Learn more about Search Results 使用方法 - Page 52

- You may be interested
- キャンドル:Rustでのミニマリストな機械学習
- 「分析的に成熟した組織(AMO)の構築」
- 「MatFormerをご紹介します:プラットフォ...
- 「AlphaFold 2の2億モデルによって明らか...
- 「モデルの解釈性のためのPFIに深く入り込...
- 「5分でPythonとTkinterを使用してシンプ...
- VoAGIニュース、9月13日:5つのステップで...
- 「LangChainを使用して、強力な大規模言語...
- 「中国、新たな規制提案でAIデータのセキ...
- 「JAXとHaikuを使用してゼロからTransform...
- 「Amazon SageMakerのトレーニングワーク...
- このAIニュースレターは、あなたが必要と...
- 中国の研究者がiTransformerを提案:時間...
- 十代の夢:コンピュータ科学の専攻を志す...
- シートベルトを締めてください:ファルコ...

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…

🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
イントロダクション TPUトレーニングは有用なスキルです:TPUポッドは高性能で非常にスケーラブルであり、数千万から数百億のパラメータまで、どんなスケールでもモデルをトレーニングすることが容易です。GoogleのPaLMモデル(5000億パラメータ以上!)は完全にTPUポッドでトレーニングされました。 以前、TensorFlowを使用した小規模なTPUトレーニングと、TPUでモデルを動作させるために理解する必要がある基本的なコンセプトを紹介するチュートリアルとColabの例を作成しました。今回は、TensorFlowとTPUを使用してマスクされた言語モデルをゼロからトレーニングするためのすべての手順、トークナイザのトレーニングとデータセットの準備から最終的なモデルのトレーニングとアップロードまでを詳しく説明します。これはColabだけでなく、専用のTPUノード(またはVM)が必要なタスクであり、そこに焦点を当てます。 Colabの例と同様に、TensorFlowの非常にクリーンなTPUサポートであるXLAとTPUStrategyを活用しています。また、🤗 Transformers内のほとんどのTensorFlowモデルが完全にXLA互換であるという利点もあります。そのため、TPU上で実行するために必要な作業はほとんどありません。 ただし、この例はColabの例とは異なり、実際のトレーニングランに近いスケーラブルな例です。デフォルトではBERTサイズのモデルしか使用していませんが、いくつかの設定オプションを変更することで、コードをより大きなモデルとより強力なTPUポッドスライスに拡張することができます。 動機 なぜ今このガイドを書いているのでしょうか?実際、🤗 Transformersは何年もの間TensorFlowをサポートしてきましたが、これらのモデルをTPUでトレーニングすることはコミュニティにとって主要な問題でした。これは以下の理由によるものです: 多くのモデルがXLA互換ではなかった データコレクターがネイティブのTF操作を使用していなかった 私たちはXLAが将来の技術であると考えています。それはJAXのコアコンパイラであり、TensorFlowでの一流のサポートを受けており、PyTorchからも使用できます。そのため、私たちはコードベースをXLA互換にするために大きな取り組みを行い、XLAとTPUの互換性に立ちはだかるその他の障害を取り除きました。これにより、ユーザーは私たちのほとんどのTensorFlowモデルをTPUで煩わずにトレーニングできるはずです。 現在のLLM(言語モデル)と生成AIの最近の重要な進歩により、モデルのトレーニングに対する一般の関心が高まり、最新のGPUにアクセスすることが非常に困難になりました。TPUでのトレーニング方法を知っていると、超高性能な計算ハードウェアへのアクセスする別の方法を手に入れることができます。それは、eBayで最後のH100の入札戦に敗れてデスクで醜い泣きをするよりもずっと品位があります。あなたにはもっと良いものがふさわしいのです。そして経験から言えることですが、TPUでのトレーニングに慣れると、戻りたくなくなるかもしれません。 予想されること WikiTextデータセット(v1)を使用してRoBERTa(ベースモデル)をゼロからトレーニングします。モデルのトレーニングだけでなく、トークナイザをトレーニングし、データをトークン化してTFRecord形式でGoogle Cloud Storageにアップロードし、TPUトレーニングでアクセスできるようにします。コードはこのディレクトリにあります。ある種の人にとっては、このブログ投稿の残りをスキップして、コードに直接ジャンプすることもできます。ただし、しばらくお付き合いいただければ、コードベースのいくつかのキーポイントについて詳しく見ていきます。 ここで紹介するアイデアの多くは、私たちのColabの例でも触れられていましたが、それらをすべて組み合わせて実際に動作するフルエンドツーエンドの例をユーザーに示したかったのです。次の図は、🤗 Transformersを使用した言語モデルのトレーニングに関わる手順の概要を図解したものです。TensorFlowとTPUを使用しています。 データの取得とトークナイザのトレーニング 先述のように、WikiTextデータセット(v1)を使用しました。データセットの詳細については、Hugging Face Hubのデータセットページにアクセスして調べることができます。 データセットは既に互換性のある形式でHubに利用可能なので、🤗 datasetsを使用して簡単にロードして操作することができます。ただし、この例ではトークナイザをゼロから学習しているため、以下のような手順を踏んでいます:…

