歩は非常に迅速に起こり、その結果、印象的なテキストから画像へのモデルが存在します。生成型AIは新しいフェーズに入っています。 拡散モデルはこの進歩の主要な貢献者でした。これらのモデルは強力な生成モデルの一部として登場しました。これらのモデルは、望ましい画像にゆっくりとノイズを除去することによって高品質の画像を生成するよう設計されています。拡散モデルは隠れたデータパターンを捉え、多様で現実的なサンプルを生成することができます。 拡散ベースの生成モデルの急速な進歩は、テキストから画像の生成方法を革新しました。思いつくものは何でも画像として要求でき、モデルは非常に正確にそれを生成することができます。さらに進歩が進むにつれて、AIによって生成された画像がどれであるかを理解するのが難しくなってきています。 しかし、ここには問題があります。これらのモデルは画像を生成するためにテキストの説明にのみ頼っています。あなたは見たいものを「説明」することしかできません。さらに、ほとんどの場合、それを個人化することは容易ではありません。 自分の家のインテリアデザインを行い、建築家と協力すると想像してみてください。建築家は以前のクライアントのために作成したデザインしか提供できず、デザインの一部を個人化しようとしても無視され、別の使用済みのスタイルが提供されるだけです。とても満足できるとは言えませんね。これが個人化を求める場合、テキストから画像へのモデルで得られる体験になるかもしれません。 幸いなことに、これらの制限を克服する試みが行われています。研究者は、テキストの説明と参照画像を統合してより個人化された画像生成を実現する方法を探求しました。一部の方法では、特定の参照画像での微調整が必要ですが、他の方法では個人化したデータセットでベースモデルを再学習することにより、忠実度と汎化性能に潜在的な欠点が生じます。さらに、既存のアルゴリズムのほとんどは特定のドメインに特化しており、マルチコンセプトの生成、テスト時の微調整、およびオープンドメインのゼロショット能力の処理には手が届きません。 そこで、今日は私たちがオープンドメインの個人化に一歩近づいた新しいアプローチについて紹介します。それがSubject-Diffusionです。 SubjectDiffusionは高品質な主題駆動型画像を生成することができます。出典: https://arxiv.org/pdf/2307.11410.pdf Subject-Diffusionは革新的なオープンドメインの個人化テキストから画像への生成フレームワークです。1つの参照画像のみを使用し、テスト時の微調整の必要性を排除しています。個人化画像生成のための大規模なデータセットを構築するために、自動データラベリングツールを活用し、76百万枚の画像と22億2200万のエンティティを備えたSubject-Diffusionデータセット(SDD)が作成されました。 Subject-Diffusionには、3つの主要なコンポーネントがあります:位置制御、細かい参照画像制御、および注目制御です。位置制御では、ノイズ注入プロセス中に主要な主題のマスク画像を追加します。細かい参照画像制御では、テキストと画像の情報を組み合わせたモジュールを使用して、両方の細かさの統合を改善します。複数の主題のスムーズな生成を可能にするために、トレーニング中に注目制御が導入されます。 SubjectDiffusionの概要。出典: https://arxiv.org/pdf/2307.11410.pdf Subject-Diffusionは高い忠実度と汎化性能を実現し、1つの参照画像ごとに形状、姿勢、背景、スタイルの変更を加えた単一の主題、複数の主題、人物主体の個人化画像を生成することができます。また、特別に設計されたノイズ除去プロセスを介して、カスタマイズされた画像とテキストの説明との間のスムーズな補間を可能にします。定量的な比較によれば、Subject-Diffusionはさまざまなベンチマークデータセットで、テスト時の微調整あり・なしの他の最先端手法と比較して優れた性能を示しています。

