Learn more about Search Results NGC - Page 51

- You may be interested
- MITとCUHKの研究者たちは、LLM(Long Cont...
- マイクロソフトの研究者は、2段階の介入フ...
- 大規模な言語モデルを効率的に提供するた...
- 「Amazon SageMaker JumpStartでのテキス...
- ZenMLとStreamlitを使用した従業員離職率予測
- Huggingface TransformersとRayを使用した...
- ローカルLLM推論を10倍速く実行する(244 ...
- 「なぜより多くがより良いのか(人工知能...
- 「AIが空中戦にロボットの相棒をもたらす」
- 研究者たちは、画像内の似たような材料を...
- CarperAIは、コードと自然言語の両方で進...
- なぜAIが2023年のトップ開発者スキルとな...
- 「GO TO Any Thing(GOAT)」とは、完全に...
- 「最初のAIエージェントを開発する:Deep ...
- 「生成型AI:CHATGPT、Dall-E、Midjourney...

「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
大規模な言語モデル(LLM)を強化して、単にユーザーの質問に応答するのではなく、目標のために独立して活動できる自律的な言語エージェントにするという、力強い新しいトレンドが浮上しています。React、Toolformer、HuggingGPT、生成エージェント、WebGPT、AutoGPT、BabyAGI、Langchainなどは、LLMを利用して自律的な意思決定エージェントを開発する実用性を効果的に実証したよく知られた研究です。これらの手法は、LLMを使用してテキストベースの出力とアクションを生成し、それを使用して特定の文脈でAPIにアクセスし、活動を実行します。 ただし、現在の言語エージェントの大部分は、パラメータ数の多いLLMの範囲が非常に広いため、環境の報酬関数に最適化された行動を持っていません。ReflexionやSelf-Refine、Generative Agentなど、同様のアプローチを取る他の多くの作品とは異なり、比較的新しい言語エージェントアーキテクチャである反省アーキテクチャは、過去の失敗から学ぶために、口頭フィードバック、具体的には自己反省を利用してエージェントを支援します。これらの反射エージェントは、環境のバイナリまたはスカラーの報酬を音声入力としてテキストの要約に変換し、言語エージェントのプロンプトにさらなる文脈を提供します。 自己反省フィードバックは、エージェントに特定の改善領域を指示することで、エージェントにとって意味的な信号となります。これにより、エージェントは過去の失敗から学び、同じ間違いを繰り返さずに次回の試行でより良い結果を出すことができます。ただし、自己反省操作によって反復的な改善が可能になるものの、事前に訓練された凍結LLMから有用な反省フィードバックを生成することは困難です(図1参照)。これは、LLMが特定の環境でエージェントの誤りを特定し、改善の提案を含む要約を生成する能力が必要だからです。 図1は、凍結LLMの情報のない自己反省のイラストです。エージェントは「Teen Titans」という回答ではなく、「Teen Titans Go」と回答するべきであり、これが前回の試行が失敗した主な理由です。一連の思考、行動、詳細な観察を通じて、エージェントは目標を見失いました。しかし、凍結LLMからの音声フィードバックは、以前のアクションシーケンスを新たな計画として提案するだけであり、次の試行でも同じ間違った行動につながります。 特定の状況でのタスクの信用割り当ての問題を専門にするために、凍結言語モデルを十分に調整する必要があります。また、現在の言語エージェントは、異なる可能な報酬に基づいて勾配ベースの学習からの思考や計画に一貫した方法で取り組んでいません。Salesforce Researchの研究者は、Retroformerというモラルフレームワークを紹介し、制約を解決するためのプラグインの後向きモデルを学習して言語エージェントを強化する方法を提案しています。Retroformerは、方策最適化を通じて環境からの入力に基づいて言語エージェントのプロンプトを自動的に改善します。 具体的には、提案されたエージェントアーキテクチャは、失敗した試行を反省し、将来の報酬に対してエージェントが実行したアクションにクレジットを割り当てることで、事前に訓練された言語モデルを反復的に改善します。これは、複数の環境とタスク全体にわたる任意の報酬情報から学習することによって行われます。HotPotQAなどのオープンソースのシミュレーションおよび実世界の設定(WikipediaのAPIに繰り返し問い合わせる必要があるWebエージェントのツール使用スキルを評価する)で実験を行います。HotPotQAは、検索ベースの質問応答タスクで構成されています。反省に対して、勾配を使用しない思考や計画を行わないRetroformerエージェントは、より速く学習し、より良い意思決定を行います。具体的には、Retroformerエージェントは、検索ベースの質問応答タスクのHotPotQAの成功率をわずか4回の試行で18%向上させ、多くの状態アクション空間を持つ環境でのツール使用における勾配ベースの計画と推論の価値を証明しています。 結論として、彼らが貢献した内容は次の通りです: • この研究では、大規模言語エージェントへのコンテキスト入力に基づいて提示されるプロンプトを反復的に洗練することで、学習速度とタスク完了を向上させるRetroformerを開発しました。提案された手法は、Actor LLMのパラメータにアクセスせず、勾配を伝播する必要もないため、言語エージェントアーキテクチャ内のレトロスペクティブモデルの強化に焦点を当てています。 • 提案された手法により、さまざまなタスクと環境のためのさまざまな報酬信号からの学習が可能となります。Retroformerは、その汎用性のため、GPTやBardなどのクラウドベースのLLMに適応可能なプラグインモジュールです。