StarCoder:コードのための最先端のLLM
StarCoderの紹介 StarCoderとStarCoderBaseは、GitHubからの許可を得たデータを使用してトレーニングされた大規模な言語モデルです。これらのモデルは、80以上のプログラミング言語、Gitのコミット、GitHubの課題、Jupyterノートブックなど、様々な情報源からデータを取得しています。LLaMAと同様に、私たちは1兆トークンのために約15兆パラメータのモデルをトレーニングしました。また、35兆のPythonトークンに対してStarCoderBaseモデルを微調整し、新しいモデルであるStarCoderと呼びます。 StarCoderBaseは、人気のあるプログラミングベンチマークにおいて既存のオープンなコードモデルよりも優れたパフォーマンスを発揮し、GitHub Copilotの初期バージョンで使用された「code-cushman-001」といったクローズドモデルとも匹敵する結果を示しました。StarCoderモデルは、8,000以上のトークンのコンテキスト長を持つため、他のオープンなLLMよりも多くの入力を処理することができます。これにより、さまざまな興味深いアプリケーションが可能となります。例えば、StarCoderモデルに対して対話のシリーズをプロンプトとして与えることで、技術アシスタントとしての機能を果たすことができます。さらに、これらのモデルはコードの自動補完、指示に基づいたコードの変更、コードスニペットの自然言語による説明などにも使用することができます。私たちは、改善されたPIIの削除パイプライン、新しい帰属追跡ツールなど、安全なオープンモデルのリリースに向けていくつかの重要な手順を踏んでいます。また、StarCoderは改良されたOpenRAILライセンスのもとで一般に公開されています。この更新されたライセンスにより、企業がモデルを製品に統合するプロセスが簡素化されます。StarCoderモデルの強力なパフォーマンスにより、コミュニティは自分たちのユースケースや製品に適応させるための堅固な基盤としてこれを活用することができると考えています。 評価 私たちはStarCoderといくつかの類似モデルについて、さまざまなベンチマークで徹底的に評価を行いました。人気のあるPythonベンチマークであるHumanEvalでは、関数のシグネチャとドキュメント文字列に基づいてモデルが関数を完成させることができるかどうかをテストしました。StarCoderとStarCoderBaseは、PaLM、LaMDA、LLaMAなどの最大のモデルを上回るパフォーマンスを発揮しましたが、それらよりも遥かに小さなサイズであるという特徴も持っています。また、CodeGen-16B-MonoやOpenAIのcode-cushman-001(12B)モデルよりも優れた結果を示しました。私たちはまた、モデルの失敗例として、通常は練習の一部として使用されるため、# Solution hereというコードを生成することがあることに気付きました。実際の解決策を生成させるために、プロンプトとして<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exerciseを追加しました。これにより、StarCoderのHumanEvalスコアは34%から40%以上に向上し、オープンモデルの最新のベンチマーク結果を更新しました。CodeGenとStarCoderBaseに対してもこのプロンプトを試しましたが、あまり違いは観察されませんでした。 StarCoderの興味深い特徴の一つは、多言語対応であることです。そのため、MultiPL-Eという多言語の拡張を使用して評価を行いました。その結果、StarCoderは多くの言語においてcode-cushman-001と匹敵または優れたパフォーマンスを発揮することがわかりました。また、DS-1000というデータサイエンスのベンチマークでも、StarCoderは他のオープンアクセスモデルを圧倒する結果を示しました。しかし、コード補完以外にもモデルができることを見てみましょう! 技術アシスタント 徹底的な評価の結果、StarCoderはコードの記述に非常に優れていることがわかりました。しかし、ドキュメンテーションやGitHubの課題などの情報を大量に学習しているため、技術アシスタントとして使用できるかどうかもテストしたかったのです。AnthropicのHHHプロンプトに触発されて、私たちはTech Assistant Promptを作成しました。驚くべきことに、プロンプトだけでモデルは技術アシスタントとして機能し、プログラミングに関連する要求に答えることができます! トレーニングデータ このモデルは、The…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

