Learn more about Search Results MPT - Page 50

- You may be interested
- 「知っておくべき3つの一般的な時系列モデ...
- AIはリアルなターミネーターになることが...
- 「VSCodeをDatabricksと統合して、データ...
- 「犬レベルのAIから神レベルのAIへ向かって」
- 「Pymcと統計モデルを記述するための言語...
- 2023年の音楽制作に最適なAIツール
- 「SceneTexをご紹介:屋内シーンにおける...
- 「You.comがYouRetrieverをリリース:You....
- 「教師なし学習シリーズ — セルフオーガナ...
- 「2023年の写真とビデオのための10のAIデ...
- データサイエンスチートシートのためのBard
- 自撮りがコミュニケーション手段としてど...
- 「ODSC Westでの対面トレーニングがチーム...
- あなた全体に装着可能なロボットアシスタント
- 「ShutterstockがエシカルAIと顧客保護の...

「Amazon SageMakerの非同期エンドポイントを使用して、Amazon SageMaker JumpStartの基礎モデルのデプロイコストを最適化する」
この投稿では、これらの状況を対象にし、Amazon SageMaker JumpStartからAmazon SageMaker非同期エンドポイントに大規模な基盤モデルを展開することによって高コストのリスクを解決しますこれにより、アーキテクチャのコストを削減し、リクエストがキューにある場合や短い生存期間のみエンドポイントを実行し、リクエストが待機している場合にはゼロにスケーリングダウンしますこれは多くのユースケースにとって素晴らしいですが、ゼロにスケーリングダウンしたエンドポイントは、推論を提供できる前に冷たいスタート時間を導入します

「Amazon SageMaker JumpStart上で、生成型AIベースのコンテンツモデレーションソリューションを構築する」
この記事では、マルチモーダルな事前学習と大規模な言語モデル(LLM)を使用した画像データのコンテンツモデレーションの新しい手法を紹介しますマルチモーダルな事前学習により、興味のある質問のセットに基づいて直接画像のコンテンツをクエリすることができ、モデルはこれらの質問に答えることができますこれにより、ユーザーは画像とチャットして、組織のポリシーに違反するような不適切なコンテンツが含まれているかを確認することができますLLMの強力な生成能力を利用して、安全/危険なラベルやカテゴリータイプを含む最終的な意思決定を生成しますさらに、プロンプトを設計することで、LLMに指定された出力形式(JSON形式など)を生成させることができます設計されたプロンプトテンプレートにより、LLMは画像がモデレーションポリシーに違反しているかどうかを判断し、違反のカテゴリーを特定し、なぜ違反しているのかを説明し、構造化されたJSON形式で出力を提供することができます

ReactとExpressを使用してChatGPTパワードおよび音声対応のアシスタントを構築する
現代の世界において、大規模な言語モデルがますます人気を集めるにつれて、それらを開発に使用する関心も高まっていますが、どこから始めれば良いかを理解することは常に容易ではありませんこの記事では、ChatGPT言語を活用したシンプルなチャットボットの構築方法について説明します...

「翼を広げよう:Falcon 180Bがここにあります」
はじめに 本日は、TIIのFalcon 180BをHuggingFaceに歓迎します! Falcon 180Bは、オープンモデルの最新技術を提供します。1800億のパラメータを持つ最大の公開言語モデルであり、TIIのRefinedWebデータセットを使用して3.5兆トークンを使用してトレーニングされました。これはオープンモデルにおける最長の単一エポックの事前トレーニングを表しています。 Hugging Face Hub(ベースモデルとチャットモデル)でモデルを見つけることができ、Falcon Chat Demo Spaceでモデルと対話することができます。 Falcon 180Bは、自然言語タスク全体で最先端の結果を実現しています。これは(事前トレーニング済みの)オープンアクセスモデルのリーダーボードをトップし、PaLM-2のようなプロプライエタリモデルと競合しています。まだ明確にランク付けすることは難しいですが、PaLM-2 Largeと同等の性能を持ち、Falcon 180Bは公に知られている最も能力のあるLLMの一つです。 このブログ投稿では、いくつかの評価結果を見ながらFalcon 180Bがなぜ優れているのかを探求し、モデルの使用方法を紹介します。 Falcon-180Bとは何ですか? Falcon 180Bはどれくらい優れていますか? Falcon 180Bの使用方法は? デモ ハードウェア要件…
このAIニュースレターは、あなたが必要なすべてです#63
「AIの今週のハイライトでは、Large Language Models(LLM)の採用による西洋市場での収益成長のさらなる証拠と、新しいAIモデルの導入を紹介しています...」

ローカルマシン上でGenAI LLMsのパワーを解放しましょう!
はじめに GenAI LLMsのリリース以来、私たちはそれらをある方法または別の方法で使用しています。最も一般的な方法は、OpenAIのウェブサイトなどのウェブサイトを介して、OpenAIのGPT3.5 API、GoogleのPaLM API、またはHugging Face、Perplexity.aiなどの他のウェブサイトを介してChatGPTやLarge Language Modelsを使用することです。 これらのアプローチのいずれにおいても、私たちのデータはコンピュータの外部に送信されます。これらのウェブサイトは最高のセキュリティを保証しているとはいえ、何が起こるかわかりませんので、サイバー攻撃のリスクがあるかもしれません。時には、これらのLarge Language Modelsをローカルで実行し、可能であればローカルでチューニングしたい場合もあります。この記事では、Oobaboogaを使用して、つまりLLMsをローカルで設定する方法について説明します。 学習目標 ローカルシステムに大規模な言語モデルを展開することの意義と課題を理解する。 大規模な言語モデルを実行するためのローカル環境を作成する方法を学ぶ。 与えられたCPU、RAM、およびGPU Vramの仕様で実行できるモデルを調べる。 Hugging Faceから任意の大規模な言語モデルをローカルで使用するためのダウンロード方法を学ぶ。 大規模な言語モデルを実行するためにGPUメモリを割り当てる方法を確認する。 この記事はData Science Blogathonの一環として公開されました。 Oobaboogaとは何ですか? OobaboogaはLarge…

