Learn more about Search Results リポジトリ - Page 52

- You may be interested
- 「LLMを評価するためのより良い方法」
- 多変量ガウス分布による異常検知の基本
- 高パフォーマンスなリアルタイムデータモ...
- ボードゲームをプレイするためのAIの教育
- 気候変動との戦いをリードする6人の女性
- コンテンツモデレーションからゼロショッ...
- Rendered.aiは、合成データの生成にNVIDIA...
- ExcelとPower BI – 意思決定におい...
- テキストから画像合成を革新する:UCバー...
- 高度なRAGテクニック:イラスト入り概要
- スターバックスのコーヒー代で、自分自身...
- 「GoogleのRealLife AIモデルは魔法のよう...
- Google DeepMindは、画期的なAI音楽生成器...
- 「AIが航空会社のコントレイルによる気候...
- スタンフォード大学の研究者たちは、スペ...

「ROUGEメトリクス:大規模言語モデルにおける要約の評価」
「従来のモデルにおいて使用してきた指標であるAccuracy、F1スコア、またはRecallなどは、生成モデルの結果を評価するのに役立ちませんこれらのモデルでは、...」
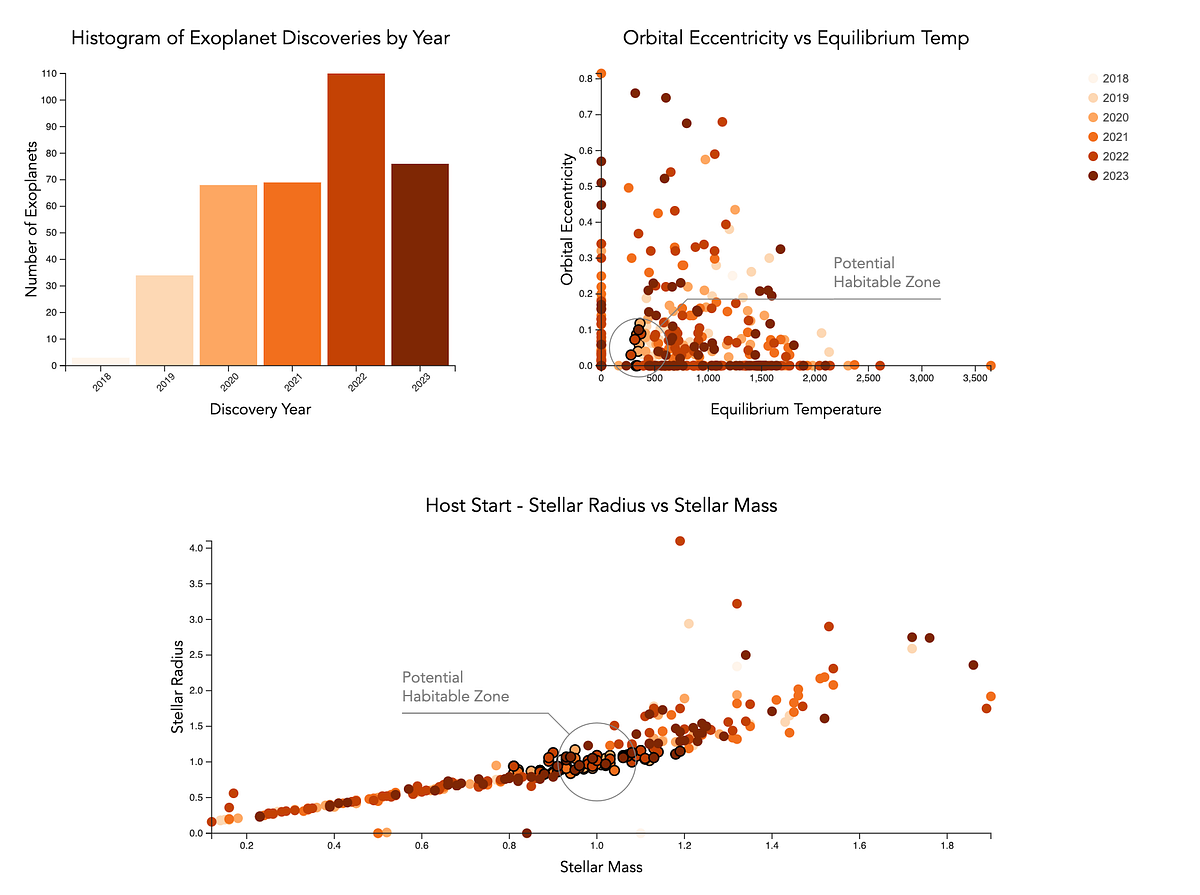
「説明的なデータの可視化の技術を取り入れる」
データの可視化は、読者に複雑なデータを表現するための強力なツールですさらに一歩進んで、ナラティブの可視化は情報を一連の物語に変換するデータストーリーを作り出すことを可能にします…

「Declarai、FastAPI、およびStreamlitを使用してLLMチャットアプリケーションを展開する」
2022年10月、私が大規模言語モデル(LLM)の実験を始めたとき、最初の傾向はテキストの補完、分類、NER、およびその他のNLP関連の領域を探索することでしたしかし、...

