Learn more about Search Results This - Page 52

- You may be interested
- Amazon SageMaker、HashiCorp Terraform、...
- FastAPI、AWS Lambda、およびAWS CDKを使...
- 「グローバルリーダーが警告、A.I.は「壊...
- 銀行の苦情に関する架空のデータ
- トップ40+の生成AIツール(2023年10月)
- 「なぜあなたの上司がODSC West 2023にあ...
- 「Amazon SageMakerを使用して、ファルコ...
- 「初心者からニンジャへ:なぜデータサイ...
- 「MIT研究者がLILOを導入:プログラム合成...
- スウィン・トランスフォーマー | モダンな...
- 「13/11から19/11までの週の最も重要なコ...
- RepVGG 構造的再パラメータ化の詳細な説明
- 「AIの画像をどのように保存すべきか?Goo...
- 「Apache Sparkにおけるメモリ管理:ディ...
- 「DiffPoseTalk(デフポーズトーク)をご...

モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
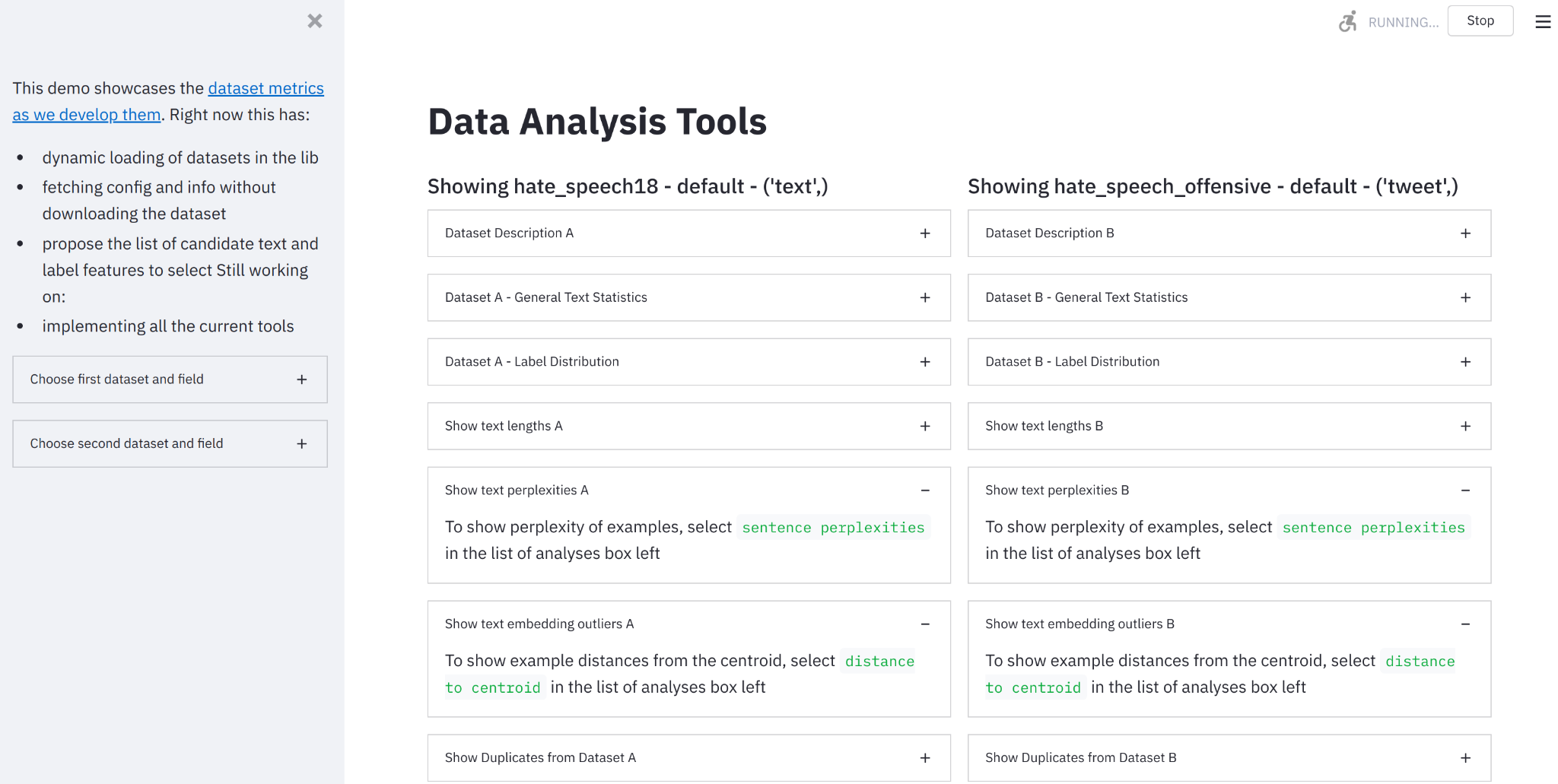
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…
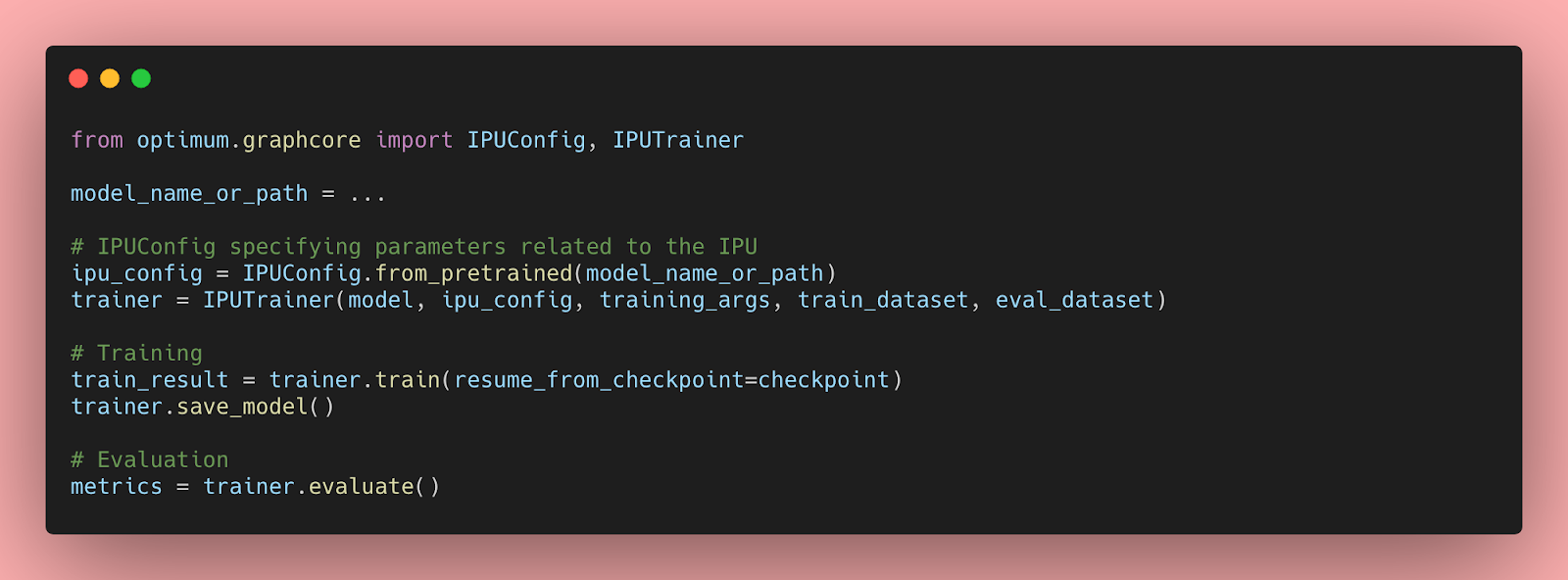
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…

