Learn more about Search Results メール - Page 54

- You may be interested
- TaatikNet(ターティクネット):ヘブライ...
- 「USENET、OGソーシャルネットワークが、...
- 「新しいAIの研究が、化学的な匂いを説明...
- 大ニュース:Google、ジェミニAIモデルの...
- クラウドコンピューティングはデータサイ...
- AIツールが超新星を発見します
- 人間だけが解決できるAIの課題
- 「最も強力な機械学習モデルの解説(トラ...
- 「GoogleやOpenAIなどの主要なテック企業...
- 「サポートベクターマシン(SVM)とは何で...
- 「トップのGPTとAIコンテンツ検出器」
- アマゾンのSageMakerジオスペーシャル機能...
- GPT4Allは、あなたのドキュメント用のロー...
- 「ReLU vs. Softmax in Vision Transforme...
- 「7月24日から7月31日までの週間でのトッ...

「FlexGenに会おう:GPUメモリが限られている場合に大規模な言語モデル(LLM)を実行するための高スループットな生成エンジン」
大規模言語モデル(LLM)は最近、さまざまなタスクで印象的なパフォーマンスを発揮しています。生成型LLMの推論は以前にないほどの力を持っていますが、特定の困難にも直面しています。これらのモデルは数十億または数兆のパラメータを含むことがあり、それらを実行するには膨大なメモリと計算能力が必要です。例えば、GPT-175Bは、モデルの重みを読み込むために325GBのGPU RAMだけが必要です。このモデルをGPUに適合させるには、少なくとも5つのA100(80GB)のGPUと高度な並列処理技術が必要です。そのため、LLM推論に必要なリソースの削減は最近、多くの関心を集めています。 LLMは、ベンチマーキング、情報抽出、データ整形、フォーム処理、チャットボットなどのさまざまな「裏方」の操作に使用されます。この研究では、スループット志向の生成型推論という状況に焦点を当てています。企業のコーパスの全ペーパーなど、大量のトークンにわたってバッチでLLM推論を実行する必要があるため、トークン生成の遅延への感受性が低いというのがこれらのジョブの重要な特徴です。そのため、一部のワークロードでは、遅延を犠牲にしてスループットを向上させることで、リソースの必要性を低減する可能性があります。 LLM推論に必要なリソースを削減するためには、次の3つのアプローチが使用されています: 全体のメモリフットプリントを減らすためのモデル圧縮、推論のコストを分散させるための共同推論、メモリとディスク上のメモリの効果的な利用のためのオフロード。明確な制約は存在しますが、これらの戦略により、LLMの利用に必要なリソースが大幅に削減されています。最初の2つの方法の研究では、モデルがGPUメモリに収まることを前提としているため、単一の商用GPU上で175Bスケールのモデルを実行するための支援が必要です。一方、第3のカテゴリに属する最先端のオフローディングベースのシステムは、効果的なI/Oスケジューリングとテンソル配置ができないため、単一のGPU上で受け入れ可能なスループットに到達することはできません。 単一の商用GPUを使用して、彼らの主な目標は高スループットの生成型推論のための効果的なオフロードメカニズムを構築することです。彼らはLLMを部分的にロードし、制約のあるGPUメモリでのLLMの演算を逐次的にオフロードして実行することができます。典型的なシステムでは、メモリの階層は3つの層に分かれています。下位レベルは遅いですが豊富で、上位レベルは速いですが希少です。小さなバッチサイズはこれらのシステムでボトルネックを引き起こす可能性があります。高バッチサイズを使用し、高価なI/O操作を複数のメモリ階層に分散させて処理と重なり合わせることで、スループット志向のシナリオでは遅延を犠牲にすることができます。 ただし、遅延を犠牲にしても、制約のあるGPUメモリで高スループットの生成型推論を達成することは困難です。最初の困難は、成功するオフローディング計画を立てることです。計画では、どのテンソルをオフロードするか、3レベルのメモリ構造のどこにオフロードするか、推論中にいつオフロードするかを明確にする必要があります。生成型推論では、重み、アクティベーション、キー値(KV)キャッシュの3種類のテンソルが使用されます。 アルゴリズムのバッチごと、トークンごと、レイヤごとの構造のため、計算方法はいくつかあります。これらのオプションが組み合わさって複雑な設計空間が作成されます。現在使用されているオフローディングベースの推論システムは、過度のI/Oを実行し、理論的なハードウェアの制約に比べてスループットが大幅に低下しているため、推論においては劣悪な領域となっています。効率的な圧縮アルゴリズムの作成は、2番目の問題を提起します。以前の出版物では、LLMの重みとアクティベーションは、有望な圧縮結果を示しています。ただし、高スループットの生成型推論のために圧縮とオフロードを組み合わせる場合、重みとKVキャッシュのI/Oコストとメモリ削減によって追加の圧縮戦略が推進されます。 UCB、Stanford、CMU、Meta、Yandex、ETH、HSEの研究者たちは、これらの問題を克服するために、高スループットのLLM推論のためのオフロードフレームワークであるFlexGenを共同で紹介しています。FlexGenは、GPU、CPU、ディスクからのメモリを組み合わせて、効果的なI/Oアクティビティ、潜在的な圧縮技術、および分散パイプライン並列処理を効果的にスケジュールします。彼らの貢献は以下の通りです: 計算スケジュール、テンソル配置、計算委任を考慮した潜在的なオフロードオプションの検索空間を明示的に説明します。彼らは、その検索空間がI/Oの複雑さを最適性の2つ以内に捉える計算順序を表していることを示します。次に、彼らは検索空間内でスループットを最大化するための線形計画に基づく検索アルゴリズムを作成します。 再トレーニングやキャリブレーションなしに、OPT-175BのようなLLMの重みとKVキャッシュを4ビットに減らすことが可能で、ほとんどまたは全く精度の低下がありません。I/Oコストとオフロード時のメモリ使用量を低減するために適した細かいグループごとの量子化がこれを実現しています。 彼らは、NVIDIA T4(16GB)GPU上でOPT-175Bを実行することで、FlexGenの効率を示します。FlexGenは、DeepSpeed Zero-InferenceやHugging Face Accelerateといった2つの最先端のオフローディングベースの推論アルゴリズムよりも大きなバッチサイズを許容することが多く、その結果、大幅に高いスループットを実現できます。 以下に、PaperとGithubをご覧ください。この研究に関するすべてのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュースや素敵なAIプロジェクトなどを共有している16k+ ML SubReddit、Discordチャンネル、およびメールニュースレターにもぜひ参加してください。 Tensorleapの解釈性プラットフォームで深層学習の秘密を解き放つ この投稿は、MarkTechPostに掲載されています。