「Jupyter AIに会おう:マジックコマンドとチャットインターフェースでジェネラティブ人工知能をJupyterノートブックにもたらす新しいオープンソースプロジェクト」
Jupyter AIは、Project Jupyterの公式サブプロジェクトであり、Jupyterノートブックに生成型人工知能をもたらします。ユーザーはコードを説明し、生成し、エラーを修正し、コンテンツを要約し、自然言語のプロンプトから完全なノートブックを生成することができます。このツールは、AI21、Anthropic、AWS、Cohere、およびOpenAIを含むさまざまなプロバイダーの大規模言語モデル(LLM)をJupyterと接続し、LangChainによってサポートされています。 Jupyter AIは、責任あるAIとデータプライバシーを考慮して設計されており、ユーザーは特定のニーズに合わせて好みのLLM、埋め込みモデル、およびベクトルデータベースを選択することができます。ソフトウェアの基礎となるプロンプト、チェーン、およびコンポーネントはオープンソースであり、データの透明性が確保されています。さらに、モデルが生成したコンテンツに関するメタデータを保存するため、ワークフロー内でAIが生成したコードの追跡が容易になります。重要なことに、Jupyter AIはユーザーデータのプライバシーを尊重し、明示的な同意なしにデータを読み取ることや送信することはありません。 Jupyter AIを使用するには、ユーザーは自分のJupyterLab(バージョン3または4)に適したバージョンをpipを使用してインストールすることができます。ソフトウェアは、LLMと対話するための2つのインターフェースを提供しています。JupyterLab内のチャットUIと、サポートされているノートブック環境用のマジックコマンドインターフェースです。チャットインターフェース内のAIアシスタントであるJupyter Nautは、テキストを介してコミュニケーションを行い、さまざまな機能を提供します。一般的な質問に答えることや、コードを平易な英語や他の言語で説明すること、コードを修正すること、エラーを特定することができます。さらに、テキストプロンプトから完全なノートブックを生成するための「/generate」コマンドを使用することもできます。 チャットインターフェースでは、「/learn」コマンドを使用して、Jupyternautにローカルファイルについて教えることができます。Jupyternautは埋め込みモデルを使用してデータを変換し、ローカルのベクトルデータベースに保存するため、ユーザーは「/ask」コマンドを使用してこれらのファイルに関する質問をすることができます。AIは保存された情報に基づいて応答します。 ノートブック環境では、「%%ai」といったマジックコマンドを使用してLLMと対話することができます。ソフトウェアは複数のプロバイダーをサポートしており、ユーザーは「–format」パラメーターを使用して出力形式をカスタマイズすることができます。さらに、変数の補間により、AIモデルとの動的な対話が可能です。 Jupyter AIは、倫理的な考慮、プライバシー、データの透明性に焦点を当てたJupyterノートブックでのAIによるコード生成とアシストの貴重なツールです。ユーザーは実行する前にAIによって生成されたコードを確認することが推奨されており、人間が書いたコードと同じ慣行に従うことが求められます。結論として、Jupyter AIは、データプライバシーと責任あるAIの慣行を守りながら、AIによるコード生成、アシスト、説明を提供する、強力で倫理的なProject Jupyterの一環となっています。

