Learn more about Search Results Introduction to Python - Page 53

- You may be interested
- 「モダンデータウェアハウス」というテーマ
- 衝撃的な現実:ChatGPTのデータ漏洩への脆...
- Excel vs Tableau – どちらが優れたツール...
- 「HuggingFace Diffusersにおける拡散モデ...
- 「プロンプトチューニングとは何ですか?」
- 「2024年に注目すべきトップ10のリモート...
- 「K-Means初期化の課題に対する効果的な戦...
- Hugging FaceとAMDは、CPUおよびGPUプラッ...
- 「データサイエンスプロジェクトを変革す...
- 「ディープラーニングを用いたナノアレイ...
- Sixty AIは、デジタルライフを整理し、喜...
- スターリング-7B AIフィードバックからの...
- 意図しない漏洩から敏感なデータを保護す...
- Btech卒業後に何をすべきですか?
- 「2024年のソフトウェア開発のトレンドと...

事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
はじめに 事前学習済みのViTモデルを使用した画像キャプショニングは、画像の詳細な説明を提供するために画像の下に表示されるテキストまたは書き込みのことを指します。つまり、画像をテキストの説明に翻訳するタスクであり、ビジョン(画像)と言語(テキスト)を接続することで行われます。この記事では、PyTorchバックエンドを使用して、画像のViTを主要な技術として使用して、トランスフォーマーを使用した画像キャプショニングの生成方法を、スクラッチから再トレーニングすることなくトレーニング済みモデルを使用して実現します。 出典: Springer 現在のソーシャルメディアプラットフォームや画像のオンライン利用の流行に対応するため、この技術を学ぶことは、説明、引用、視覚障害者の支援、さらには検索エンジン最適化といった多くの理由で役立ちます。これは、画像を含むプロジェクトにとって非常に便利な技術であります。 学習目標 画像キャプショニングのアイデア ViTを使用した画像キャプチャリング トレーニング済みモデルを使用した画像キャプショニングの実行 Pythonを使用したトランスフォーマーの利用 この記事で使用されたコード全体は、このGitHubリポジトリで見つけることができます。 この記事は、データサイエンスブログマラソンの一環として公開されました。 トランスフォーマーモデルとは何ですか? ViTについて説明する前に、トランスフォーマーについて理解しましょう。Google Brainによって2017年に導入されて以来、トランスフォーマーはNLPの能力において注目を集めています。トランスフォーマーは、入力データの各部分の重要性を異なる重み付けする自己注意を採用して区別されるディープラーニングモデルです。これは、主に自然言語処理(NLP)の分野で使用されています。 トランスフォーマーは、自然言語のようなシーケンシャルな入力データを処理しますが、トランスフォーマーは一度にすべての入力を処理します。注意機構の助けを借りて、入力シーケンスの任意の位置にはコンテキストがあります。この効率性により、より並列化が可能となり、トレーニング時間が短縮され、効率が向上します。 トランスフォーマーアーキテクチャ 次に、トランスフォーマーのアーキテクチャの構成を見てみましょう。トランスフォーマーアーキテクチャは、主にエンコーダー-デコーダー構造から構成されています。トランスフォーマーアーキテクチャのエンコーダー-デコーダー構造は、「Attention Is All You Need」という有名な論文で発表されました。 エンコーダーは、各レイヤーが入力を反復的に処理することを担当し、一方で、デコーダーレイヤーはエンコーダーの出力を受け取り、デコードされた出力を生成します。単純に言えば、エンコーダーは入力シーケンスをシーケンスにマッピングし、それをデコーダーに供給します。デコーダーは、出力シーケンスを生成します。 ビジョン・トランスフォーマーとは何ですか?…

