Learn more about Search Results 6. 結論 - Page 51

- You may be interested
- Googleの機能や製品をラボで試してください
- 「S4 HANAとDomoでSQLを使用してデータ分...
- Intel CPU上での安定な拡散推論の高速化
- 「生成AIにおけるLLMエージェントのデコー...
- 「時間の逆転:拡散モデルと確率微分方程式」
- 「生成AIの組織化:データサイエンスチー...
- 「Nous-Hermes-Llama2-70bを紹介します:3...
- 思考のグラフ:大規模言語モデルにおける...
- プロキシマルポリシーオプティマイゼーシ...
- 「ラスティックデータ:Plottersを使用し...
- 「パート1:ステップバイステップでWindow...
- 「私は初めてのデータの仕事に就きました...
- 新技術による道路と橋の建設および修復の...
- Google Researchが、凍結された大規模言語...
- 「OpenAIがGPT-4へのアクセスを提供」

MLモデルのトレーニングパイプラインの構築方法
手を挙げてください、もしもあなたがごちゃ混ぜのスクリプトをほどくのに時間を無駄にしたことがあるか、またはそう難解なバグを修正しようとしている間に幽霊を追いかけているような気持ちになったことがあるかそしてその間にモデルの訓練が永遠にかかっているという状況も経験したことがあるかもしれません私たちは皆、そんな経験をしたことがあるはずですよね?でも今、別のシナリオを思い浮かべてくださいきれいなコード効率的なワークフロー効率的なモデルの訓練信じられないほど素晴らしい光景ですよね…

MLモデルの最適化とデバッグにSHAP値を使用する方法
こんな状況を想像してください数え切れないほどの時間を費やして、モデルのトレーニングと微調整に取り組み、山ほどのデータを入念に分析しましたしかし、予測に影響を与える要因に明確な理解が欠けており、その結果、さらに改善することが難しいと感じていますもし過去にこうした状況に陥ったことがあるなら、…

DataHour ChatGPTの幻視を80%減らす
はじめに 自然言語処理(NLP)モデルは近年、チャットボットから言語翻訳までさまざまなアプリケーションで人気が高まっています。しかし、NLPの最大の課題の1つは、モデルによって生成されるChatGPTの幻覚や不正確な応答を削減することです。この記事では、NLPモデルの幻覚を削減するために必要な技術と課題について説明します。 観測性、調整、テスト 幻覚を削減するための最初のステップは、モデルの観測性を向上させることです。これには、ユーザーフィードバックとモデルのパフォーマンスをプロダクションでキャプチャするフィードバックループの構築が含まれます。調整では、より多くのデータを追加したり、検索の問題を修正したり、プロンプトを変更したりすることで、不正確な応答を改善します。