Learn more about Search Results MPT - Page 54

- You may be interested
- 「QLORAとは:効率的なファインチューニン...
- 「ODSC West Bootcamp Roadmapのご紹介 &#...
- Jasper AI レビュー(2023年7月):最高の...
- 認知AI:人間のように考えるAIへの道
- NVIDIAのCEO、ヨーロッパの生成AIエグゼク...
- 「データ冗長性とは何ですか?利点、欠点...
- 最適なパイプラインとトランスフォーマー...
- ビデオアクション認識を最適化するにはど...
- ラジアルトリーマップ:トリーマップを円...
- 詳細に説明されたLlama 2:Metaの大型言語...
- マスク2フォーマーとワンフォーマーによる...
- 「2024年に注目すべきトップ5のWeb3企業」
- 素晴らしい応用(データ)科学の仕事
- 自分のドキュメントで春のAIとOpenAI GPT...
- 「ラマ-2、GPT-4、またはクロード-2;どの...

「ジェネラティブAIおよびMLモデルを使用したメールおよびモバイル件名の最適化」
「ジェネレーティブAIとMLモデルを併用して、最大のエンゲージメントを得るために、トーンと対象読者に合わせた魅力的な件名やタイトルを自動的に作成する」

「Llama 2がコーディングを学ぶ」
イントロダクション Code Llamaは、コードタスクに特化した最新のオープンアクセスバージョンであり、Hugging Faceエコシステムでの統合をリリースすることに興奮しています! Code Llamaは、Llama 2と同じ許容されるコミュニティライセンスでリリースされ、商業利用が可能です。 今日、私たちは以下をリリースすることに興奮しています: モデルカードとライセンスを備えたHub上のモデル Transformersの統合 高速かつ効率的な本番用推論のためのテキスト生成推論との統合 推論エンドポイントとの統合 コードのベンチマーク Code LLMは、ソフトウェアエンジニアにとってのエキサイティングな開発です。IDEでのコード補完により生産性を向上させることができ、ドックストリングの記述などの繰り返しや面倒なタスクを処理することができ、ユニットテストを作成することもできます。 目次 イントロダクション 目次 Code Llamaとは? Code Llamaの使い方 デモ Transformers…

