Learn more about Search Results 使用方法 - Page 51

- You may be interested
- バイデン政権、中国へのA.I.チップの販売...
- システムにエージェントが存在するかを発...
- 「ジェンAI愛好家が読むべき5冊の本」
- 「AGENTS内部 半自律LLMエージェントを構...
- 「NVIDIAは創造的AIの台頭に対応するため...
- ロンドン大学の研究者がDSP-SLAMを紹介:...
- なぜ仮説検定はハムレットからヒントを得...
- 「現代の自然言語処理:詳細な概要パート3...
- ハギングフェイスフェローシッププログラ...
- コンピュータモデルが猫の嗅覚を説明します
- スタートアップに参加する前に、データエ...
- 「全てのOECDおよびG20加盟国において、イ...
- 「ヘルスケアとゲノミクス産業が機械学習...
- コンテンツモデレーションからゼロショッ...
- 「SUSTech VIP研究室が、高性能なインタラ...

PyTorch DDPからAccelerateへ、そしてTrainerへ簡単に分散トレーニングをマスターしましょう
全般的な概要 このチュートリアルでは、PyTorchと単純なモデルのトレーニング方法について基本的な理解があることを前提としています。分散データ並列処理(DDP)というプロセスを通じて複数のGPUでのトレーニングを紹介します。以下の3つの異なる抽象化レベルを通じて行います: pytorch.distributedモジュールを使用したネイティブなPyTorch DDP pytorch.distributedをラップした🤗 Accelerateの軽量なラッパーを利用し、コードの変更なしに単一のGPUおよびTPUで実行できるようにする方法 🤗 Transformerの高レベルのTrainer APIを利用し、ボイラープレートコードを抽象化し、さまざまなデバイスと分散シナリオをサポートする方法 「分散」トレーニングとは何か、なぜ重要なのか? まず、公式のMNISTの例に基づいて、以下の非常に基本的なPyTorchのトレーニングコードを見てみましょう。 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as…

🤗評価による言語モデルのバイアスの評価
大規模な言語モデルのサイズと能力は過去数年間で大幅に向上していますが、これらのモデルとそのトレーニングデータに刻み込まれたバイアスへの懸念も同様に高まっています。実際、多くの人気のある言語モデルは特定の宗教や性別に対してバイアスがあることが判明しており、これによって差別的な考えの促進やマージナライズドグループへの害の持続が引き起こされる可能性があります。 コミュニティがこのようなバイアスを探索し、言語モデルがエンコードする社会的な問題に対する理解を強化するために、私たちはバイアスのメトリクスと測定値を🤗 Evaluate ライブラリに追加する作業を行ってきました。このブログ投稿では、新しい機能のいくつかの例とその使用方法について紹介します。GPT-2 や BLOOM のような因果言語モデル (CLMs) の評価に重点を置き、プロンプトに基づいた自由なテキストの生成能力を活かします。 実際に作業を見るには、作成した Jupyter ノートブックをチェックしてください! ワークフローには次の2つの主要なステップがあります: あらかじめ定義された一連のプロンプトを言語モデルに提示する(🤗 データセットでホストされている) メトリクスや測定値を使用して生成物を評価する(🤗 Evaluate を使用) 有害な言語に焦点を当てた3つのプロンプトベースのタスクでバイアスの評価を進めましょう:有害性、極性、および害悪性。ここで紹介する作業は、Hugging Face ライブラリを使用してバイアスの分析にどのように活用するかを示すものであり、使用される特定のプロンプトベースのデータセットには依存しません。重要なことは、最近導入されたバイアスの評価用データセットがモデルが生み出す様々なバイアスを捉えていない初歩的なステップであるということです(詳細については以下の議論セクションを参照してください)。 有害性 実世界のコンテキストで CLM…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…

