Learn more about Search Results This - Page 51

- You may be interested
- 推測的なサンプリング—直感的かつ徹底的に...
- 「Streamlit、OpenAI、およびElasticsearc...
- 「GANが人工的なセレブリティのアイデンテ...
- 「OpenAIが大企業向けのChatGPTバージョン...
- 「ChatGPTのような大規模言語モデルによる...
- 「ロボットが外科医よりも正確に眼球の裏...
- 「Jupyter AIに会おう:マジックコマンド...
- 「LLM製品を開発するのは難しい – ...
- Amazon Lexのチャットボット開発ライフサ...
- オープンAIは、開発者のアリーナでより大...
- Google研究者がAudioPaLMを導入:音声技術...
- アラゴンAIレビュー:2023年における究極...
- キャッシング生成的LLMs | APIコストの節約
- マイクロソフトの研究者は、テキスト重視...
- 「PyrOSM Open Street Mapデータとの作業」

「データサイエンスの役割に関するGoogleのトップ50のインタビュー質問」
イントロダクション Googleでのキャリアを手に入れるためのコードを解読することは、多くのデータサイエンティスト志望者にとっての夢です。しかし、厳しいデータサイエンスの面接プロセスをクリアするにはどうすればよいのでしょうか?面接で成功するために、機械学習、統計学、プロダクトセンス、行動面をカバーするトップ50のGoogleのインタビュー質問の包括的なリストを作成しました。これらの質問に慣れて、回答の練習をしてください。これにより、面接官に印象を与え、Googleでのポジションを確保する可能性が高まります。 データサイエンスのGoogle面接プロセス Googleのデータサイエンティストの面接を通過することは、あなたのスキルと能力を評価するエキサイティングな旅です。このプロセスには、データサイエンス、問題解決、コーディング、統計学、コミュニケーションなど、さまざまなラウンドが含まれています。以下は、あなたが期待できる内容の概要です: ステージ 説明 応募の提出 Googleのキャリアウェブサイトを通じて、採用プロセスを開始するために応募と履歴書を提出します。 テクニカルな電話スクリーン 選考された場合、コーディングスキル、統計学の知識、データ分析の経験を評価するためにテクニカルな電話スクリーンが行われます。 オンサイト面接 成功した候補者は、通常、データサイエンティストや技術的な専門家との複数のラウンドからなるオンサイト面接に進みます。これらの面接では、データ分析、アルゴリズム、統計学、機械学習の概念など、より深く掘り下げたトピックについて話し合います。 コーディングと分析の課題 プログラミングスキルを評価するためにコーディングの課題に取り組み、データから洞察を抽出する能力を評価するために分析の課題に直面します。 システム設計と行動面の面接 一部の面接ではシステム設計に焦点を当て、スケーラブルなデータ処理や分析システムの設計を期待されることがあります。また、行動面の面接では、チームワーク、コミュニケーション、問題解決のアプローチを評価します。 採用委員会の審査 面接のフィードバックは採用委員会によって審査され、最終的な採用の決定が行われます。 Googleデータサイエンティストになる方法についての詳細な応募と面接のプロセスについては、当社の記事をご覧ください! データサイエンスの役職に関するトップ50のGoogleインタビューの質問と回答をまとめました。 データサイエンスのためのトップ50のGoogleインタビュー質問 機械学習、統計学、コーディングなどをカバーするトップ50のインタビュー質問の包括的なリストで、Googleのデータサイエンスの面接に備えてください。これらの質問をマスターし、あなたの専門知識を示して、Googleでのポジションを確保しましょう。 Googleの機械学習とAIに関するインタビューの質問 1.…