機械学習の専門家 – ルイス・タンストール
🤗 マシンラーニングエキスパートへようこそ – ルイス・タンストール こんにちは、みなさん!マシンラーニングエキスパートへようこそ。私は司会のブリトニー・ミュラーです。今日のゲストはルイス・タンストールさんです。ルイスさんはHugging Faceのマシンラーニングエンジニアで、トランスフォーマーを使ってビジネスプロセスを自動化し、MLOpsの課題を解決するための取り組みを行っています。 ルイスさんは、NLP、トポロジカルデータ解析、時系列の領域でスタートアップや企業向けに機械学習アプリケーションを開発してきました。 ルイスさんは、彼の新しい本、トランスフォーマー、大規模モデルの評価、MLエンジニアがより高速なレイテンシとスループットを目指すための最適化方法などについて話します。 以前は理論物理学者であり、仕事以外ではギターを弾いたり、トレイルランニングをしたり、オープンソースプロジェクトに貢献したりすることが好きです。 この楽しくて素晴らしいエピソードを紹介するのをとても楽しみにしています!ここで私がルイス・タンストールさんとの会話をお届けします。 注:転写はわかりやすい読みやすい体験を提供するために、わずかに修正/再フォーマットされています。 ようこそ、ルイスさん!お忙しい中、私との素晴らしいお仕事についてお話しいただき、本当にありがとうございます! ルイス: ありがとうございます、ブリトニーさん。こちらこそ、ここにいさせていただけて光栄です。 簡単な自己紹介と、Hugging Faceへの経緯について教えていただけますか? ルイス: 私をHugging Faceに導いたものはトランスフォーマーです。2018年、私はスイスのスタートアップでトランスフォーマーを使って仕事をしていました。最初のプロジェクトは、テキストを入力してそのテキスト内の質問に答えを見つけるためのモデルを訓練する質問応答のタスクでした。 当時のライブラリは「pytorch-pretrained-bert」という名前で、いくつかのスクリプトを持つ非常に特化したコードベースでした。私はトランスフォーマーについて何が起こっているのか全くわからず、オリジナルの「Attention Is All You Need」という論文を読んでも理解できませんでした。そこで他の学習リソースを探し始めました。…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…