「BeLFusionに出会ってください:潜在的拡散を用いた現実的かつ多様な確率的人間の動作予測のための行動的潜在空間アプローチ」
人工知能(AI)が世界を魅了し続ける中で、コンピュータビジョンとAIの交差点において、人間の動き予測(HMP)という注目すべき応用が登場しています。この魅力的なタスクは、観測された動きのシーケンスに基づいて、人間の将来の動きや行動を予測することを目的としています。その目標は、人の体のポーズや動きがどのように進化するかを予測することです。HMPは、ロボット工学、仮想アバター、自律型車両、人間とコンピュータのインタラクションなど、さまざまな分野で応用されています。 確率的HMPは、単一の決定論的な将来ではなく、可能な将来の動きの分布を予測することに焦点を当てた伝統的なHMPの拡張です。このアプローチは、人間の行動の本質的な自発性と予測不可能性を認識し、将来の行動や動きに関連する不確実性を捉えることを目指しています。確率的HMPは、可能な将来の動きの分布を考慮することで、人間の行動の可変性と多様性を考慮し、より現実的かつ柔軟な予測を実現します。アシストロボットや監視アプリケーションなど、複数の可能な行動を予測することが重要な場合に特に価値があります。 確率的HMPは、通常、観測されたシーケンスごとに複数の将来の動きを予測するためにGANやVAEなどの生成モデルを使用してアプローチされます。しかし、この座標空間で多様な動きを生成することに重点を置いた方法は、観測された動きとよりよく整合する必要がある非現実的で速い動きの発散予測につながる場合があります。さらに、これらの方法は、微小な関節変位を伴う広範囲の多様な低レンジの行動を予測することをしばしば見落とします。その結果、行動の多様性を考慮し、確率的HMPタスクでより現実的な予測を行うための新たなアプローチが必要とされています。既存の確率的HMPの手法の制約に対処するために、バルセロナ大学とコンピュータビジョンセンターの研究者は、BeLFusionを提案しています。この新しいアプローチは、現実的かつ多様な人間の動きのシーケンスを生成するための行動潜在空間を導入しています。 生成モデルにおける速く発散する動き。 BeLFusionの主な目的は、動作をポーズから滑らかに遷移させることで、観測されたポーズと予測されたポーズの間の遷移をスムーズにすることです。これは、行動エンコーダ、行動カプラー、コンテキストエンコーダ、補助デコーダから構成される行動VAEによって達成されます。行動エンコーダは、ゲート付き再帰ユニット(GRU)と2D畳み込み層を組み合わせて、関節座標を潜在分布にマッピングします。次に、行動カプラーは、サンプリングされた行動を進行中の動きに転送し、多様で文脈に適した動きを生成します。BeLFusionは、条件付き潜在拡散モデル(LDM)も組み込んでおり、行動の動態を正確にエンコードし、それらを進行中の動きに効果的に転送するとともに、潜在エラーや再構成エラーを最小限に抑えて生成される動きの多様性を高めます。 BeLFusionの革新的なアーキテクチャは、関節座標から隠れた状態を生成するオブザベーションエンコーダで続きます。このモデルでは、行動がポーズと動きから分離された潜在空間からサンプリングされるように、U-Net、クロスアテンションメカニズム、残余ブロックを使用した潜在拡散モデル(LDM)を利用しています。行動の観点からの多様性を促進し、直近の一貫性を維持することにより、BeLFusionは、確率的HMPの最先端手法よりもはるかに現実的で一貫した動きの予測を生み出します。行動の分離と潜在拡散のユニークな組み合わせにより、BeLFusionは人間の動き予測における有望な進歩を表しています。さまざまなアプリケーションに対してより自然で文脈に適した動きを生成する可能性を提供します。 実験評価により、BeLFusionの印象的な汎化能力が示されました。BeLFusionは、既知のシナリオと未知のシナリオの両方で優れたパフォーマンスを発揮します。Human3.6MおよびAMASSデータセットの厳しい結果を使用したクロスデータセット評価において、さまざまなメトリックで最先端の手法を上回ります。H36Mでは、BeLFusionは平均変位誤差(ADE)がおよそ0.372、最終変位誤差(FDE)が約0.474であります。同時に、AMASSでは、ADEが約1.977、FDEがおよそ0.513となります。これらの結果は、BeLFusionの正確で多様な予測を生成する優れた能力を示し、異なるデータセットやアクションクラスにおける現実的な人間の動作予測における有効性と汎化能力を示しています。 全体的に、BeLFusionは、Human3.6MおよびAMASSデータセットの精度メトリックにおいて最先端のパフォーマンスを達成する、人間の動作予測のための新しい手法です。BeLFusionは、行動の潜在空間と潜在拡散モデルを利用して、多様でコンテキスト適応型の予測を生成します。この手法によるシーケンス間での行動の捕捉と転送能力により、ドメインシフトに対して堅牢性が向上し、汎化能力も向上します。さらに、定性評価により、BeLFusionの予測が他の最先端の手法よりも現実的であることが示されました。アニメーション、仮想現実、ロボット工学など、人間の動作予測における有望な解決策を提供します。

究極のGFNサーズデー:41の新しいゲームに加えて、8月には「Baldur’s Gate 3」の完全版リリースと初めてベセスダのタイトルがクラウドに参加します
究極のアップグレードは完了しました。GeForce NOWアルティメットパフォーマンスは、北米とヨーロッパ全域でストリーミングされ、これらの地域のゲーマーにRTX 4080クラスのパワーを提供しています。この月は、Baldur’s Gate 3のフルリリースと、NVIDIAとMicrosoftのパートナーシップにより、最初のBethesdaタイトルがクラウドに登場することで、41の新しいゲームを迎えましょう。 そして、QuakeConでGeForce NOWを見逃さないでください。8月10日から13日まで開催されるこの人気のあるBYOPCメガイベントでは、対面とデジタルのGeForce NOWアルティメットチャレンジが始まります。 さらに、ゲーミング周辺機器メーカーのSteelSeriesと一緒にゲームを楽しんでください。彼らは3日間のGeForce NOWアルティメットおよびプライオリティメンバーシップ、人気のあるGeForce NOWゲーム、ゲーム内の特典コードをプレゼントします。 究極の展開 究極のメンバーは、自分の最大のPCゲームの可能性を引き出しました。 今年、世界中にGeForce RTX 4080 SuperPODが展開され、最新のクラウドパフォーマンスで都市を照らしました。RTX 3080メンバーはアルティメットメンバーシップを導入され、4K解像度でのゲームプレイを120フレーム/秒、またはNVIDIA Reflexテクノロジーによる超低遅延で240 fpsまで楽しむことができました。 アルティメットメンバーシップでは、NVIDIA Ada Lovelaceアーキテクチャの恩恵も受けることができます。これには、最高のフレームレートとビジュアルの忠実度を実現するフレーム生成のDLSS 3と、最も没入感のある映画のようなゲーム内照明体験のためのフルレイトレーシングが含まれます。さらに、クラウドから初めて超広角解像度もサポートされました。…

「マスタリングモンテカルロ:より良い機械学習モデルをシミュレーションする方法」
モンテカルロ:統計的シミュレーションが機械学習を支える方法、πの推定からハイパーパラメータの最適化までPythonでこの多目的なテクニックを使用するためのガイド
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.