OpenAIはGPT-3.5 Turboのファインチューニングによるカスタムパワーを解放します
人工知能の絶え間なく進化する世界で、OpenAIは革命的なアップデートを解放しました。それは、私たちが機械とどのようにインタラクトするかを再定義するものです。新しい仲間はGPT-3.5 Turboで、ファインチューニングの力を前面に押し出しています。これにより、テキスト生成の能力で知られるAIが特定のタスクや振る舞いに合わせてカスタマイズできるようになり、無限の可能性が開かれます。 また読む:GPTBotの公開:OpenAIのウェブクローリングへの大胆な一手 期待を上回る:GPT-3.5 Turboの著名な特徴 GPT-3.5 Turboはただのアップグレードではありません。OpenAIは大胆にも、この軽量AIのファインチューニングバージョンが、ある特定のタスクでGPT-4と肩を並べるか、さらに優れることを主張しています。まるでお気に入りのアンダードッグが一躍チャンピオンに挑戦するようです。 AIの可能性を解き放つ:GPT-3.5 Turboの新しいカスタマイズ GPT-3.5 Turboの登場以来、開発者やビジネスは個別のカスタマイズを望んでいました。OpenAIはその声に応えました。このアップデートにより、開発者は意図した役割で優れたモデルを作り上げることができ、ユーザーにはユニークでパーソナライズされた体験を提供することができます。特定の言語を模倣したり、回答のフォーマットを完璧にしたり、理想的なトーンを追求したりするために、GPT-3.5 Turboは今や選択肢のツールとなりました。 また読む:パーソナライズされたAIインタラクションのためのChatGPT用カスタムインストラクションの開始 無駄を削ぎ落とす:短いプロンプト、高速な結果 ここには最高の仕上げがあります:ファインチューニングによってAIはよりスマートになるだけでなく、より効率的になります。GPT-3.5 Turboを使用するビジネスは、プロンプトのサイズを縮小することでAPI呼び出しを高速化し、コストを節約することができます。初期のテストでは、ファインチューニングによってプロンプトのサイズが最大90%削減されたと報告されています。 可能性を解き放つ:輝くユースケース ファインチューニングは単なる言葉ではなく、AIのスーパーパワーです。ブランドの声に共鳴するチャットボットや、瞬時にタグラインやソーシャル投稿を作り出す広告の天才を想像してみてください。GPT-3.5 Turboは翻訳を革新し、レポートの作成を効率化し、コードを生成し、テキストを要約することも可能です。そのポテンシャルは無限です。 また読む:10分でPythonでGPT-3.5を使用した書籍サマライザーを作成する 肝心なのは:ファインチューニングの仕組み ファインチューニングは魔法のように聞こえますが、それは科学です。データの準備、ファイルのアップロード、OpenAIのAPIを介したファインチューニングジョブの作成がプロセスのスタートです。しかし、全てがスムーズに進むわけではありません。ファインチューニングされたデータは、安全基準を確保するためにモデレーションAPIとGPT-4パワードのモデレーションシステムによる厳格なチェックを受けます。しかし、それだけではありません!OpenAIはファインチューニングUIも導入する予定で、プロセスをよりスムーズにします。 また読む:大規模言語モデルのファインチューニングの包括的なガイド 数字を計算する:コストはいくらか?…
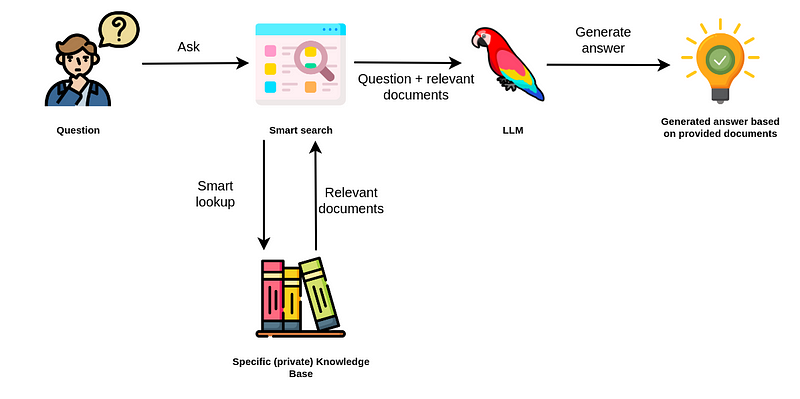
「Neo4jにおける非構造化テキストに対する効率的な意味検索」
ChatGPTが6か月前に登場して以来、技術の風景は変革的な転換を遂げましたChatGPTの優れた一般化能力により、...

「ODSC West Data PrimerシリーズでAIの学習を始めましょう」
「ODSC West Mini-Bootcamp Passの一環としてのData Primerシリーズは、AIの旅を始めるための黄金のチケットです8月から10月までの間に開催されるこれらのライブで仮想的なプレブートキャンプセッションは、10月30日から開催されるODSC Westカンファレンスで最大限の効果を得る準備を整えます」

あなたのGen AIプロジェクトで活用するための10のヒントとトリック
現在、実際に利用されている生成型AIアプリケーションはあまり多くはありませんここで言っているのは、それらがエンドユーザーによって展開され、活発に使用されていることを意味します(デモ、POC、および抽出型AIは含まれません)生成型AIは…