モデルカード
イントロダクション モデルカードは、機械学習モデルの理解、共有、改善のための重要なドキュメンテーションフレームワークです。適切に行われた場合、モデルカードは境界オブジェクトとして機能し、異なるバックグラウンドや目標を持つ人々(開発者、学生、政策立案者、倫理学者、機械学習モデルに影響を受ける人々など)がモデルを理解するためにアクセスできる単一のアーティファクトとなります。 今日、私たちはモデルカードの作成ツールとモデルカードガイドブックを発表しました。モデルカードの記入方法、ユーザースタディ、MLドキュメンテーションの最先端について詳しく説明しています。この作業は、他の多くの人々や組織によるものを基にしており、異なるバックグラウンドや役割を持つ人々の包括的な参加を重視しています。私たちは、これが改善されたMLドキュメンテーションの道筋となることを願っています。 要約すると、今日は以下のリリースを発表します: プログラムを必要とせずにカード作成を容易にするモデルカードクリエーターツール。さらに、異なるセクションの作業をチームで共有するための支援をします。 huggingface_hubライブラリでリリースされた更新されたモデルカードテンプレート。学界や業界全体でのモデルカードの作業をまとめています。 カードの記入方法を詳しく説明した注釈付きモデルカードテンプレート。 Hugging Faceでのモデルカードの使用に関するユーザースタディ。 モデルドキュメンテーションの最先端に関するランドスケープ分析と文献レビュー。 現在までのモデルカード モデルカードは、Mitchellらによって提案され、自然言語処理のデータステートメント(Bender&Friedman、2018)やデータセットのデータシート(Gebruら、2018)といった主要なドキュメンテーションフレームワークの努力に触発されています。機械学習ドキュメンテーションの領域は拡大し進化しており、データ、モデル、およびMLシステムのためのさまざまなドキュメンテーションツールやテンプレートが提案され、開発されてきました。これには、何百もの研究者、関係者、提唱者などの信じられないほどの研究成果が反映されています。また、MLドキュメンテーションと責任あるAIの変革理論との関係について重要な議論も、MLドキュメンテーションエコシステムの発展に影響を与えています。 ML内のドキュメンテーションにおけるこれまでの取り組みは、さまざまな対象に対応しています。私たちは、今日共有する作業でこれらのアイデアの多くを取り入れています。 私たちの取り組み 私たちの作業は、モデルカードの現在の状況と将来の展望を示しています。私たちは、成長するMLドキュメンテーションツールのランドスケープを広範に分析し、Hugging Face内でユーザーインタビューを行い、モデルカードに関する多様な意見を補完しました。また、Hugging Face HubのMLモデルに対してモデルカードを作成または更新し、これらの経験を基に新しいモデルカードのテンプレートを提案しています。 モデルカードの標準化 ガイドブックでさらに詳しく説明されている背景調査やユーザースタディを通じて、一般の人々が理解する「モデルカード」の新しい標準を確立することを目指しました。 これらの調査結果に基づいて、HFモデルカードの構造と内容を標準化するだけでなく、デフォルトのプロンプトテキストも提供する新しいモデルカードテンプレートを作成しました。このテキストは、モデルカードのセクションの執筆を支援するためのものであり、特にバイアス、リスク、制限のセクションに焦点を当てています。 アクセシビリティと包括性 モデルカードの作成における参加のハードルを下げるために、モデルカード作成ツールを設計しました。これは、グラフィカルユーザーインターフェース(GUI)を備えたツールであり、コーディングやマークダウンの使用を必要とせずに、さまざまなスキルセットや役割を持つ人々やチームが簡単に協力してモデルカードを作成できるようにします。 この作成ツールは、モデルカードをまだ作成していない人々に簡単に作成するように促し、以前にモデルカードを作成したことがある人々にはプロンプトされた情報を追加するように促します。同時に、倫理的な要素を重視します。…
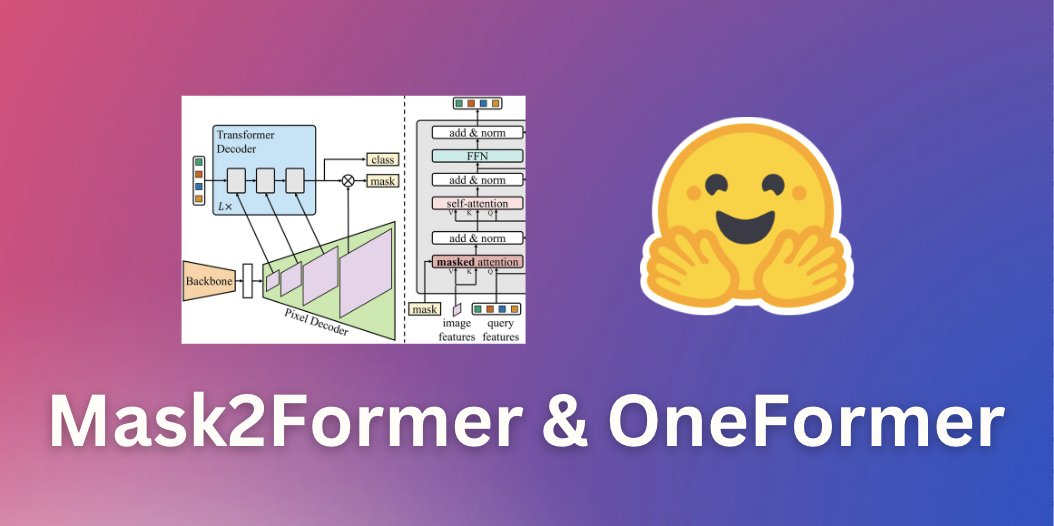
マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。 画像セグメンテーション 画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。 画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。 インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。 パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。 以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。 ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。 ユニバーサル画像セグメンテーション 幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。 Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。 要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。 Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。 TransformersでのMask2FormerとOneFormerの推論 Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。 from…

ストーリーの生成:ゲーム開発のためのAI #5
AIゲーム開発へようこそ!このシリーズでは、AIツールを使用してわずか5日で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに取り入れる方法を学ぶことができます。以下のような目的でAIツールを使用する方法をお見せします: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが欲しいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注:この投稿では、ゲームデザインにChatGPTを使用したPart 2への参照がいくつかあります。ChatGPTの動作方法、言語モデルの概要、およびその制限についての追加のコンテキストについては、Part 2をお読みください。 Day 5: ストーリー このチュートリアルシリーズのPart 4では、Stable DiffusionとImage2Imageを2Dアセットのワークフローに使用する方法について説明しました。 この最終パートでは、ストーリーにAIを使用します。まず、農業ゲームのプロセスを説明し、注意すべき⚠️ 制限事項について説明します。次に、ゲーム開発の文脈での関連技術と今後の方向性について話します。最後に、最終的なゲームについてまとめます。 プロセス 要件:このプロセス全体でChatGPTを使用しています。ChatGPTと言語モデリングについての詳細については、シリーズのPart 2をお読みいただくことをおすすめします。ChatGPTは唯一の解決策ではありません。オープンソースの対話エージェントなど、数多くの新興競合他社が存在します。対話エージェントの新興市場についてさらに詳しく学ぶために、先を読んでください。 ChatGPTにストーリーの執筆を依頼します。ゲームに関する多くのコンテキストを提供した後、ChatGPTにストーリーの要約を書いてもらいます。 ChatGPTは、ゲームStardew…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.