Mr. Pavan氏のデータエンジニアリングの道は、ビジネスの成功を導く
はじめに 私たちは、Pavanさんから学ぶ素晴らしい機会を得ました。彼は問題解決に情熱を持ち、持続的な成長を追求する経験豊富なデータエンジニアです。会話を通じて、Pavanさんは自身の経験、インスピレーション、課題、そして成し遂げたことを共有しています。そのため、データエンジニアリングの分野における貴重な知見を提供してくれます。 Pavanさんの実績を探索する中で、再利用可能なコンポーネントの開発、効率化されたデータパイプラインの作成、グローバルハッカソンの優勝などに誇りを持っていることがわかります。彼は、データエンジニアリングを通じてクライアントのビジネス成長を支援することに情熱を注いでおり、彼の仕事が彼らの成功に与える影響について共有してくれます。さあ、Pavanさんの経験と知恵から学んで、データエンジニアリングの世界に没頭しましょう。 インタビューを始めましょう! AV:自己紹介と経歴について教えてください。 Pavanさん:私は情報技術の学生として学問の道を歩み始めました。当時、この分野での有望な求人が私を駆り立てていました。しかし、私のプログラミングに対する見方はMSハッカソン「Yappon!」に参加した時に変わりました。その経験が私に深い情熱をもたらしました。それは私の人生の転機となり、プログラミングの世界をより深く探求するスパークを生み出しました。 それ以来、私は4つのハッカソンに積極的に参加し、うち3つを優勝するという刺激的な結果を残しました。これらの経験は私の技術的なスキルを磨き、タスクの自動化や効率的な解決策の探求に執念を燃やすようになりました。私はプロセスの効率化や繰り返しタスクの削減に挑戦することで成長しています。 個人的には、私は内向的と外向的のバランスを取るambivertだと考えています。しかし、私は常に自分の快適ゾーンから踏み出して、成長と発展のための新しい機会を受け入れるように自分自身を鼓舞しています。プログラミング以外の私の情熱の1つはトレッキングです。大自然を探索し、自然の美しさに浸ることには魅力的な何かがあります。 私のコンピュータサイエンス愛好家としての旅は、仕事の見通しに対する実用的な見方から始まりました。しかし、ハッカソンに参加することで、プログラミングに対する揺るぎない情熱に変わっていきました。成功したプロジェクトの実績を持ち、自動化の才能を持っていることから、私はスキルを拡大し、コンピュータサイエンス分野での積極的な貢献を続けることを熱望しています。 AV:あなたのキャリアに影響を与えた人物を数名挙げて、どのように影響を受けたか教えてください。 Pavanさん:まず、私は母親と祖母に感謝しています。彼女たちはサンスクリットの格言「Shatkarma Manushya yatnanam, saptakam daiva chintanam.」に象徴される価値観を私に教えてくれました。人間の努力と精神的な瞑想の重要性を強調したこの哲学は、私のキャリアを通じて指導原理となっています。彼女たちの揺るぎないサポートと信念は、私の常に刺激となっています。 また、私のB.Tech時代に教授だったSmriti Agrawal博士にも大きな成長を感じています。彼女はオートマトンとコンパイラ設計を教えながら、その科目についての深い理解を伝え、キャリア開発の重要性を強調しました。「6ヶ月で履歴書に1行も追加できない場合は、成長していない」という彼女の有益なアドバイスは、私のマインドセットを変えるきっかけになりました。このアドバイスは、私に目標を設定し、挑戦的なプロジェクトに取り組み、定期的にスキルセットを更新するよう駆り立て、私を常に成長と学びの機会に導いてくれました。 