「2023年の市場で利用可能な15の最高のETLツール」
はじめに データストアの時代において、対照的なソースからデータを一つの統合されたデータベースに組み込む必要性があります。そのためには、親元のソースからデータを抽出し、変換して結合し、そして統合されたデータベースにロードする必要があります(ETL)。このような状況において、ETLツールは重要な役割を果たします。15の最高のETLツールは、一貫したデータの抽出、変換、情報のロードを提供し、企業がデータの効率性を向上させることを可能にします。仮想世界2023年には、さまざまなデータ連携のニーズを満たすために多くのETLツールが存在します。 ETLとは何ですか? ETLとは、データの抽出、変換、結合、そして最終的な協調データベースへのデータのロードを意味します。ソース構造から最終的な目的地までのデータを管理し統合するために使用されるシステムであり、ETLは一般的にデータのリポジトリとして機能します。 ETLツールとは何ですか? ETLツールは、データの統合とデータウェアハウジングにおいてETLの手法を自動化するために設計されたソフトウェアプログラムです。これらのツールは、データの移動と操作機能の取り扱いと最適化において重要な役割を果たします。これらのツールは通常、以下の機能を提供します。 データの抽出 変換 ロード マッピング ワークフローの自動化 クレンジングと検証 監視とログ記録 スケーラビリティとパフォーマンス 市場で利用可能なETLツールの種類は何ですか? ETLツールは、その機能や提供される目的によってさまざまな区分に分類されます。 ApacheなどのオープンソースのETLは、最も広く認識されているツールであり、無料で利用可能であり、ユーザーベースの特定の要件に合わせてカスタマイズされます。 上位バージョンのETLツールは商用セグメントをカバーし、ソフトウェア企業によってライセンスされ、高度な機能とカスタマーサポート機能を提供します。 カスタムETLソリューションには、プログラミング言語、フレームワーク、およびライブラリを使用して特定の要求に合わせてカスタマイズされたETLコマンドを開発するグループが含まれます。 2023年に使用する最高のETLツール15選 Integrate. Io Integrate.Ioは、データの統合、変換、ローディングの手法を簡素化する最高のETLツールの一つです。さまざまなデータソースを効果的に接続し、データを変換し、目的地にロードするための包括的なソリューションを企業に提供します。 特徴…

「PythonとMatplotlibを使用して目を引く国別ランキングを作成する方法」
こんにちは、そしてこのチュートリアルへようこそPythonとMatplotlibを使用して、上記のグラフを作成する方法を教えますこのデータ可視化の魅力は、その清潔で美しい方法で...

「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
Amazon Redshiftは、一日にエクサバイトのデータを分析するために数万人の顧客に利用されている、最も人気のあるクラウドデータウェアハウスです多くのプラクティショナーは、Amazon SageMakerを使用して、完全に管理されたMLサービスであるAmazon Redshiftデータセットを規模拡大して機械学習(ML)を行うために、オフラインで機能を開発する要件を持っています

LangChain + Streamlit + Llama ローカルマシンに会話型AIをもたらす
「オープンソースのLLMsとLangChainを統合して、無料の生成型質問応答を実現します(APIキーは必要ありません)」

「プロセスマイニングとデジタルトランスフォーメーションによる産業4.0における業務の効率化の実現」
「業界に関係なく、デジタル技術は組織の間でますます人気を集めており、業績向上、収益成長、持続可能性の実現に向けて活用されています」