テストは、変更が結果を改善し、回帰を引き起こさないことを確認するために必要です。観測性の課題には、顧客が不正確な応答のスクリーンショットを送信することによって引き起こされるイライラが含まれます。これに対処するために、データの取り込みと秘密のコードを使用してログを毎日監視することができます。 言語モデルのデバッグとチューニング 言語モデルのデバッグとチューニングのプロセスでは、モデルの入力と応答を理解することが重要です。デバッグには、生のプロンプトを特定のチャンクや参照に絞り込むためにログが必要です。ログは、誰にでも理解しやすく、実行可能なものでなければなりません。チューニングでは、モデルにどれだけのドキュメントを与えるべきかを決定します。デフォルトの数値は常に正確ではなく、類似検索では正しい答えが得られないことがあります。目標は、何がうまくいかなかったのか、それを修正する方法を見つけることです。 OpenAI埋め込みの最適化 アプリケーションで使用されるOpenAI埋め込みのパフォーマンスを最適化することに直面したベクトルデータベースクエリアプリケーションの開発者は、いくつかの課題に直面しました。最初の課題は、モデルに渡す最適なドキュメント数を決定することであり、これはチャンキング戦略の制御とドキュメント数のための制御可能なハイパーパラメータの導入によって解決されました。 2番目の課題は、プロンプトのバリエーションであり、Better Promptというオープンソースライブラリを使用して、パープレキシティに基づいて異なるプロンプトバージョンのパフォーマンスを評価しました。3番目の課題は、マルチリンガルシナリオでの文の変換子よりもOpenAI埋め込みの結果の改善が見つかったことです。 AI開発の技術 この記事では、AI開発で使用される3つの異なる技術について説明しています。最初の技術はパープレキシティであり、与えられたタスクにおけるプロンプトのパフォーマンスを評価するために使用されます。2番目の技術は、ユーザーが異なるプロンプト戦略を簡単にテストできるパッケージの構築です。3番目の技術は、インデックスの実行であり、何かが欠けているか理想的でない場合に追加のデータを使用してインデックスを更新することが含まれます。これにより、質問のよりダイナミックな処理が可能になります。 GPT-3 APIを使用してパープレキシティを計算する スピーカーは、クエリに基づいてパープレキシティを計算するためにGPT-3 APIを使用した経験について説明しています。彼らはAPIを介してプロンプトを実行し、最適な次のトークンのログ確率を返すプロセスについて説明しています。また、新しい情報を埋め込むのではなく、特定の書き方を模倣するために大規模な言語モデルを微調整する可能性についても言及しています。 複数の質問に対する応答の評価 テキストでは、50以上の質問に対する応答の評価の課題について説明しています。