2023年の最高のオープンソースインテリジェンス(OSINT)ツール
「OSINT」という頭字語は、オープンソースインテリジェンスソフトウェアを指します。これらのプログラムはオープンソースからデータを収集するために使用されます。OSINTツールは、主に対象となる個人や会社に関する情報を収集するために使用されます。 以下に、最も一般的なOSINTツールをリストアップします(特定の順序ではありません): Maltego Maltegoは柔軟なオープンソースインテリジェンスプラットフォームであり、短縮し、問い合わせを高速化することができます。58のデータソースにアクセスすることで、より正確な調査を容易にし、最大100万のエンティティを収容するデータベースを提供します。強力な可視化機能により、ブロック、階層、または円グラフなど、さまざまな形式から選択し、より詳細な分析のために重みと注釈を追加することもできます。 信頼性と安全性のチーム、法執行機関、およびサイバーセキュリティの専門家は、Maltegoが単一のクリックで調査結果と理解しやすい洞察を提供する能力を活用することができます。 Intel 471 Intel 471は無料でオープンソースのOSINT偵察ツールであり、IPアドレス、CIDRレンジ、ドメインやサブドメイン、AS番号、メールアドレス、電話番号、名前やユーザー名、さらにはBitcoinアドレスなど、さまざまな情報を収集および分析することができます。 Intel 471には200以上のモジュールがあり、最も包括的な操作を実行し、任意の対象に関する重要な事実を明らかにすることができます。コマンドラインインターフェースと使いやすいGUIインターフェースを備えた組み込みのWebサーバーの両方をGitHubで利用することができます。 企業内で公開されたデータによるセキュリティ上の脆弱性が存在するかどうかを確認するために使用することができます。全体として、これは潜在的に危険なインターネット組織に関する以前に知られていなかった情報を明らかにする能力を持つ強力なサイバーインテリジェンスツールです。 OSINT Framework オープンソースインテリジェンス(OSINT)フレームワークは優れたツールです。データソースから有用な接続や成功したツールまで、すべてが含まれているため、独自にすべてのアプリケーションやツールを調査するよりも便利です。 このリストはLinuxに限定されているわけではありません。他のOSの代替手段も提供しており、ユニバーサルなリソースとなっています。実際、このように整理されたリソースを持つことは、以前よりもさらに有益です。唯一の困難は、車の登録やメールアドレスなどの結果を絞り込む効率的な検索技術を考案することです。オープンソースインテリジェンス(OSINT)フレームワークは、情報を収集し、データを整理するための頼りになるツールになりつつあります。 SEON 人物のソーシャルメディアやその他のオンラインアカウントを使用して、その個人の身元を証明することは、今日のデジタル経済においてますます一般的になっています。SEONはデジタルアイデンティティを検証するために先導をしています。 SEONでは、電子メールや電話番号のシステムを使用して、50以上のソーシャルシグナルにアクセスすることができます。これらのシグナルは、顧客の電子メールアドレスや電話番号を確認するだけでなく、顧客のオンライン行動に関する追加情報を収集します。 使いやすさとアクセシビリティに加えて、SEONは直接クエリを実装したり、API経由でクエリを実行したり、Google Chromeのプラグインを介してクエリを実行したりすることも可能です。 Lampyre LampyreはOSINTに特化したプレミアムソフトウェアであり、デューデリジェンス、サイバー脅威インテリジェンス、犯罪捜査、および金融分析などに効果的に役立ちます。1つのデータポイント(企業登録番号、完全な名前、または電話番号など)から始めて、100以上の頻繁に更新されるデータソースを自動的に分析することができます。 情報を取得するために、コンピュータに1回クリックしてインストールするか、ブラウザで使用することができます。…