「即興演劇処方箋:アナリティクス実践者が変革を実現するために即興演劇を活用する方法」
「この記事はWGUのJoe Deryによって最初に掲載されました許可を得て再投稿されました現在のデータ駆動型の世界では、分析の専門家である場合、技術的な専門知識にのみ頼るだけでは十分ではありません正確なモデルの構築や最新のアルゴリズムの実装は価値がありますが、それだけが重要なことではありません...」

「TransformersとTokenizersを使用して、ゼロから新しい言語モデルを訓練する方法」
ここ数か月間で、私たちはtransformersとtokenizersライブラリにいくつかの改良を加え、新しい言語モデルをゼロからトレーニングすることをこれまで以上に簡単にすることを目指しました。 この記事では、”小さな”モデル(84 Mパラメータ = 6層、768隠れユニット、12アテンションヘッド)を「エスペラント」でトレーニングする方法をデモンストレーションします。その後、モデルを品詞タグ付けの下流タスクでファインチューニングします。 エスペラントは学習しやすいことを目標とした人工言語です。このデモンストレーションのために選んだ理由は以下のとおりです: 比較的リソースが少ない言語です(約200万人が話すにもかかわらず)、このデモンストレーションはもう1つの英語モデルのトレーニングよりも面白くなります 😁 文法が非常に規則的です(例:一般的な名詞は-oで終わり、すべての形容詞は-aで終わります)。そのため、小さなデータセットでも興味深い言語的結果が得られるはずです。 最後に、この言語の基盤となる目標は人々をより近づけることです(世界平和と国際理解を促進すること)。これはNLPコミュニティの目標と一致していると言えるでしょう 💚 注:この記事を理解するためにはエスペラントを理解する必要はありませんが、学びたい場合はDuolingoには280,000人のアクティブな学習者がいる素敵なコースがあります。 私たちのモデルの名前は…待ってください…EsperBERTo 😂 1. データセットを見つける まず、エスペラントのテキストコーパスを見つけましょう。ここでは、INRIAのOSCARコーパスのエスペラント部分を使用します。OSCARは、WebのCommon Crawlダンプの言語分類とフィルタリングによって得られた巨大な多言語コーパスです。 データセットのエスペラント部分はわずか299Mですので、Leipzig Corpora Collectionのエスペラントサブコーパスと連結します。このサブコーパスには、ニュース、文学、ウィキペディアなど様々なソースのテキストが含まれています。 最終的なトレーニングコーパスのサイズは3 GBですが、モデルに先行学習するためのデータが多ければ多いほど、より良い結果が得られます。 2.…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
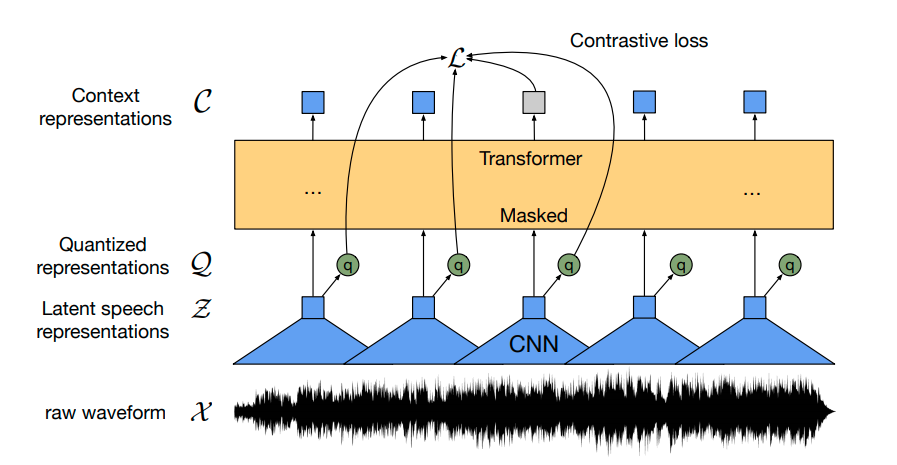
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…

Hugging Face Hubへようこそ、spaCyさん