すべての応答を手動で採点するのは時間がかかるため、会社は自動評価ツールの使用を検討しました。しかし、単純なはい/いいえの判断枠組みでは不十分であり、回答が正しくない理由は複数あります。会社は評価をさまざまなコンポーネントに分割しましたが、自動評価ツールの単一の実行は不安定で一貫性がありませんでした。これを解決するために、質問ごとに複数のテストを実行し、応答を完璧、ほぼ完璧、一部正しい情報を含む不正確、完全に不正確なものに分類しました。 NLPモデルでの幻覚の削減 スピーカーは、自然言語処理モデルでの幻覚を削減するためのプロセスについて説明しています。彼らは意思決定プロセスを4つのカテゴリに分け、50以上のカテゴリに対して自動機能を使用しました。また、評価プロセスをコア製品に展開し、評価を実行してCSBにエクスポートすることも可能にしました。スピーカーはプロジェクトに関する詳細情報のためのGitHubリポジトリに言及しています。そして、観測性、調整、テストなどの手順を取り上げ、幻覚率を40%から5%未満に削減することができました。 結論 NLPモデルにおけるChatGPTの幻想を減らすことは、可観測性、調整、テストといった複雑なプロセスを必要とします。開発者はプロンプトのバリエーション、埋め込みの最適化、複数の質問に対する応答の評価も考慮する必要があります。また、困惑度、プロンプト戦略のテスト用パッケージの作成、インデックスの実行といったテクニックもAI開発に役立つことがあります。AI開発の未来は、小規模でプライベート、またはタスク固有の要素にあります。 要点 NLPモデルにおけるChatGPTの幻想を減らすには、可観測性、調整、テストが必要です。…
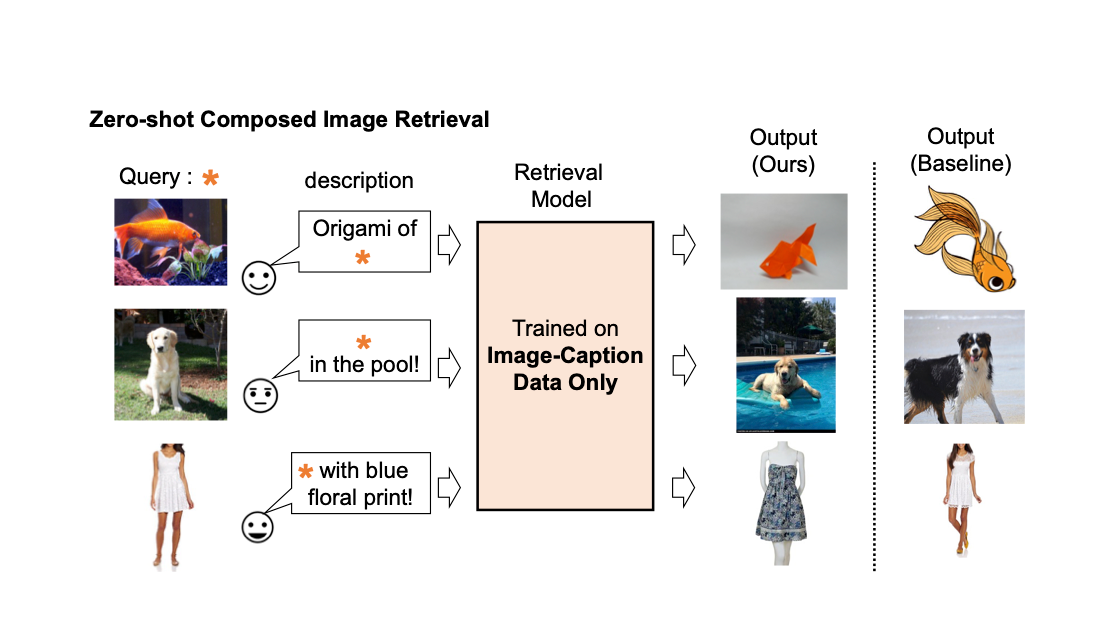
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…
トランスフォーマーエンコーダー | 自然言語処理の核心の問題
イントロダクション 非常に簡単な方法でトランスフォーマーエンコーダーを説明します。トランスフォーマーの学習に苦労している人は、このブログ投稿を最後まで読んでください。自然言語処理(NLP)の分野で働く興味がある方は、トランスフォーマーについて少なくとも基本的な知識を持っておくべきです。ほとんどの産業はこの最新のモデルをさまざまな仕事に使用しています。トランスフォーマーは、「Attention Is All You Need」という論文で紹介された最新のNLPモデルであり、従来のRNNやLSTMを上回っています。トランスフォーマーは再帰ではなくセルフアテンションに頼ることで、長期的な依存関係の捉える課題を克服しています。トランスフォーマーはNLPを革新し、BERT、GPT-3、T5などのアーキテクチャの道を開いています。 学習目標 この記事では、以下を学びます: トランスフォーマーがなぜ人気になったのか? NLPの分野でのセルフアテンションメカニズムの役割。 