GGMLとllama.cppを使用してLlamaモデルを量子化する
この記事では、私たちはGGMLとllama.cppを使用してファインチューニングされたLlama 2モデルを量子化しますその後、GGMLモデルをローカルで実行し、NF4、GPTQ、およびGGMLのパフォーマンスを比較します
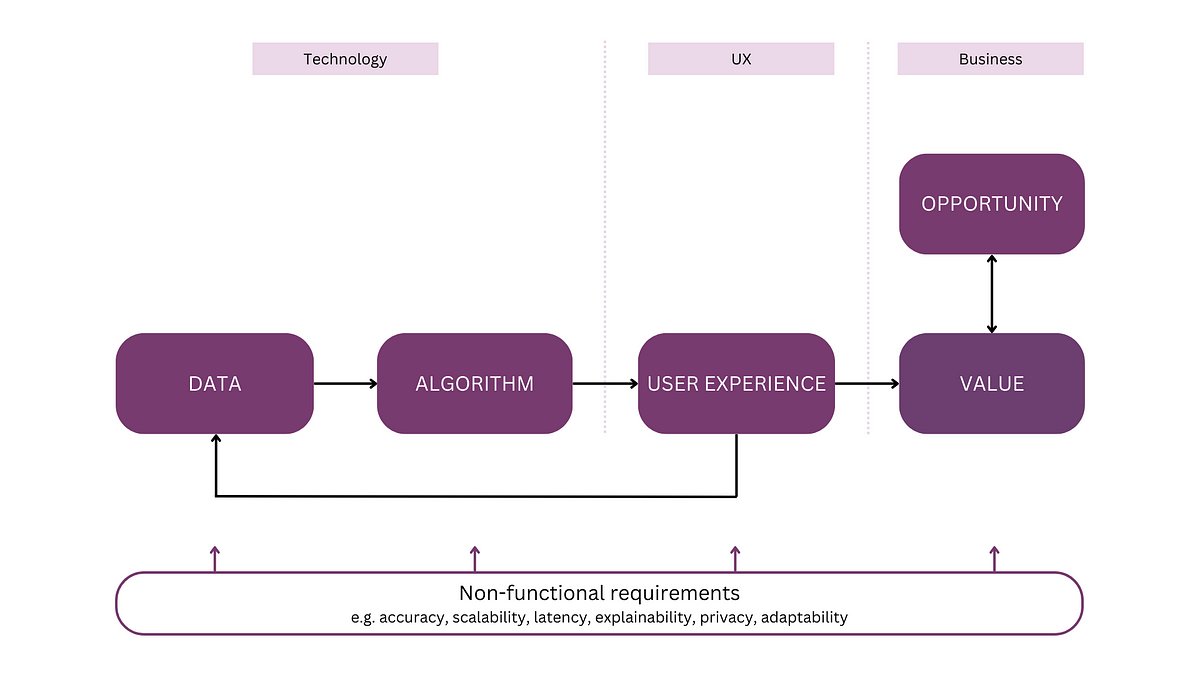
「全体的なメンタルモデルを持つAI製品の開発」
注:この記事は「AIアプリケーションの解析」というシリーズの最初の記事ですこのシリーズでは、AIシステムのためのメンタルモデルを紹介しますこのモデルは、議論や計画、そして...のためのツールとして機能します
「Declarai、FastAPI、およびStreamlitを使用したLLMチャットアプリケーション— パート2 🚀」
前回のVoAGI記事(リンク🔗)の人気を受けて、LLMチャットアプリケーションの展開について詳しく説明しました皆様からのフィードバックを参考に、この第二部ではさらに高度な内容を紹介します
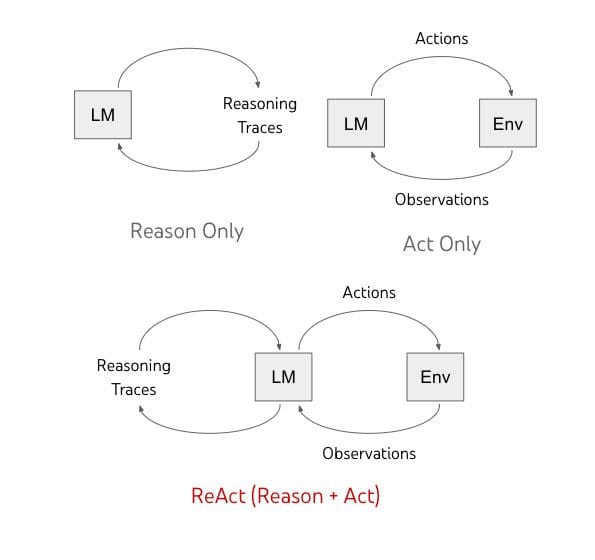
ReAct、Reasoning and Actingは、LLMをツールで拡張します!
「AIは推論と行動を融合させ、人間の知能を模倣するという大胆な新たな一歩を踏み出しています」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.