「IDEFICSをご紹介します:最新の視覚言語モデルのオープンな再現」
私たちは、IDEFICS(Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS)をリリースすることを喜んでいます。IDEFICSは、Flamingoに基づいたオープンアクセスのビジュアル言語モデルです。FlamingoはDeepMindによって開発された最先端のビジュアル言語モデルであり、公開されていません。GPT-4と同様に、このモデルは画像とテキストの任意のシーケンスを受け入れ、テキストの出力を生成します。IDEFICSは、公開されているデータとモデル(LLaMA v1およびOpenCLIP)のみを使用して構築されており、ベースバージョンと指示付きバージョンの2つのバリアントが9,000,000,000および80,000,000,000のパラメーターサイズで利用可能です。 最先端のAIモデルの開発はより透明性を持つべきです。IDEFICSの目標は、Flamingoのような大規模な専有モデルの能力に匹敵するシステムを再現し、AIコミュニティに提供することです。そのために、これらのAIシステムに透明性をもたらすために重要なステップを踏みました。公開されているデータのみを使用し、トレーニングデータセットを探索するためのツールを提供し、このようなアーティファクトの構築における技術的な教訓とミスを共有し、リリース前に敵対的なプロンプトを使用してモデルの有害性を評価しました。IDEFICSは、マルチモーダルAIシステムのよりオープンな研究のための堅固な基盤として機能することを期待しています。また、9,000,000,000のパラメータースケールでのFlamingoの別のオープン再現であるOpenFlamingoなどのモデルと並んでいます。 デモとモデルをハブで試してみてください! IDEFICSとは何ですか? IDEFICSは、80,000,000,000のパラメーターを持つマルチモーダルモデルであり、画像とテキストのシーケンスを入力とし、一貫したテキストを出力します。画像に関する質問に答えることができ、視覚的なコンテンツを説明し、複数の画像に基づいて物語を作成することができます。 IDEFICSは、Flamingoのオープンアクセス再現であり、さまざまな画像テキスト理解ベンチマークで元のクローズドソースモデルと同等のパフォーマンスを発揮します。80,000,000,000および9,000,000,000のパラメーターの2つのバリアントがあります。 会話型の使用事例に適した、idefics-80B-instructとidefics-9B-instructのファインチューニングバージョンも提供しています。 トレーニングデータ IDEFICSは、Wikipedia、Public Multimodal Dataset、LAION、および新しい115BトークンのデータセットであるOBELICSのオープンデータセットの混合物でトレーニングされました。OBELICSは、ウェブからスクレイプされた141,000,000の交互に配置された画像テキストドキュメントで構成され、353,000,000の画像を含んでいます。 OBELICSの内容をNomic AIで探索できるインタラクティブな可視化も提供しています。 IDEFICSのアーキテクチャ、トレーニング方法論、評価、およびデータセットに関する詳細は、モデルカードと研究論文で入手できます。さらに、モデルのトレーニングから得られた技術的な洞察と学びを文書化しており、IDEFICSの開発に関する貴重な見解を提供しています。 倫理的評価…

あなたのCopy-Paste ChatGPTカスタムの指示は、こちらです
「ChatGPTの有料アカウントでは、カスタム指示の使用が可能になりましたこの記事では、なぜそれを使うのか、そしてどのように使うのかについて説明しますまた、自分自身の利用のためにコピーできるテキストも提供します」

「ドメイン固有のLLMポーションの調合」
あなたのLLMをあなたの専門分野のエキスパートにしましょう

「LlaMA 2の始め方 | メタの新しい生成AI」
イントロダクション OpenAIからGPTがリリースされて以来、多くの企業が独自の堅牢な生成型大規模言語モデルを作成するための競争に参入しました。ゼロから生成型AIを作成するには、生成型AIの分野での徹底的な研究と数多くの試行錯誤が必要な場合があります。また、大規模言語モデルの効果は、それらが訓練されるデータに大きく依存するため、高品質なデータセットを注意深く編集する必要があります。さらに、これらのモデルを訓練するためには膨大な計算能力が必要であり、多くの企業がアクセスできない状況です。そのため、現時点では、OpenAIやGoogleを含むわずかな企業しかこれらの大規模言語モデルを作成できません。そして、ついにMetaがLlaMAの導入でこの競争に参加しました。 学習目標 新しいバージョンのLlaMAについて知る モデルのバージョン、パラメータ、モデルのベンチマークを理解する Llama 2ファミリのモデルにアクセスする さまざまなプロンプトでLlaMA 2を試して出力を観察する この記事はData Science Blogathonの一環として公開されました。 Llamaとは何ですか? LlaMA(Large Language Model Meta AI)は、特にMeta AI(元Facebook)が所有する会社であるMeta AIによって開発された基礎となる大規模言語モデルのグループである生成型AIモデルです。Metaは2023年2月にLlamaを発表しました。Metaは、7、13、33、および65兆のパラメータを持つコンテキスト長2kトークンの異なるサイズのLlamaをリリースしました。このモデルは、研究者がAIの分野での知識を進めるのを支援することを目的としています。小型の7Bモデルは、計算能力が低い研究者がこれらのモデルを研究することを可能にします。 LlaMaの導入により、MetaはLLMの領域に参入し、OpenAIのGPTやGoogleのPaLMモデルと競合しています。Metaは、限られた計算リソースで小さなモデルを再トレーニングまたは微調整することで、それぞれの分野で最先端のモデルと同等の結果を達成できると考えています。Meta AIのLlaMaは、LlaMAモデルファミリが完全にオープンソースであり、誰でも無料で使用できるだけでなく、研究者のためにLlaMAの重みを非営利目的で公開しているため、OpenAIやGoogleのLLMとは異なります。 前進 LlaMA…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.