自分自身の入力データからキー、クエリ、バリューの行列を作成する方法。 キー、クエリ、バリューの行列を使用してアテンション行列を計算する方法。 メカニズムにおけるソフトマックス関数の適用の重要性。 この記事は、データサイエンスブログマラソンの一部として公開されました。 トランスフォーマーがRNNやLSTMモデルを上回る要因は何か? RNNやLSTMでは、長期的な依存関係を理解することができず、複雑なデータを扱う際に計算量が増えるという問題に直面しました。「Attention Is All You Need」という論文では、トランスフォーマーという新しいデザインが従来の順次ネットワークの制約を克服するために開発され、NLPアプリケーションの最先端モデルとなりました。 RNNやLSTMでは、入力とトークンは一度に1つずつ与えられ、トランスフォーマーではデータを並列に処理します。 トランスフォーマーモデルは再帰プロセスを完全に排除し、アテンションメカニズムに完全に依存しています。セルフアテンションという独特のアテンションメカニズムを使用します。 トランスフォーマーの構成と動作 多くのNLPタスクでは、トランスフォーマーモデルが現在の最先端モデルです。トランスフォーマーの導入により、NLPの分野での大きな進歩があり、BERT、GPT-3、T5などの先端システムの道を開きました。…

経験がなくてもデータアナリストになる方法
導入 エントリーレベルのデータアナリストは年間で最大$49,092を稼ぐことができることを知っていますか?現代のデータ駆動型の世界では、データ分析のキャリアは多様な産業にまたがり、この急速に成長している分野に入るための多くの道があります。データはすべての組織にとって主要な意思決定ツールです。分析はすべてのセクターで戦略的計画の重要な要素です。この記事では、新卒者の間でよくある質問に答えることを目的としています – 経験がない状態でデータアナリストになる方法! 経験がない状態でデータアナリストになることは可能ですか? 絶対に可能です!必要な資格を取得することで、経験がない状態でもデータアナリストの役割を追求することができます。データの仕事市場が初心者にアクセス可能な要因はいくつかあります: データの専門知識の不足:データの専門家の需要は現在の供給を上回り、新参者がこの分野に参入する機会が生まれています。 移行可能なスキルの重視:データ分析では、他のドメインから応用できるスキルが重要視されており、既存の能力を活用することができます。 市場の急速な成長:データの市場は指数関数的な成長を遂げており、産業全体で熟練した専門家の需要が増しています。 ビジネスがデータ駆動型の戦略に依存するにつれて、データの専門家の採用は最優先事項となります。個々人は努力を投資し、成長を受け入れ、適切なトレーニングリソースにアクセスすることで、このダイナミックな分野で成功するために必要な専門知識を獲得することができます。 