「中国人がマイクロソフトのクラウドをハックし、1ヶ月以上検出されずにいた」
最近発覚した重大なサイバーセキュリティ侵害により、中国のハッカーがMicrosoftのクラウドメールサービスの脆弱性を利用して、米国政府職員のメールアカウントに不正アクセスを行いました。この侵害は1か月以上も検出されず、機密性の高い政府情報のセキュリティに対する懸念を引き起こし、攻撃の範囲を調査することが求められています。 また、読む: RSA Conference 2023の概要:AIがサイバーセキュリティで中心に Storm-0558:リソースの豊富なハッキンググループ Storm-0558としてMicrosoftによって特定されたハッキンググループは、政府機関やこれらの組織に関連する個人のメールアカウントを含む約25のメールアカウントを侵害しました。Microsoftは新興および発展中のハッキンググループを追跡するために「Storm」というコードネームを使用しています。具体的に対象とされた政府機関は開示されていませんが、ホワイトハウス国家安全保障会議の広報担当者は、米国政府機関も影響を受けたと確認しています。 また、読む: プライバシーへの懸念の解決策:ChatGPTユーザーチャットタイトルの漏洩の説明 政府機関が警戒を呼びかける この侵害は、機密指定されていないシステムに影響を与えるMicrosoftのクラウドセキュリティに侵入が検出されたことで、米国政府のセキュリティ対策によって最初に特定されました。政府はすぐにMicrosoftに連絡し、彼らのクラウドサービスのソースと脆弱性を調査するよう要請しました。この事件は、政府の調達プロバイダーに対する堅牢なセキュリティ対策の重要性を浮き彫りにしました。 また、読む: 重要なクラウドセキュリティプロトコルの導入 国務省も影響を受ける 報告によると、国務省はこの攻撃の被害を受けた連邦機関の一つでした。国務省は迅速な対策が必要であるとして、侵害をMicrosoftに通報しました。 また、読む: クラウドベースシステムにおけるエンドポイントセキュリティの仕組み Microsoftの調査により攻撃手法が明らかに Microsoftは侵害について広範な調査を行い、中国を拠点とする「リソースの豊富な」ハッキンググループであるStorm-0558が、Outlook Web Access in Exchange Online…

「2023年7月のAIボイスチェンジャーツールのトップ10」
ボイスチェンジングソフトウェアは、ユーザーがリアルタイムで声を変更したり、事前に録音された音声を変更したりすることができるAIアプリケーションの一種ですこれらのソフトウェアソリューションは、声のピッチや速度を変えたり、ユーザーの声を有名人など他の誰かや何かに変換したりするなど、さまざまな効果を提供します