Hugging Face Hubへ、fastText をようこそお迎えください
fastTextは、テキストの表現と分類の効率的な学習のためのライブラリです。Meta AIによって2016年にオープンソース化され、fastTextは過去数十年間の自然言語処理と機械学習において影響力のあるキーワードを統合しています。具体的には、文を単語の袋とn-gramの袋を使用して表現し、サブワード情報を利用し、クラス間で情報を共有するための隠れた表現を使用します。 計算を高速化するために、fastTextはクラスの不均衡な分布を活用した階層的なソフトマックスを使用します。これらの技術により、ユーザーはテキストの表現と分類のためのスケーラブルなソリューションを提供します。 Hugging Faceは、現在、157か国のすべての言語と最新の言語識別モデルの公式ミラーをホストしています。これは、Hugging Faceを使用することで、数回のコマンドでモデルを簡単にダウンロードして使用できることを意味します。 モデルの検索 157か国の言語の単語ベクトルと言語識別モデルは、Meta AIのorgで見つけることができます。例えば、こちらで英語の単語ベクトルのモデルページを見つけることができます。また、こちらで言語識別モデルを見つけることができます。 ウィジェット この統合には、テキスト分類と特徴抽出のウィジェットのサポートが含まれています。こちらで言語識別ウィジェットを試してみることができます。また、こちらで特徴抽出ウィジェットを試してみることができます。 使用方法 以下は、事前学習済みのベクトルを読み込んで使用する方法です: >>> import fasttext >>> from huggingface_hub import hf_hub_download >>> model_path =…

