Learn more about Search Results 6. 結論 - Page 50

- You may be interested
- 「LLMsの信頼性のあるフューショットプロ...
- 「Apache Sparkにおける出力ファイルサイ...
- 「Amazon SageMaker JumpStartで利用可能...
- 「Kerasを使用したニューラルネットワーク...
- 人間の脳プロジェクトによるマッピングは...
- 「2023年のAi4カンファレンスでジェネレー...
- ソフトウェアセキュリティ、サプライチェ...
- データ解析の刷新:OpenAI、LangChain、Ll...
- 「Pythonのグローバル変数は本当にグロー...
- 「量子コンピュータを使用して暗黒物質を...
- 「2023年の最高のAI文法チェッカーツール」
- 「機械学習モデルのトレーニングに使用す...
- ハリウッドにおけるディズニーの論争:AI...
- マルコフ報酬の表現力について
- UCバークレーとスタンフォードの研究者チ...
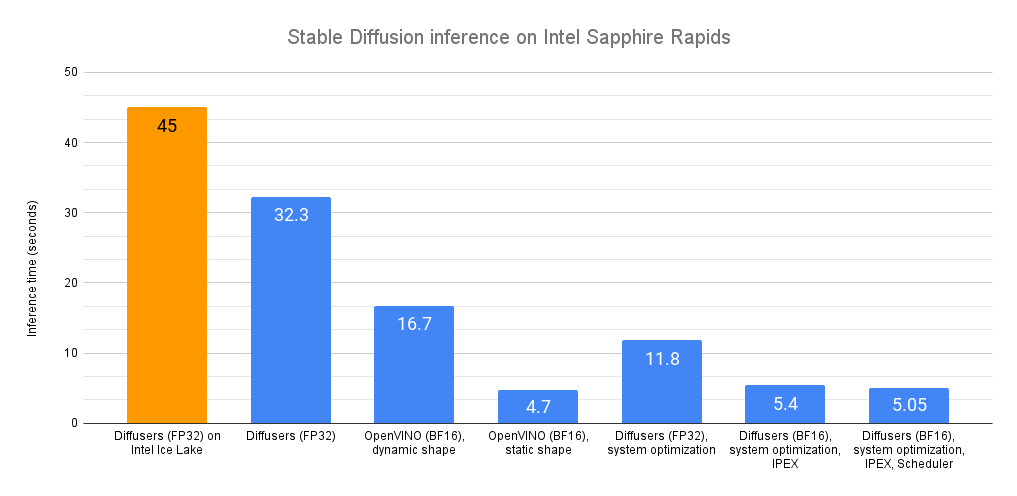
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…

単一のGPUでChatgptのようなチャットボットをROCmで実行する
はじめに ChatGPTは、OpenAIの画期的な言語モデルであり、人工知能の領域で影響力のある存在となり、様々なセクターでAIアプリケーションの多様な活用を可能にしています。その驚異的な人間のようなテキストの理解力と生成力により、ChatGPTは顧客サポートから創造的な文章作成まで、さまざまな産業を変革し、貴重な研究ツールとしても使われています。 OPT、LLAMA、Alpaca、Vicunaなど、大規模な言語モデルのオープンソース化にはさまざまな取り組みが行われていますが、その中でもVicunaはAMD GPU上でROCmを使用してVicuna 13Bモデルを実行する方法を説明します。 Vicunaとは何ですか? Vicunaは、UCバークレー、CMU、スタンフォード、UCサンディエゴのチームによって開発された13兆パラメータを持つオープンソースのチャットボットです。Vicunaは、LLAMAベースモデルを使用して、ShareGPT.comからの約70,000件のユーザー共有会話を収集し、公開APIを介してファインチューニングしました。GPT-4を参照とした初期の評価では、Vicuna-13BはOpenAI ChatGPTと比較して90%以上の品質を実現しています。 それはわずか数週間前の4月11日にGithubでリリースされました。Vicunaのデータセット、トレーニングコード、評価メトリック、トレーニングコストはすべて公開されており、一般のユーザーにとって費用対効果の高いソリューションとなっています。 Vicunaの詳細については、https://vicuna.lmsys.org をご覧ください。 なぜ量子化されたGPTモデルが必要なのですか? Vicuna-13Bモデルをfp16で実行するには、約28GBのGPU RAMが必要です。メモリの使用量をさらに減らすためには、最適化技術が必要です。最近発表された研究論文「GPTQ」では、低ビット精度を持つGPTモデルの正確な事後トレーニング量子化が提案されています。以下の図に示すように、パラメータが10Bを超えるモデルの場合、4ビットまたは3ビットのGPTQはfp16と同等の精度を実現することができます。 さらに、これらのモデルの大きなパラメータは、GPTトークン生成が計算(TFLOPsまたはTOPs)そのものよりもメモリ帯域幅(GB/s)によって制約されるため、GPTのレイテンシに深刻な影響を与えます。そのため、メモリに制約のある状況下では、量子化モデルはトークン生成のレイテンシを低下させません。GPTQの量子化の論文とGitHubリポジトリを参照してください。 この技術を活用することで、Hugging Faceからいくつかの4ビット量子化されたVicunaモデルが利用可能です。 ROCmを使用してAMD GPUでVicuna 13Bモデルを実行する AMD GPUでVicuna 13Bモデルを実行するには、AMD GPUの高速化のためのオープンソースソフトウェアプラットフォームであるROCm(Radeon…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...

MLモデルのパッケージング【究極のガイド】
機械学習モデルを数週間または数カ月かけて構築したことがありますか?そして、後でそれを本番環境に展開するのが複雑で時間がかかることがわかりましたか?または、モデルの複数のバージョンを管理し、展開に必要な依存関係と設定をすべて追跡するのに苦労しましたか?もし頷いているのであれば、...

エンドツーエンドのMLパイプラインの構築方法
コミュニティ内のMLエンジニアから最もよく聞かれる不満の1つは、モデルの構築と展開のMLワークフローを手動で行うことがどれだけ費用がかかり、エラーが発生しやすいかということです彼らはトレーニングデータを前処理するためにスクリプトを手動で実行し、展開スクリプトを再実行し、モデルを手動で調整し、働く時間を費やします...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...

MLにおけるETLデータパイプラインの構築方法
データ処理から迅速な洞察まで、頑強なパイプラインはどんなMLシステムにとっても必須ですデータチーム(データとMLエンジニアで構成される)はしばしばこのインフラを構築する必要があり、この経験は苦痛となることがありますしかし、MLでETLパイプラインを効率的に使用することで、彼らの生活をはるかに楽にすることができます本記事では、その重要性について探求します...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.