AIによる生産性向上 生成AIが様々な産業において効率の新たな時代を開く
2022年11月22日、ほとんど仮想的な瞬間が訪れ、それは地球上のほぼすべての産業の基盤を揺るがしました。 その日、OpenAIは史上最も高度な人工知能チャットボットであるChatGPTをリリースしました。これにより、消費者の質問に答えるための生成型AIアプリケーションから科学的なブレークスルーを追求する研究者の作業を加速するまで、ビジネスがより効率的になるための需要が生まれました。 以前はAIに手を出していた企業も、最新のアプリケーションを採用・展開するために急ぎます。アルゴリズムが新しいテキスト、画像、音声、アニメーション、3Dモデル、さらにはコンピュータコードを生成することができる生成型AIは、人々が働く・遊ぶ方法を変革しています。 大規模な言語モデル(LLM)を用いてクエリを処理することにより、この技術は情報の検索や編集などの手作業に費やす時間を劇的に短縮することができます。 その賭けは大きいです。PwCによると、AIは2030年までに世界経済に1兆5千億ドル以上をもたらす可能性があります。そして、AIの導入の影響はインターネット、モバイルブロードバンド、スマートフォンの発明以上に大きいかもしれません。 生成型AIを推進するエンジンは、高速計算です。これは、科学、分析、エンジニアリング、消費者およびエンタープライズのユースケース全般にわたり、GPU、DPU、ネットワーキング、およびCPUを使用してアプリケーションを高速化します。 早期の採用企業は、薬剤探索、金融サービス、小売、通信、エネルギー、高等教育、公共部門など、さまざまな業界で、高速計算と生成型AIを組み合わせてビジネスのオペレーション、サービス提供、生産性の向上を実現しています。 インフォグラフィックを表示するにはクリックしてください:次世代のAI変革を生み出す 薬剤探索のための生成型AI 今日、放射線科医はAIを使用して医療画像の異常を検出し、医師は電子健康記録をスキャンして患者の洞察を明らかにし、研究者は新しい薬剤の発見を加速するためにそれを使用しています。 従来の薬剤探索は、5000以上の化学物質の合成を必要とし、平均的な成功率はわずか10%です。そして、ほとんどの新薬候補が市場に出るまでに10年以上かかります。 研究者は、生成型AIモデルを使用してタンパク質のアミノ酸配列を読み取り、ターゲットタンパク質の構造を秒単位で正確に予測することができます。これには数週間または数か月かかることがあります。 NVIDIAのBioNeMoモデルを使用して、バイオテクノロジーの世界的リーダーであるアムジェンは、分子スクリーニングと最適化のためのモデルのカスタマイズにかかる時間を3か月からわずか数週間に短縮しました。このタイプのトレーニング可能な基礎モデルにより、科学者は特定の疾患の研究のためのバリアントを作成し、希少な状態の治療法を開発することができます。 タンパク質構造の予測や大規模な実世界および合成データセットでのアルゴリズムの安全なトレーニングなど、生成型AIと高速計算は、疾病の拡散を緩和し、個別の医療治療を可能にし、患者の生存率を向上させるための新たな研究領域を開拓しています。 金融サービスのための生成型AI NVIDIAの最新の調査によると、金融サービス業界での主要なAIの活用事例は、カスタマーサービスとディープアナリティクスです。ここでは、自然言語処理とLLMが使用され、顧客の問い合わせにより良い対応をするためや投資の洞察を明らかにするために使用されています。別の一般的な応用は、パーソナライズされた銀行体験、マーケティング最適化、投資ガイダンスを提供する推薦システムです。 先進的なAIアプリケーションは、この業界が不正行為をより防止し、ポートフォリオ計画やリスク管理からコンプライアンスや自動化まで、銀行業務のあらゆる側面を変革する可能性があります。 ビジネスに関連する情報の80%は構造化されていない形式、主にテキスト形式ですが、これは生成型AIの主要な対象となります。Bloomberg Newsは、金融および投資コミュニティに関連するニュースを1日に5,000本も発行しています。これらの記事は、タイムリーな投資の決定をするために使用できる膨大な非構造化市場データの宝庫です。 NVIDIA、ドイツ銀行、ブルームバーグなどは、ドメイン固有のデータや独自のデータをトレーニングおよび微調整するために訓練されたLLMを作成して、金融アプリケーションに使用しています。 金融トランスフォーマー、または「FinFormers」は、非構造化の金融データの文脈を学び、意味を理解することができます。これらはQ&Aチャットボットのパワーを供給し、金融テキストを要約・翻訳し、取引先リスクの早期警告サインを提供し、データを迅速に取得し、データ品質の問題を特定することができます。 これらの生成型AIツールは、プロプライエタリデータをモデルトレーニングおよび微調整に統合し、バイアスを防ぐためのデータキュレーションを統合し、会話を金融に特化させるためのガードレールを使用するフレームワークに依存しています。 フィンテックスタートアップや大手国際銀行がLLMと生成型AIの使用を拡大し、内部および外部の利害関係者に対して洗練されたバーチャルアシスタントを提供し、ハイパーカスタマー向けのコンテンツを作成し、マニュアル作業を削減するために文書要約を自動化し、テラバイトの公共および非公開データを分析して投資の洞察を生成することを期待してください。 小売業における生成AI…