さらに、私にとって支援的な友人のネットワークを持っていることは幸運なことです。彼らは私のキャリアの旅において重要な役割を果たしています。彼らは、複雑なプログラミングの概念を理解するのを手伝ってくれたり、私をハッカソンに参加させてスキルを磨いたりすることで、私を引っ張り出し、最高の自分を引き出すのに欠かせない存在となっています。彼らの指導と励ましは、私を常に限界を超えて、最高の自分を引き出すのに不可欠であり、私の今までの進歩に欠かせません。 AV:なぜデータと一緒に働くことに興味を持ち、データエンジニアとしての役割の中で最もエキサイティングなことは何ですか? Pavanさん:私がデータと一緒に働くことに惹かれたのは、データが今日の世界であらゆるものを動かしていることを認識したからです。データは、意思決定の基盤であり、戦略の策定、革新の源泉です。データを生のままから意味のある洞察に変換し、それらの洞察を顧客やビジネスの成功につなげることが、私がデータと一緒に働くことに情熱を持つようになった原動力となりました。 データエンジニアとして私が最も興奮するのは、データ革命の最前線に立つ機会です。膨大な量の情報を効率的に収集、処理、分析するデータシステムを設計・実装する複雑なプロセスに魅了されています。データの膨大な量と複雑さは、創造的な問題解決と継続的な学習を必要とする刺激的な課題を提供します。 データエンジニアとして最もエキサイティングな側面の1つは、データの潜在的な可能性を引き出すことができることです。堅牢なパイプラインを構築し、高度な分析を実装し、最新技術を活用することで、情報を収集し、意思決定を支援し、変革につながる貴重な洞察を明らかにすることができます。データ駆動型のソリューションが直接顧客体験を改善し、業務効率を向上させ、ビジネス成長を促進する様子を見ることは、非常にやりがいを感じます。 また、この分野のダイナミックな性質は私を引っ張っていきます。データエンジニアリング技術と技法の急速な進歩は、常に新しいイノベーションの機会を提供してくれます。これらの進歩の最前線に立ち、継続的に学習し、スキルを磨き、複雑なデータ課題を解決するために適用することは、知的好奇心を刺激し、専門的にもやりがいを感じさせます。…

データサイエンスプロジェクトでのハードコーディングをやめましょう – 代わりに設定ファイルを使用しましょう
Pythonにおいて効率的に設定ファイルとやり取りする方法

AutoML – 機械学習モデルを構築するための No Code ソリューション
はじめに AutoMLは自動機械学習としても知られています。2018年、GoogleはクラウドAutoMLを発表し、大きな関心を集め、機械学習と人工知能の分野で最も重要なツールの1つとなりました。この記事では、「Google Cloud AutoML」を使った機械学習モデルを構築するためのノーコードソリューションである「AutoML」について学びます。 AutoMLは、Google Cloud Platform上のVertex AIの一部です。Vertex AIは、クラウド上で機械学習パイプラインを構築および作成するためのエンドツーエンドソリューションです。ただし、Vertex AIの詳細については、別の記事で説明します。AutoMLは、主に転移学習とニューラルサーチアーキテクチャに依存しています。データを提供するだけで、AutoMLはユースケースに最適なカスタムモデルを構築します。 この記事では、Pythonコードを使ったGoogle Cloud Platform上でのAutoMLの利点、使用方法、実践的な実装について説明します。 学習目標 コードを使ったAutoMLの使用方法を読者に知らせること AutoMLの利点を理解すること クライアントライブラリを使用してMLパイプラインを作成する方法 この記事は、Data Science Blogathonの一部として公開されました。 