ギャラリー、図書館、アーカイブ、博物館向けのHugging Face Hub
ギャラリー、図書館、アーカイブ、博物館のためのハギングフェイスハブ ハギングフェイスハブとは何ですか? Hugging Faceは、高品質な機械学習を誰にでもアクセス可能にすることを目指しています。この目標は、広く使われているTransformersライブラリなどのオープンソースのコードライブラリを開発すること、無料のコースを提供すること、そしてHugging Faceハブを提供することなど、さまざまな方法で追求されています。 Hugging Faceハブは、人々が機械学習モデル、データセット、デモを共有しアクセスできる中央リポジトリです。ハブには19万以上の機械学習モデル、3万3000以上のデータセット、10万以上の機械学習アプリケーションとデモがホストされています。これらのモデルは、事前学習済みの言語モデル、テキスト、画像、音声分類モデル、物体検出モデル、さまざまな生成モデルなど、さまざまなタスクをカバーしています。 ハブにホストされているモデル、データセット、デモは、さまざまなドメインと言語をカバーしており、ハブを通じて利用できる範囲を拡大するための定期的なコミュニティの取り組みが行われています。このブログ記事は、ギャラリー、図書館、アーカイブ、博物館(GLAM)セクターで働く人々がハギングフェイスハブをどのように利用して貢献できるかを理解することを目的としています。 記事全体を読むか、最も関連のあるセクションにジャンプすることができます! ハブが何か分からない場合は、「ハギングフェイスハブとは何ですか?」から始めてください。 ハブで機械学習モデルを見つける方法を知りたい場合は、「ハギングフェイスハブの使用方法:ハブで関連するモデルを見つける方法」から始めてください。 ハブでGLAMデータセットを共有する方法を知りたい場合は、「ウォークスルー:GLAMデータセットをハブに追加する方法」から始めてください。 いくつかの例を見たい場合は、「ハギングフェイスハブの使用例」をチェックしてください。 ハギングフェイスハブで何を見つけることができますか? モデル Hugging Faceハブは、さまざまなタスクとドメインをカバーする機械学習モデルへのアクセスを提供しています。多くの機械学習ライブラリがHugging Faceハブとの統合を持っており、これらのライブラリを介して直接モデルを使用したりハブに共有したりすることができます。 データセット Hugging Faceハブには3万以上のデータセットがあります。これらのデータセットには、テキスト、画像、音声、マルチモーダルなど、さまざまなドメインとモダリティがカバーされています。これらのデータセットは、機械学習モデルのトレーニングや評価に価値があります。 スペース Hugging Face…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…
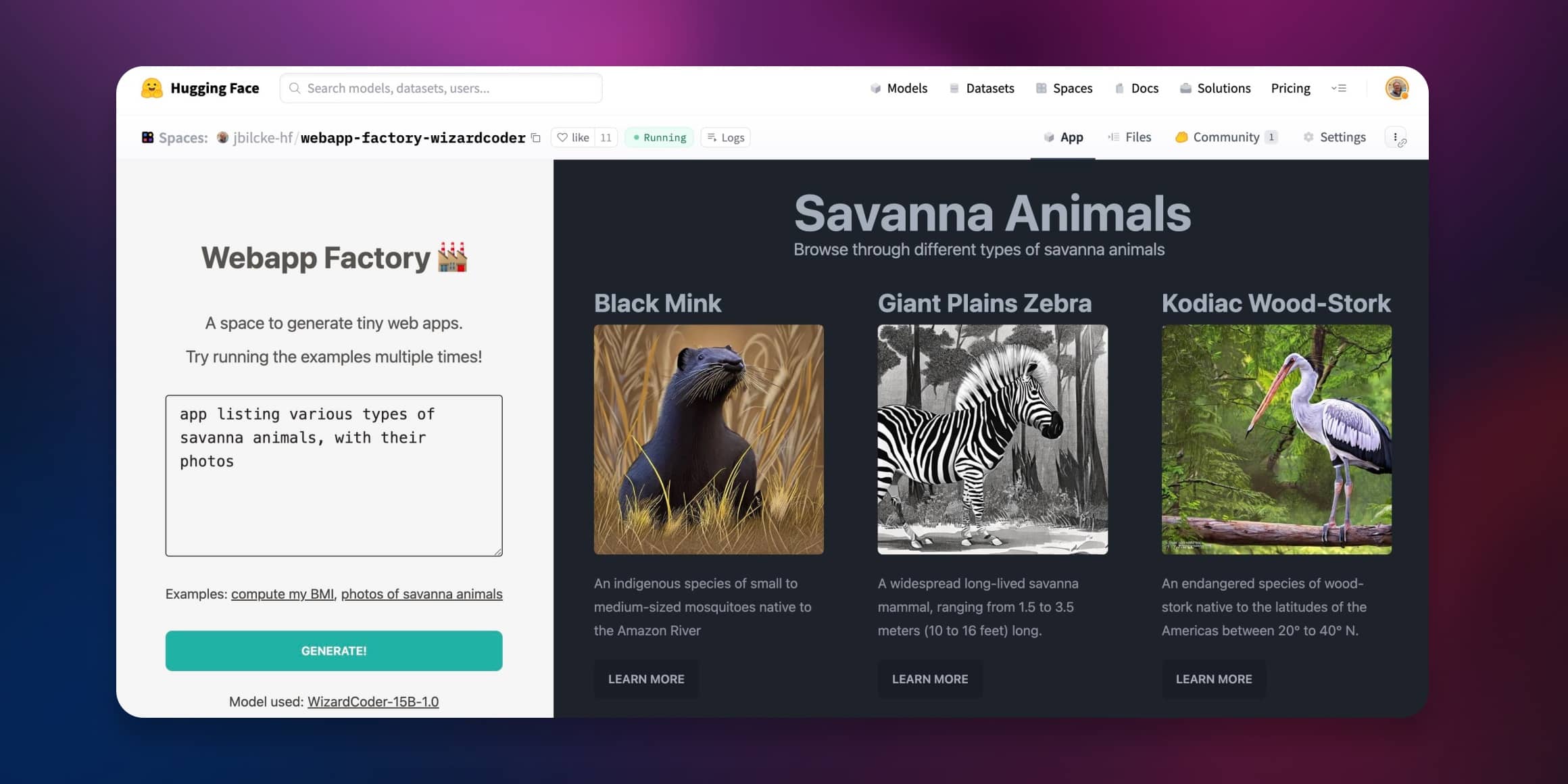
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

Pythonを使用した画像処理の紹介
当シリーズの第2エピソードの第3部へようこそ!前のパートでは、フーリエ変換とホワイトバランス技術について説明しましたが、今回は...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.