「AIは政治をより簡単、安価かつ危険にする」
「有権者はすでにAIによって作成された選挙キャンペーン資料を目にしている可能性がありますが、それに気づいていないかもしれません」
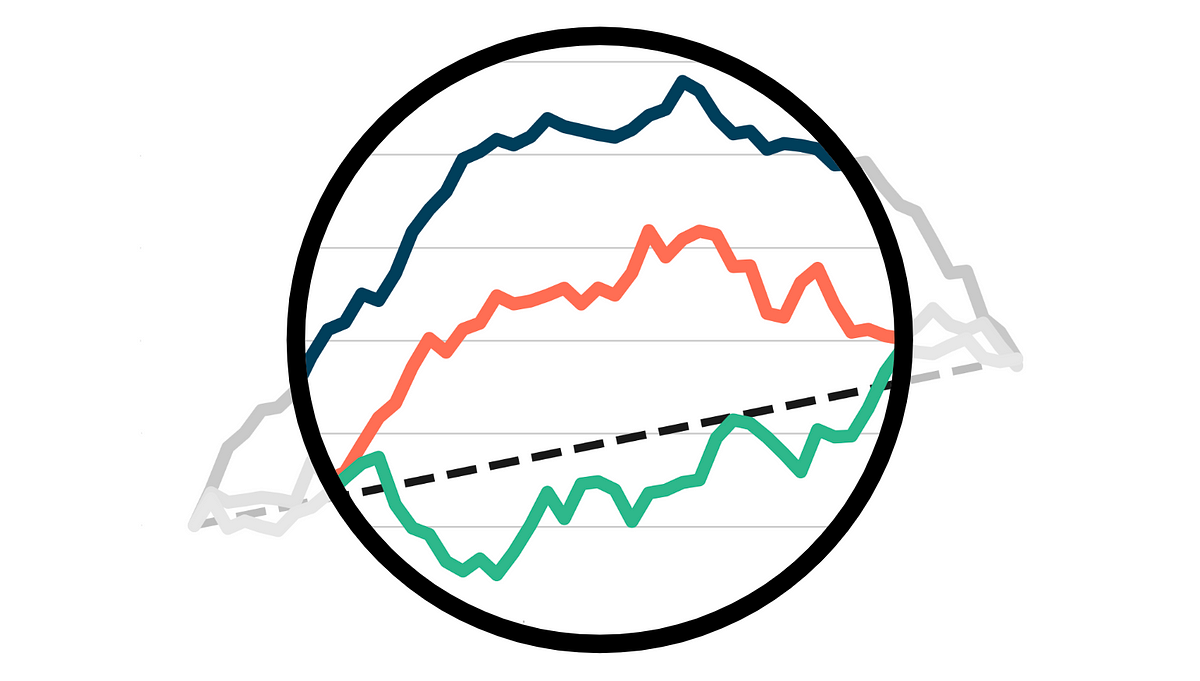
アップリフトモデルの評価
業界での因果推論の最も広く利用されているアプリケーションの1つは、アップリフトモデリング、または条件付き平均治療効果の推定ですある処置の因果効果を推定する際には、

データベースの最適化:SQLにおけるインデックスの探索
SQLにおけるインデックスについて学び、SELECTクエリとWHERE句の検索速度を向上させる方法について学びましょう

Jasper AI レビュー(2023年7月):最高のAIライティングジェネレーター?
「このJasper AIのレビューで最高のAIライティングジェネレーターを発見しましょう!このパワフルなツールで創造性と生産性を解き放ってください」
Mageを使用してデータパイプラインのコミュニケーションを効率化する方法
「Google Sheetsの1つの小さな手動ミスで、下流のデータパイプラインがブロックされたことはありますか?時には、そのシートさえもあなたのチームの所有物ではない場合もありますので…」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.