問題の説明 機械学習モデルを構築することは時間がかかり、プログラミング言語の熟練度、数学と統計の良い知識、および機械学習アルゴリズムの理解などの専門知識が必要です。過去には、技術的なスキルを持つ人々だけがデータサイエンスで働き、モデルを構築できました。非技術的な人々にとっては、機械学習モデルを構築することは最も困難なタスクでした。ただし、モデルを構築した技術的な人々にとっても道のりは容易ではありませんでした。モデルを構築した後、メンテナンス、展開、および自動スケーリングには追加の努力、労働時間、およびわずかに異なるスキルセットが必要です。これらの課題を克服するために、グローバル検索大手のGoogleは、2014年にAutoMLを発表しましたが、後に一般に公開されました。 AutoMLの利点 AutoMLは手動の介入を減らし、少しの機械学習の専門知識が必要となります。…

Netflix株の時系列分析(Pandasによる)
はじめに データの時系列分析は、この場合はNetflixの株式などの数字の集まりだけではありません。Pandasと組み合わさることで、複雑な世界の物語を魅力的に紡ぐ織物のようなものです。神秘的な糸のように、出来事の起伏や流れ、トレンドの上昇や下降、そしてパターンの出現を捉えます。それは、私たちの現実を形作る隠されたつながりや相関関係を明らかにし、過去の生き生きとした描写を提供し、未来の一端を垣間見るものです。 時系列分析は単なるツール以上のものです。それは知識と洞察を得るためのゲートウェイであります。時間に関するデータの秘密を解き明かし、生の情報を貴重な洞察に変える力を与え、情報をもとに妥当な決定を下し、リスクを軽減し、新しい機会を活用する手助けをします。 このエキサイティングな冒険に一緒に乗り出し、時系列分析の魅力的な領域に飛び込んでみましょう! 学習目標 時系列分析の概念を紹介し、そのさまざまな分野での重要性を強調し、実際の例を示して、時系列分析の実用的な応用を紹介します。 Pythonとyfinanceライブラリを使用してNetflixの株式データをインポートする方法を実演することで、時系列データを取得し、分析のために準備するための必要な手順を学びます。 最後に、シフト、ローリング、およびリサンプリングなどの時系列分析で使用される重要なPandas関数に焦点を当て、時系列データを効果的に操作および分析するための方法を示します。 この記事は、Data Science Blogathonの一環として公開されました。 時系列分析とは何ですか? 時系列とは、連続的かつ等間隔の時間間隔で収集または記録されたデータのシーケンスです。 時系列分析は、時間によって収集されたデータポイントを分析する統計的技術です。 これには、データの視覚化、統計モデリング、予測方法などの技術が含まれます。 順次データのパターン、トレンド、依存関係を研究し、洞察を抽出し、予測を行うことが含まれます。 時系列データの例 株式市場データ:歴史的な株価を分析してトレンドを特定し、将来の価格を予測する。 天気データ:時間の経過に伴って温度、降水量、その他の変数を研究して、気候パターンを理解する。 経済指標:GDP、インフレ率、失業率を分析して、経済のパフォーマンスを評価する。 売上データ:時間の経過に伴って売上高を調べ、パターンを特定し、将来の売上高を予測する。 ウェブトラフィック:ウェブトラフィックメトリックを分析して、ユーザーの行動を理解し、ウェブサイトのパフォーマンスを最適化する。 時系列の構成要素 時系列の4つの構成要素があります。それらは次のとおりです。…

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

データアナリストの仕事内容はどのように見えますか?