spaCyは、産業界で広く使用される高度な自然言語処理のための人気のあるライブラリです。spaCyを使用すると、固有表現認識、テキスト分類、品詞タグ付けなどのタスクのためのパイプラインの使用とトレーニングが容易になり、大量のテキストを処理して分析する強力なアプリケーションを構築できます。 Hugging Faceを使用すると、spaCyパイプラインをコミュニティと簡単に共有できます!単一のコマンドで、モデルカードが含まれ、必要なメタデータが自動生成されたパイプラインパッケージをアップロードできます。推論APIは現在、固有表現認識(NER)をサポートしており、パイプラインをブラウザで対話的に試すことができます。また、パッケージ用のライブURLも提供されるため、プロトタイプから本番環境までのスムーズなパスでどこからでもpip installできます! モデルの検索 spaCy orgには、60以上のカノニカルモデルがあります。これらのモデルは最新の3.1リリースからのものであり、最新のリリースモデルをすぐに試すことができます!さらに、コミュニティからのすべてのspaCyモデルはここで見つけることができます:https://huggingface.co/models?filter=spacy。 ウィジェット この統合にはNERウィジェットのサポートも含まれており、NERコンポーネントを持つすべてのモデルは、デフォルトでこれを備えています!近日中に、テキスト分類や品詞タグ付けのサポートも追加されます。 既存のモデルの使用 Hubからのすべてのモデルは、pip installを使用して直接インストールすることができます。 pip install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl # spacy.load()を使用する。 import spacy nlp = spacy.load("en_core_web_sm") # モジュールとしてインポートする。…

Streamlitを使用して、Hugging Face Spacesにモデルとデータセットをホスティングする
Streamlitを使用してHugging Face Spacesでデータセットとモデルを紹介する Streamlitを使用すると、データセットを視覚化し、機械学習モデルのデモをきれいに構築することができます。このブログ記事では、モデルとデータセットのホスティング、およびHugging Face SpacesでのStreamlitアプリケーションの提供方法をご紹介します。 モデルのデモを作成する Hugging Faceのモデルを読み込んで、Streamlitを使用してクールなUIを構築することができます。この具体的な例では、「Write with Transformer」を一緒に再現します。GPT-2やXLNetなどのtransformerを使用して何でも書けるアプリケーションです。 推論の仕組みについては詳しく触れません。ただし、この特定のアプリケーションにはいくつかのハイパーパラメータ値を指定する必要があることを知っておく必要があります。Streamlitには、カスタムアプリケーションを簡単に実装できる多くのコンポーネントが提供されています。必要なハイパーパラメータを推論コード内で受け取るために、それらの一部を使用します。 .text_areaコンポーネントは、入力する文章を受け入れるための素敵なエリアを作成します。 Streamlitの.sidebarメソッドを使用すると、サイドバーで変数を受け入れることができます。 sliderは連続値を取るために使用されます。ステップを指定しない場合、値は整数として扱われますので、忘れずにステップを指定してください。 number_inputを使用すると、エンドユーザーに整数値の入力をさせることができます。 import streamlit as st # テキストボックスに表示されるデフォルトのテキストを追加 default_value =…
機械学習の時代がコードとして到来しました