キャッシング生成的LLMs | APIコストの節約
はじめに 生成AIは非常に広まっており、私たちのほとんどは、画像生成器または有名な大規模言語モデルなど、生成AIモデルを使用したアプリケーションの開発に取り組んでいるか、既に取り組んでいます。私たちの多くは、特にOpenAIなどのクローズドソースの大規模言語モデルを使用して、彼らが開発したモデルの使用に対して支払いをする必要があります。もし私たちが十分注意を払えば、これらのモデルを使用する際のコストを最小限に抑えることができますが、どういうわけか、価格はかなり上昇してしまいます。そして、この記事では、つまり大規模言語モデルに送信される応答/ API呼び出しをキャッチすることについて見ていきます。Caching Generative LLMsについて学ぶのが楽しみですか? 学習目標 Cachingとは何か、そしてそれがどのように機能するかを理解する 大規模言語モデルをキャッシュする方法を学ぶ LangChainでLLMをキャッシュするための異なる方法を学ぶ Cachingの潜在的な利点とAPIコストの削減方法を理解する この記事は、Data Science Blogathonの一部として公開されました。 Cachingとは何か?なぜ必要なのか? キャッシュとは、データを一時的に保存する場所であり、このデータの保存プロセスをキャッシングと呼びます。ここでは、最も頻繁にアクセスされるデータがより速くアクセスできるように保存されます。これはプロセッサのパフォーマンスに劇的な影響を与えます。プロセッサが計算時間がかかる集中的なタスクを実行する場合を想像してみてください。今度は、プロセッサが同じ計算を再度実行する状況を想像してみてください。このシナリオでは、前回の結果をキャッシュしておくと非常に役立ちます。タスクが実行された時に結果がキャッシュされていたため、計算時間が短縮されます。 上記のタイプのキャッシュでは、データはプロセッサのキャッシュに保存され、ほとんどのプロセスは組み込みのキャッシュメモリ内にあります。しかし、これらは他のアプリケーションには十分ではない場合があります。そのため、これらの場合はキャッシュをRAMに保存します。RAMからのデータアクセスはハードディスクやSSDからのアクセスよりもはるかに高速です。キャッシュはAPI呼び出しのコストも節約することができます。例えば、Open AIモデルに類似のリクエストを送信した場合、各リクエストに対して請求がされ、応答時間も長くなります。しかし、これらの呼び出しをキャッシュしておくと、モデルに類似のリクエストをキャッシュ内で検索し、キャッシュ内に類似のリクエストがある場合は、APIを呼び出す代わりにデータ、つまりキャッシュから応答を取得することができます。 大規模言語モデルのキャッシュ 私たちは、GPT 3.5などのクローズドソースのモデル(OpenAIなど)が、ユーザーにAPI呼び出しの料金を請求していることを知っています。請求額または関連する費用は、渡されるトークンの数に大きく依存します。トークンの数が多いほど、関連するコストも高くなります。これは大金を支払うことを避けるために慎重に扱う必要があります。 さて、APIを呼び出すコストを解決する/削減する方法の一つは、プロンプトとそれに対応する応答をキャッシュすることです。最初にモデルにプロンプトを送信し、それに対応する応答を取得したら、それをキャッシュに保存します。次に、別のプロンプトが送信される際には、モデルに送信する前に、つまりAPI呼び出しを行う前に、キャッシュ内の保存されたプロンプトのいずれかと類似しているかどうかをチェックします。もし類似している場合は、モデルにプロンプトを送信せずに(つまりAPI呼び出しを行わずに)キャッシュから応答を取得します。 これにより、モデルに類似のプロンプトを要求するたびにコストを節約することができ、さらに、応答時間も短縮されます。なぜなら、キャッシュから直接データを取得するため、モデルにリクエストを送信してから応答を取得する必要がないからです。この記事では、モデルからの応答をキャッシュするための異なる方法を見ていきます。 LangChainのInMemoryCacheを使用したキャッシュ はい、正しく読みました。LangChainライブラリを使用して、応答とモデルへの呼び出しをキャッシュすることができます。このセクションでは、キャッシュメカニズムの設定方法と、結果がキャッシュされており、類似のクエリに対する応答がキャッシュから取得されていることを確認するための例を見ていきます。必要なライブラリをダウンロードして開始しましょう。…

「Stitch FixにおけるMLプラットフォーム構築からの学び」
この記事は元々、MLプラットフォームポッドキャストのエピソードであり、Piotr NiedźwiedźとAurimas GriciūnasがMLプラットフォームの専門家と一緒に、デザインの選択肢、ベストプラクティス、具体的なツールスタックの例、そして最高のMLプラットフォームの専門家からの実世界の学びについて話し合っていますこのエピソードでは、Stefan KrawczykがMLを構築する際に得た学びを共有しています...