はじめに グローバルなデータ分析市場は、2026年までに年率28.9%で132,903百万ドルに達すると予想されています。データは世界中の企業の強力な支援力となっていますが、データアナリストとしてのキャリアをスタートするのは十分に正当なことです。データアナリストの仕事の説明には、データの収集、クリーニング、調整、翻訳に熟練が求められます。この分野で前進する計画がある場合は、データアナリストの役割と責任、および求職者が職に就くために期待される資格について説明します。 データアナリストとは何ですか? データアナリストは、大量のデータセットを収集、解釈、分析して有益な洞察とトレンドを明らかにします。彼らは統計的および分析的技術を使用してデータを調べ、パターンを特定し、意味のある結論を導き出します。データアナリストは、ビジネスや組織が情報を得て効果的な戦略を開発するのを支援することが重要です。彼らは、売上高、顧客デモグラフィック、ウェブサイトのトラフィック、ソーシャルメディアのエンゲージメントなど、多様なデータソースであるスプレッドシート、統計ソフトウェア、プログラミング言語などのツールを使用します。データ分析、可視化、レポート作成の専門知識を持つことで、データアナリストはビジネスのパフォーマンスを向上させ、データに基づく意思決定を促進します。 データアナリストの主な責任 重要なデータアナリストの責任には、アクション可能な洞察を生成し、意思決定プロセスを促進するためにデータを収集、分析、解釈することが含まれます。現在、データアナリストの仕事の説明の職務は、業界、会社、役割などの特定に基づいて異なる場合があります。 ここでは、異なる文脈で役立つ5つのデータアナリストの役割と責任を紹介します。 1. データの収集と分析 データアナリストの役割には、データベース、スプレッドシート、APIなどからデータを収集することが含まれます。アナリストは、データの正確性と一貫性を確保することが期待されています。さらに、データを分析しやすくするために変換することも含まれる場合があります。 2. データのクリーニングと前処理 分析を行う前に、データアナリストはしばしば生データをクリーニングして前処理する必要があります。これにより、分析に適したデータであることが確認されます。欠落しているデータの処理、データの検証の実行、外れ値の処理など、データクリーニングに使用される技術の熟練度を確保することも重要です。 3. データの探索と可視化 データアナリストの仕事の説明には、統計的技術とデータ可視化ツールの熟練度が必須とされることがよくあります。データの探索と可視化を行うことで、データ内のパターンを特定し、意味のある洞察を導き出すことが不可欠です。したがって、データアナリストは、Excel、SQL、Python、またはRなどのプログラミング言語などのツールを使いこなす必要があります。 4. パターン、トレンド、および洞察の特定 データアナリストの仕事の説明には、数値を精査し、パターン、トレンド、相関関係を探すというタスクが、データアナリストの主な責任として強調されています。統計的手法や分析技術を用いて、専門家は価値のある洞察を抽出するための解釈技術に精通している必要があります。 5. レポートとプレゼンテーションの作成 データアナリストの役割は、データドリブンの洞察や推奨事項を提供することで問題解決を支援することです。データアナリストは、意思決定者やステークホルダーと緊密に協力して、要件を理解し、データ分析に基づいてよりよい意思決定を行うのを支援します。彼らは、実行可能な推奨事項と洞察を提供して、ビジネス戦略を推進し、パフォーマンスを向上させます。 データアナリストのスキル 企業固有のデータアナリストの仕事の説明に基づいて、必要なスキルと資格のリストを作成することが理想的ですが、データアナリストとして競争に勝つためには、技術的な専門知識、分析思考力、強力なコミュニケーションスキルを組み合わせる必要があります。…
言語学習モデルにおけるOpenAIの関数呼び出しの力:包括的なガイド
OpenAIの関数呼び出し機能を使用したデータパイプラインの変換:PostgreSQLとFastAPIを使用した電子メール送信ワークフローの実装