Hugging Faceハブへ、fastaiさんを歓迎します
ニューラルネットを再びクールじゃなくする…そして共有する Deep Learningのアクセシビリティを高めるために、fast.aiエコシステムは他に類を見ない成果を上げてきました。Hugging Faceの使命は、優れた機械学習を民主化することです。機械学習へのアクセスの排他性、事前学習済みモデルを過去のものとし、この素晴らしい領域をさらに推進しましょう。 fastaiは、PyTorchとPythonを活用して、テキスト、画像、表形式のデータに対して最新の出力を備えた高速かつ正確なニューラルネットワークをトレーニングするためのハイレベルなコンポーネントを提供するオープンソースのDeep Learningライブラリです。ただし、fast.aiは単なるライブラリ以上のものです。それはオープンソースの貢献者とニューラルネットワークの学習に取り組む人々の繁栄するエコシステムに成長しました。いくつかの例として、彼らの書籍やコースをチェックしてみてください。fast.aiのDiscordやフォーラムに参加してください。彼らのコミュニティに参加することで、確実に学びが得られます! これら全ての理由から(この記事の執筆者はfast.aiのコースのおかげで自分の旅をスタートさせました)、私たちは誇りを持ってお知らせします。fastaiのプラクティショナーは、Pythonの一行でモデルをHugging Face Hubに共有・アップロードすることができるようになりました。 👉 この記事では、fastaiとHubの統合について紹介します。さらに、このチュートリアルをColabノートブックとして開くこともできます。 fast.aiコミュニティ、特にJeremy Howard、Wayde Gilliam、Zach Muellerにフィードバックをいただいたことに感謝します 🤗。このブログは、fastaiドキュメントのHugging Face Hubセクションに強く触発されています。 Hubに共有する理由 Hubは、モデル、データセット、MLデモを共有・探索できる中央プラットフォームです。最も広範なオープンソースのモデル、データセット、デモのコレクションを提供しています。 Hubで共有することで、あなたのfastaiモデルの影響力を広げ、他の人がダウンロードして探索できるようにします。また、fastaiモデルを転移学習に利用することもできます。他の誰かのモデルをタスクの基礎として読み込むことができます。 誰でも、hf.co/modelsのウェブページでfastaiライブラリをフィルタリングすることで、Hubの全てのfastaiモデルにアクセスできます。以下の画像を参照してください。 広範なコミュニティへの無料モデルホスティングと露出に加えて、Hubにはgitに基づいたバージョン管理(大容量ファイルの場合はgit-lfs)や、発見性と再現性のためのモデルカードも組み込まれています。Hubのナビゲーションについての詳細は、この紹介を参照してください。 Hugging…

機械学習の専門家 – Sasha Luccioni
🤗 マシンラーニングエキスパートへようこそ – サーシャ・ルッチョーニ 🚀 サーシャのようなMLエキスパートがあなたのMLロードマップを加速する方法に興味がある場合は、hf.co/supportを訪れてください。 こんにちは、友達たち!マシンラーニングエキスパートへようこそ。私は司会者のブリトニー・ミュラーで、今日のゲストはサーシャ・ルッチョーニです。サーシャは、Hugging Faceで研究科学者として、機械学習モデルとデータセットの倫理的・社会的影響に取り組んでいます。 サーシャはまた、Big Science WorkshopのCarbon Footprint WGの共同議長、WiMLの理事、そして気候危機に機械学習を適用する意義のある活動を促進するClimate Change AI(CCAI)組織の創設メンバーでもあります。 サーシャがメールの炭素フットプリントを計測する方法、地元のスープキッチンが機械学習の力を活用するのをどのように手助けしたか、そして意味と創造性が彼女の仕事を支える方法についてお話しいただきます。 この素晴らしいエピソードを紹介するのをとても楽しみにしています!以下がサーシャ・ルッチョーニとの私の対話です: 注:転記はわかりやすい読み物を提供するためにわずかに修正/書式設定されています。 今日参加していただき、本当にありがとうございます。私たちはあなたが来てくれたことを非常に嬉しく思っています! サーシャ: 私もここにいることを本当に嬉しく思っています。 直接本題に入りますが、あなたのバックグラウンドとHugging Faceへの道を教えていただけますか? サーシャ:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.