「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
大規模言語モデル(LLM)の使いやすさと全体的なパフォーマンスは、指示を介して提供されるさまざまな言語タスク(指示チューニング)によって向上できることが示されています。視覚、聴覚、多言語データでトレーニングされたモデルは、すべて指示チューニングのパラダイムでうまく機能しています。 コード学習マシンは、研究者によってコーディングの方法を教えられます。コードコメントを使用してCode LLMが望ましいコードを生成するように間接的に指示することは可能ですが、望ましい結果が自然言語の場合には不安定で失敗します。Code LLMの操作性を向上させ、適用範囲を広げるためには、明示的な指示によるチューニングが行われる必要があります。 研究者は、制約のあるライセンスを持つデータを使用せずに、オープンソースモデルを使用して合成データを生成することを好みます。彼らは、次の4つの一般的なコード指示データベースを比較しています: xP3x:広く使用されているコードベンチマークからの結果をまとめたもの lax Code LLM:研究者による独立したデータ生成を可能にするもの OASST:主に言語情報を保持するリポジトリで、コーディング例は最小限です 新しいGitコミットの4TBのデータセットであるCOMMITPACK 研究者の貢献 事前トレーニングでは、350の異なるプログラミング言語で書かれた4テラバイト(TB)のコミットコードを許可ライセンスの下で使用できます。チューニングでは、高品質なコード指示を含むフィルタリングされたバリアントのCOMMITPACKにアクセスできます。 コードLLMの一般化ベンチマーク(HUMANEVALPACK)は、6つのプログラミング言語(Python、JavaScript、Java、Go、C++、およびRust)と3つのシナリオ(コード修復、コード説明、コード合成)に対して行われます。 最も寛大なCode LLMはOCTOCODERとOCTOGEEXです。 研究者は、データセットの基礎としてGitHubのコミットのアクションダンプをGoogle BigQueryで使用しています。コミットメッセージが非常に具体的であり、多くのファイルを扱うことから追加の複雑さを回避するために、品質フィルターを複数適用し、商業的に利用可能なライセンスをフィルタリングし、複数のファイルに影響を及ぼすすべてのコミットを削除します。影響を受けるGitHubソースコードファイルは、フィルタリングされた情報を使用してコミット前後に抽出されます。 自然言語(NL)の応答を必要とするタスクの場合、指示チューニングLLMの入力は、NL指示とオプションのNLコンテキストです。コードデータで指示をチューニングする場合、コードは入力のみ、出力のみ、またはNL指示と共に入力と出力の両方に含まれる場合があります。ほとんどの既存のベンチマークはコード合成のバリアントに焦点を当てていますが、顧客はすべての3つのケースでモデルを使用したい場合があります。そのため、6つの言語の3つの入出力の順列が、コード合成ベンチマークHumanEvalに含まれるようになりました。 3つの評価状況すべてで、OCTOCODERはすべての他の許可モデルを大幅に上回っています。OCTOGEEXは、ベンチマーク化されたモデルの中で最も少ないパラメーターを持っており、60億ですが、それでも他の許可されたCode LLMに比べて最も優れた結果を達成しています。GPT-4は他のモデルと比較して最も高いパフォーマンスを発揮しています。他のモデルよりも大きなモデルである可能性がありますが、GPT-4はクローズドソースです。 コード、モデル、データなど、すべてはhttps://github.com/bigcode-project/octopackで見つけることができます。 まとめると、大規模言語モデル(LLM)は、指示に基づいて細かくチューニングされることで、さまざまな自然言語タスクでより優れたパフォーマンスを発揮することができます。研究者は、コーディングを使用して人間の指示を細かくチューニングし、Gitコミットの固有の構造を使用してコード変更と人間のガイダンスをペアにします。350の異なる言語からの4テラバイトのGitコミットはCOMMITPACKにまとめられています。16Bのパラメーターを持つStarCoderモデルでは、COMMITPACKを他の自然言語および合成コード指示と比較しています。HumanEval Pythonテストでは、OpenAIの出力でトレーニングされていないモデルの中で最新のパフォーマンスを実現しています。さらに、Python、JavaScript、Java、Go、C++、およびRustの6つの追加のプログラミング言語と、Code…

「Tabnine」は、ベータ版のエンタープライズグレードのコード中心のチャットアプリケーション「Tabnine Chat」を導入しましたこれにより、開発者は自然言語を使用してTabnineのAIモデルと対話することができます
I had trouble accessing your link so I’m going to try to continue without it. Tabnineは、そのベータ版であるTabnineチャットを含む、AIパワードのコード補完ツールに新機能を発表しました。これは、開発者の統合開発環境(IDE)とシームレスに統合できるエンタープライズグレードのコード中心のアプリケーションです。このアプリケーションは、説明可能な既存のコードの使用、コードリポジトリの検索、自然言語の仕様に基づいた新しいコードの生成などの機能を拡張します。Tabnineチャットの主なハイライトの1つは、セキュリティとコンプライアンスへの強い焦点です。 この機能は、さまざまなエンタープライズの要件に対応し、プライベートなコードベース、許可されたオープンソースコード、およびスタックオーバーフローのクエリを保護します。モデルは許可されたライセンスのオープンソースコードのみでトレーニングされており、コードベース情報に関する懸念が排除されています。Tabnineチャットのフロントエンドは、Reactアプリケーションであり、現在はVSコードとJetBrains IDEで利用可能であり、すべてのプログラミング言語をサポートしています。 いくつかの特徴がその重要性を強調しています: セキュリティとコンプライアンス:Tabnine環境は、コードのプライバシーとセキュリティを確保します。仮想プライベートクラウドまたはオンプレミスのセットアップを使用した分離された展開環境を容易にし、安全性と機密性を優先します。 コンテキストの統合:TabnineチャットはIDE内で動作するため、開発者の進行中のコードと統合します。 リポジトリの統合:Tabnineエンタープライズユーザーは、このアプリケーションにリポジトリをリンクすることができます。内部API、ライブラリ、およびサービスの大規模なセットを持つ組織は、内部リポジトリをTabnineチャットに接続することで生産性を向上させることができます。 Tabnineチャットのベータフェーズの到来により、開発者はコーディングの変革の最中にいます。開発者とコードの間でシームレスな会話を実現するパイオニアとして、Tabnineチャットが際立っています。近い将来、Tabnineエンタープライズおよびプロユーザーへのさらなる拡大により、高度なコーディングインタラクションに対する興奮が生まれます。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.