2021年版のState of AIレポートが先週発表されました。そして、Kaggle State of Machine Learning and Data Science Surveyも同様です。これらのレポートには学びや議論の余地がたくさんありますが、いくつかのポイントが私の注意を引きました。 「AIはますます国家の電力網やパンデミック中の自動スーパーマーケットの倉庫計算など、ミッションクリティカルなインフラに適用されています。しかし、成熟度が急速に成長する展開の巨大さに追いついているかどうかについては疑問があります。」 機械学習を活用したアプリケーションがITのあらゆる分野に広がっていることは否定できません。しかし、それは企業や組織にとってどういう意味を持つのでしょうか?どのように堅牢な機械学習ワークフローを構築すれば良いのでしょうか?私たちは皆、100人のデータサイエンティストを採用すべきなのでしょうか?それとも100人のDevOpsエンジニアを採用すべきなのでしょうか? 「トランスフォーマーは、自然言語処理だけでなく、音声、コンピュータビジョン、さらにはタンパク質の構造予測など、機械学習の一般的なアーキテクチャとして登場しています。」 古参の人々は、ITには銀の弾丸はないということを痛感してきました。それでも、トランスフォーマーのアーキテクチャは、さまざまな機械学習タスクにおいて非常に効率的です。しかし、機械学習の革新の猛烈なペースにどうやってついていけば良いのでしょうか?これらの最先端モデルを活用するためには、本当に専門的なスキルが必要なのでしょうか?それとももっと短い道でビジネス価値を創出する方法があるのでしょうか? さて、私の考えはこうです。 マス向け機械学習! 機械学習はどこにでもあります、少なくともそうしようとしています。数年前、Forbesは「ソフトウェアが世界を食べた、今度はAIがソフトウェアを食べる」と書きましたが、これは実際にはどういう意味なのでしょうか?もし、それが機械学習モデルが何千行もの化石化した旧式のコードを置き換えるべきだという意味なら、私は全面賛成です。邪悪なビジネスルールよ、死ね! では、機械学習が実際にソフトウェアエンジニアリングを置き換えるということでしょうか?現在、AIが生成したコードについて幻想が広がっており、バグやパフォーマンスの問題を見つけるなど、いくつかの技術は確かに興味深いものです。しかし、開発者を廃止することは考えるべきではありませんし、むしろ多くの開発者を力強くサポートするために取り組むべきです。そうすれば、機械学習はただの別の退屈なITのワークロードになるでしょう(退屈なテクノロジーは素晴らしいです)。言い換えれば、私たちが本当に必要としているのは、ソフトウェアが機械学習を食べることなのです! 今回も変わらない 私は長年にわたり、ソフトウェアエンジニアリングの10年以上前のベストプラクティスがデータサイエンスや機械学習にも適用されると主張してきました。バージョン管理、再利用性、テスト可能性、自動化、デプロイメント、モニタリング、パフォーマンス、最適化などです。しばらくは孤独だったのですが、予想外にGoogleの連携がありました: 「機械学習は、あなたが偉大な機械学習の専門家ではなく、偉大なエンジニアとして機械学習を行うべきです。」- 『機械学習のルール』、Google また、車輪を再発明する必要はありません。DevOpsの運動はこれらの問題を10年以上前に解決しました。今や、データサイエンスと機械学習コミュニティは、これらの実証済みのツールとプロセスを遅延なく採用し、適応させるべきです。これが唯一の方法であり、本番環境で堅牢でスケーラブルかつ繰り返し可能な機械学習システムを構築することができます。もしMLOpsと呼ぶことが助けになるのなら、それも構いません:別のバズワードについて議論するつもりはありません。…
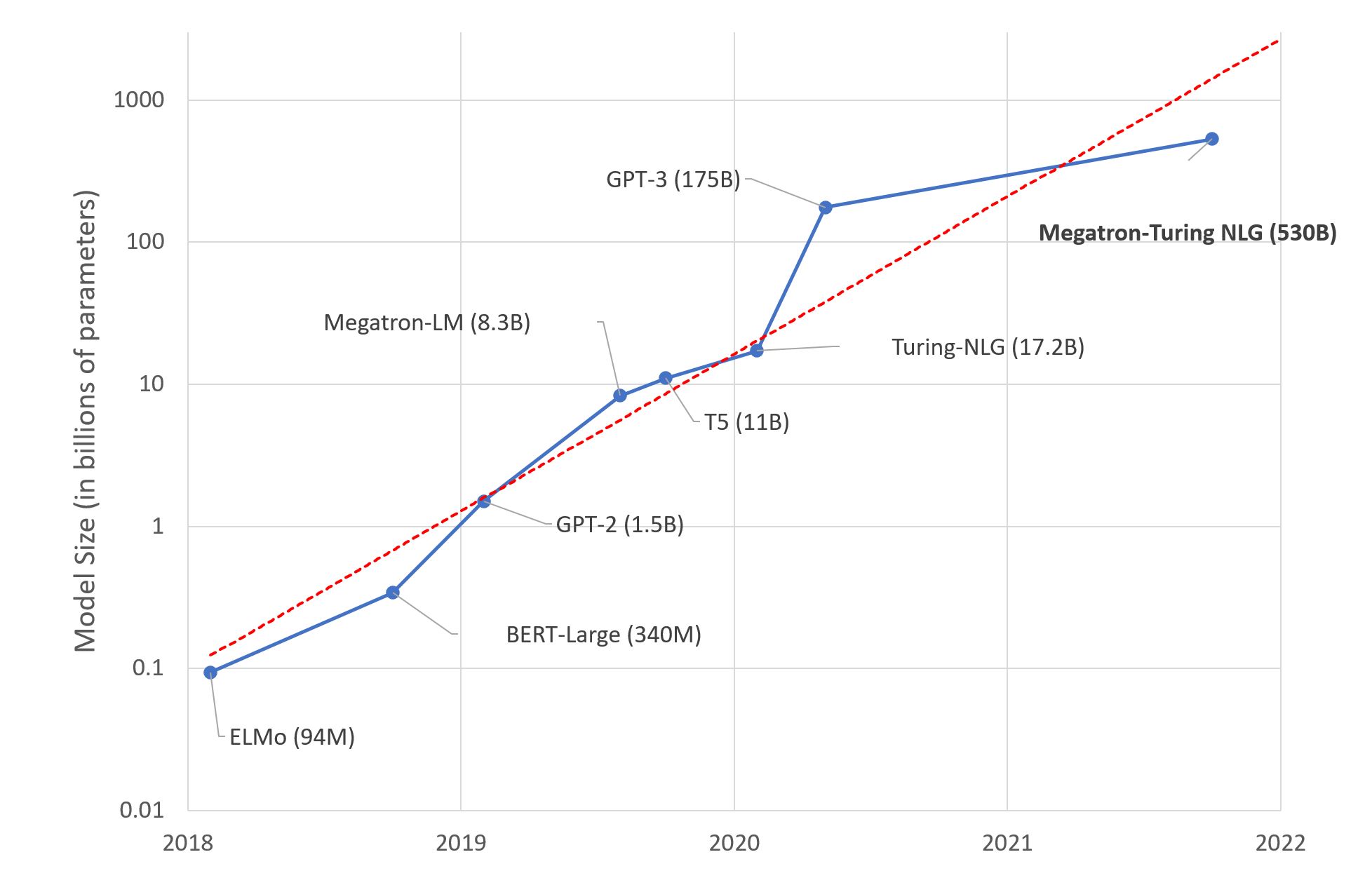
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.