経験がない状態でデータアナリストになる方法 経験がない状態でもデータアナリストの仕事を得るためのステップバイステップガイドをご紹介します: 1. 関連するスキルを習得する データアナリストである必要はなくても、統計学、数学、またはコンピュータサイエンスの関連科目の学位を持っていることは役立つ場合があります。対面のトレーニングセッションに参加したり、ビデオチュートリアルを視聴したり、オンラインコースを受講したりして、データの専門知識を向上させることができます。MatplotlibやSeabornのようなPythonのライブラリや、TableauやPower BIなどのデータ可視化アプリケーションを学びましょう。プログラミング言語に関連する言語の構文、データ型、およびパッケージの理解に時間を費やしましょう。 2. データツールをマスターする 実際のデータプロジェクトでは、実践的な設定でデータを使用する方法を教えてくれることで、実践的な経験を積むことができます。既存のプロジェクトに参加したり、公開されているいくつかの無料の公開データセットを活用して自分自身のプロジェクトを作成したりすることができます。データの取り扱いにはExcel、データベースのクエリにはSQL、SASやSPSSなどの統計ソフトウェアなどのツールを試してみましょう。 役に立つリソース – ソースコード付きの10の最高のデータ分析プロジェクト SQLの初心者ガイド 無料でオンラインでMS…
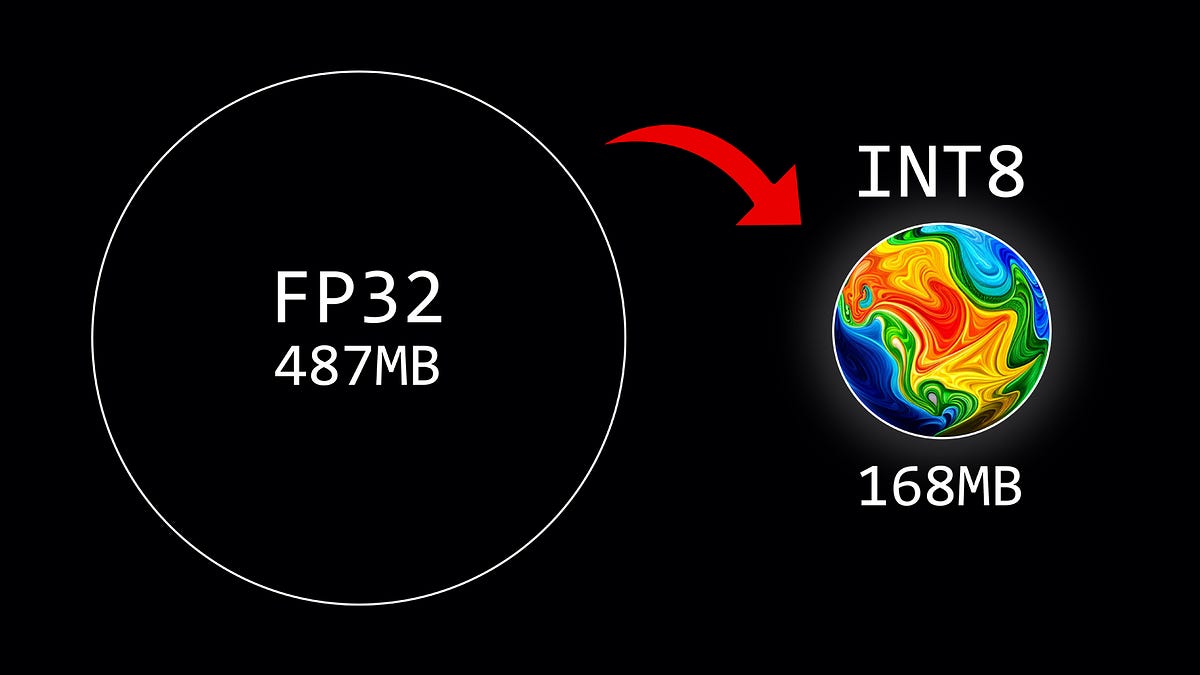
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています

Falcon-7Bの本番環境への展開
これまでに、ChatGPTの能力と提供するものを見てきましたしかし、企業利用においては、ChatGPTのようなクローズドソースモデルは、企業がデータを制御できないというリスクがあるかもしれません...
OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
プロンプトエンジニアリングの台頭や、言語モデルの大規模な成果により、私たちの問いに対する応答を生成する際の大変な成果を上げたLarge Language Modelsの注目すべき成果により、ChatGPTのようなチャットボットは私たちの日常生活の重要な一部となりつつあります...
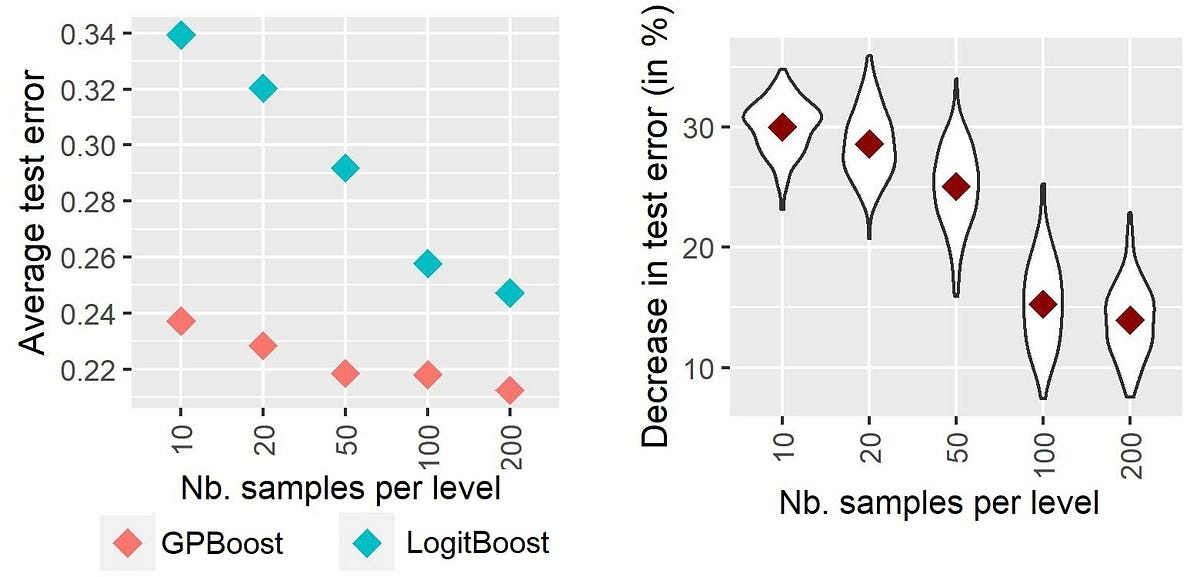
ハイカーディナリティのカテゴリカル変数に対する混合効果機械学習-第I部:異なる手法の実証的比較
高次元のカテゴリー変数のモデリングを向上させるための機械学習におけるランダム効果:アプローチの紹介と比較
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.