「生成AIとAmazon Kendraを使用して、エンタープライズスケールでキャプションの作成と画像の検索を自動化する」
Amazon Kendraは、機械学習(ML)によって駆動されるインテリジェントな検索サービスですAmazon Kendraは、ウェブサイトやアプリケーションのための検索を再構築し、従業員や顧客が組織内の複数の場所やコンテンツリポジトリに散らばっているコンテンツを簡単に見つけることができるようにしますAmazon Kendraはさまざまなドキュメントをサポートしています

VoAGIニュース、8月2日:ChatGPTコードインタプリタ:高速データサイエンス•追いつけない?AIの今週の話題をキャッチアップしましょう
ChatGPTコードインタプリター:数分でデータサイエンスを行う • 今週のAI • 統計学の入門、Pythonエディション:無料の書籍 • 2023年に学ぶための8つのデータサイエンスプログラミング言語 • GPUのマスタリング:PythonでのGPUアクセラレートされたデータフレームの初心者ガイド
このAIニュースレターは、あなたが必要なもの全てです#58
今週、私たちはNLPの領域外でAIの2つの新しい進展を見ることに興奮しましたMeta AIの最新の開発では、彼らのOpen Catalystシミュレーターアプリケーションの発表が含まれています

ChatGPTと高度なプロンプトエンジニアリング:AIの進化を推進する
「高度なプロンプト工学について学び、テクノロジーとのコミュニケーションにおける役割、ChatGPTなどのツールの応用について学ぶ」

「LLMsを使用したモバイルアプリの音声と自然言語の入力」
この記事では、GPT-4の関数呼び出しを使用してアプリに高度な柔軟性のある音声理解を実現する方法について学びますこれにより、アプリのGUIと完全にシナジーを発揮することができます
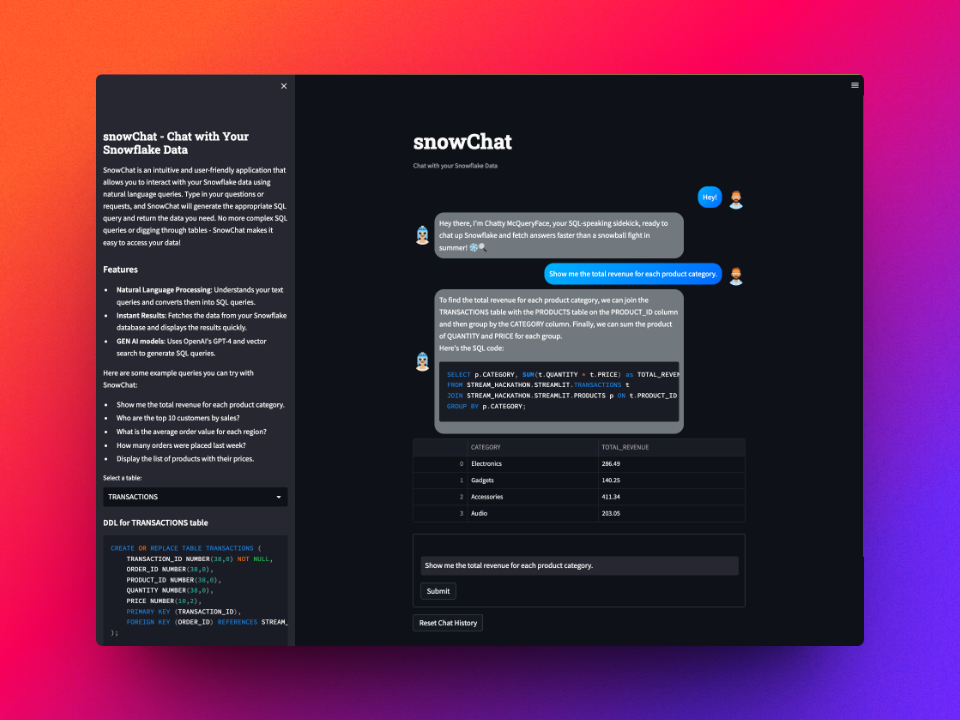
「snowChat」とは何ですか?
複雑なSQLクエリに苦戦していますか?1つのデータを見つけようとしてテーブルの海に迷っていますか?心配しないでください、私はこれらの問題を解決するためにsnowChatを作成しました!snowChatは…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.