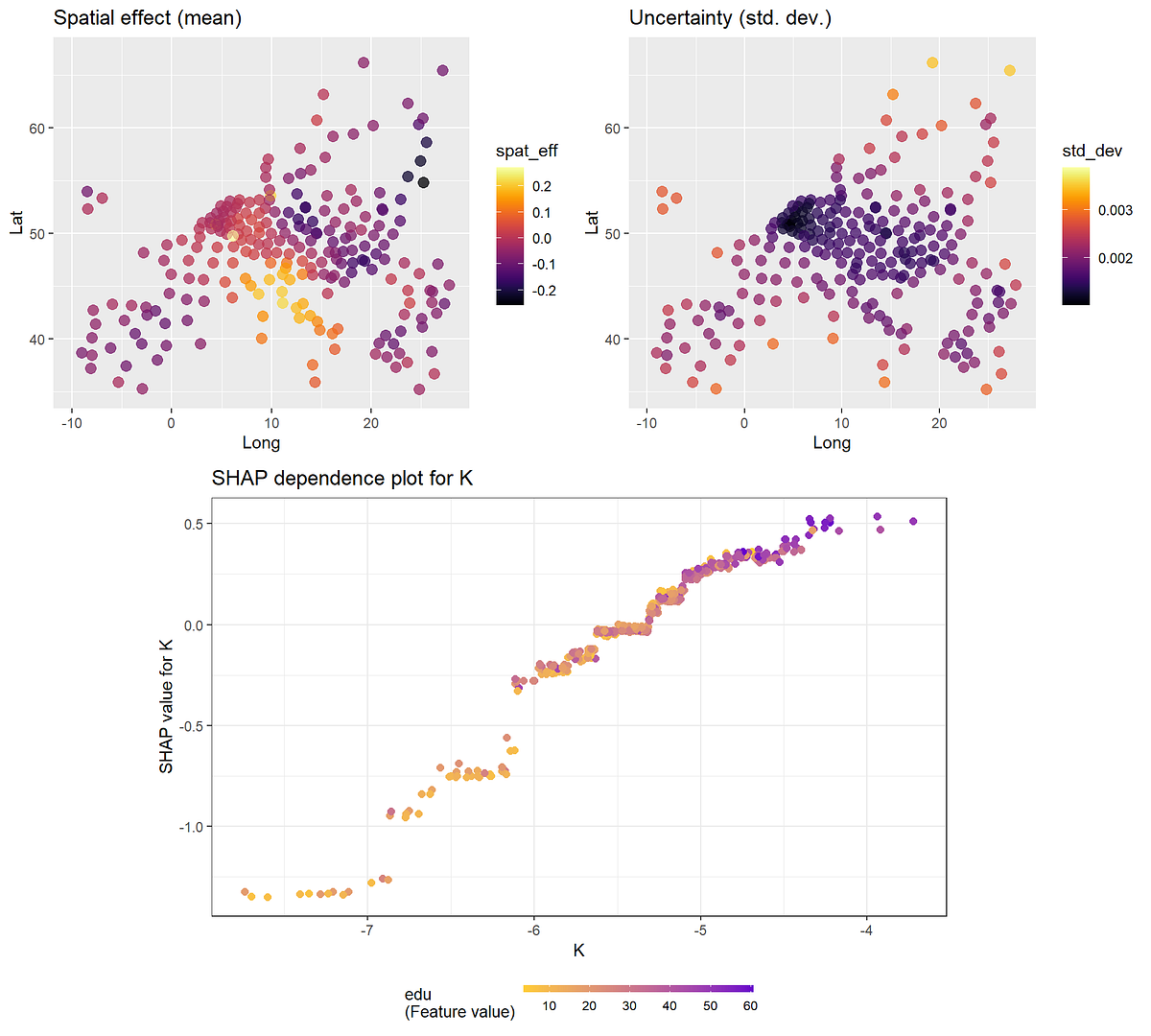
グループ化および空間計量データの混合効果機械学習におけるGPBoost
GPBoostを用いたグループ化されたおよび地域空間計量データの混合効果機械学習 - ヨーロッパのGDPデータを用いたデモ

アテンションメカニズムを利用した時系列予測
はじめに 時系列予測は、金融、気象予測、株式市場分析、リソース計画など、さまざまな分野で重要な役割を果たしています。正確な予測は、企業が情報に基づいた決定を行い、プロセスを最適化し、競争上の優位性を得るのに役立ちます。近年、注意機構が、時系列予測モデルの性能を向上させるための強力なツールとして登場しています。本記事では、注意の概念と、時系列予測の精度を向上させるために注意を利用する方法について探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 時系列予測の理解 注意機構について詳しく説明する前に、まず時系列予測の基礎を簡単に見直してみましょう。時系列は、日々の温度計測値、株価、月次の売上高など、時間の経過とともに収集されたデータポイントの系列から構成されます。時系列予測の目的は、過去の観測値に基づいて将来の値を予測することです。 従来の時系列予測手法、例えば自己回帰和分移動平均(ARIMA)や指数平滑法は、統計的手法や基礎となるデータに関する仮定に依存しています。研究者たちはこれらの手法を広く利用し、合理的な結果を得ていますが、データ内の複雑なパターンや依存関係を捉えることに課題を抱えることがあります。 注意機構とは何か? 人間の認知プロセスに着想を得た注意機構は、深層学習の分野で大きな注目を集めています。機械翻訳の文脈で初めて紹介された後、注意機構は自然言語処理、画像キャプション、そして最近では時系列予測など、様々な分野で広く採用されています。 注意機構の主要なアイデアは、モデルが予測を行うために最も関連性の高い入力シーケンスの特定の部分に焦点を合わせることを可能にすることです。注意は、すべての入力要素を同等に扱うのではなく、関連性に応じて異なる重みや重要度を割り当てることができるようにします。 注意の可視化 注意の仕組みをよりよく理解するために、例を可視化してみましょう。数年にわたって日々の株価を含む時系列データセットを考えます。次の日の株価を予測したいとします。注意機構を適用することで、モデルは、将来の価格に影響を与える可能性が高い、過去の価格の特定のパターンやトレンドに焦点を合わせることができます。 提供された可視化では、各時間ステップが小さな正方形として描かれ、その特定の時間ステップに割り当てられた注意重みが正方形のサイズで示されています。注意機構は、将来の価格を予測するために、関連性が高いと判断された最近の価格により高い重みを割り当てることができることがわかります。 注意に基づく時系列予測モデル 注意機構の理解ができたところで、時系列予測モデルにどのように統合できるかを探ってみましょう。人気のあるアプローチの1つは、注意を再帰型ニューラルネットワーク(RNN)と組み合わせることで、シーケンスモデリングに広く使用されている方法です。 エンコーダ・デコーダアーキテクチャ エンコーダ・デコーダアーキテクチャは、エンコーダとデコーダの2つの主要なコンポーネントから構成されています。過去の入力シーケンスをX = [X1、X2、…、XT]、Xiが時間ステップiの入力を表すようにします。 エンコーダ エンコーダは、入力シーケンスXを処理し、基礎となるパターンと依存関係を捉えます。このアーキテクチャでは、エンコーダは通常、LSTM(長短期記憶)レイヤを使用して実装されます。入力シーケンスXを取り、隠れ状態のシーケンスH = [H1、H2、…、HT]を生成します。各隠れ状態Hiは、時間ステップiの入力のエンコード表現を表します。 H、_= LSTM(X)…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.