Learn more about Search Results リポジトリ - Page 50

- You may be interested
- OpenAIのCEOであるSam Altman氏:AIの力が...
- ビッグデータアプリケーションのクラウド...
- 「トップ40以上の創発的AIツール(2023年1...
- 「金融機関は責任あるAIを活用して金融犯...
- マシンラーニングに取り組むため、プライ...
- 自律AIエージェント:データサイエンスと...
- PythonからJuliaへ:基本的なデータ操作とEDA
- 「2024年に必ず試してみるべきトップ15の...
- モデルオプスとは何ですか?
- ノースウェスタン大学の研究者は、AIのエ...
- 「OpenAI関数呼び出しの紹介」
- ニュースグループが報道内容に大いに依存...
- 「最初の原則から旅行セールスマン問題を...
- マイクロソフトの研究者が、言語AIを活用...
- AI音声認識をUnityで
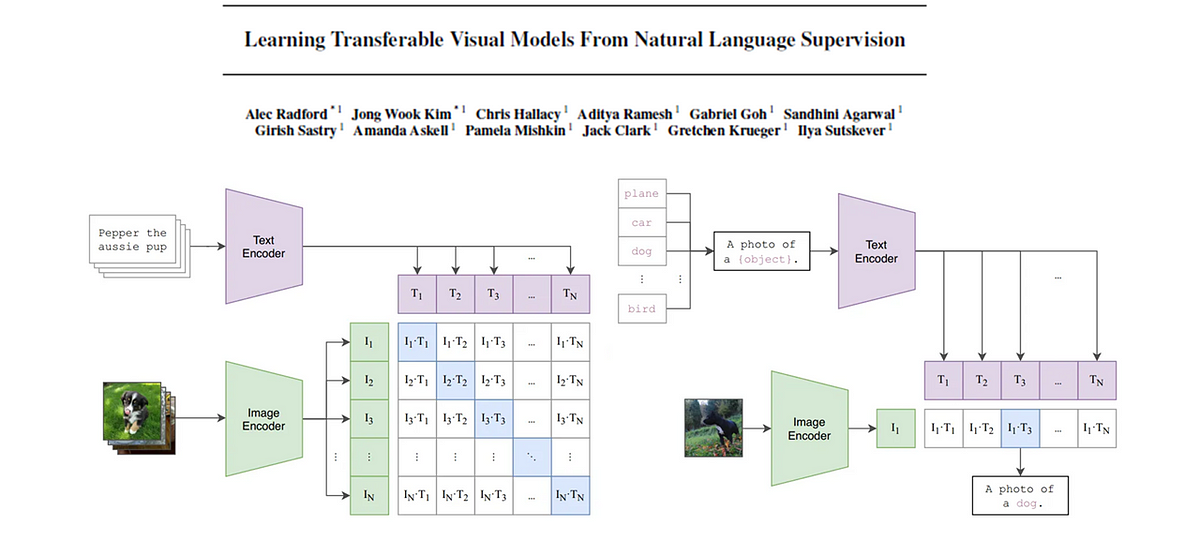
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...
「慢性腎臓病の予測:新しい視点」
「腎臓は、血液から廃物、毒素、余分な水分を取り除くために一生懸命働きますその適切な機能は健康にとって重要です慢性腎臓病(CKD)は、…」
「より良い機械学習システムの構築 – 第3章:モデリング楽しみが始まります」
こんにちは、お帰りなさいまたここでお会いできてうれしいですあなたがもっと良いプロフェッショナルになりたいという意欲、より良い仕事をしたいという願望、そしてより良いMLシステムを構築したいということを本当に感謝していますあなたは素晴らしいです、これからも頑張ってください!このシリーズでは、私は...

パスワードを使用したGit認証の非推奨化
私たちはサービスのセキュリティ向上に取り組んでいるため、Hugging Face Hubを介してGitを使用してやり取りする際の認証方法を変更しています。2023年10月1日以降、パスワードによるコマンドラインGit操作の認証は受け付けなくなります。代わりに、パーソナルアクセストークンやSSHキーなどのより安全な認証方法の使用をお勧めします。 背景 最近数ヶ月間、サインインアラートやGitでのSSHキーのサポートなど、さまざまなセキュリティ強化を実施してきました。しかし、ユーザーはまだユーザー名とパスワードでGit操作を認証することができました。セキュリティをさらに向上させるため、トークンベースまたはSSHキー認証に移行します。トークンベースおよびSSHキー認証は、セキュリティと制御を向上させるユニークな、取り消し可能な、ランダムな機能を提供します。 今日の必要なアクション 現在、HFアカウントのパスワードを使用してGitと認証している場合は、2023年10月1日までにパーソナルアクセストークンまたはSSHキーを使用するように切り替えてください。 パーソナルアクセストークンへの切り替え アカウントのアクセストークンを生成する必要があります。以下の手順に従って、トークンを生成できます: https://huggingface.co/docs/hub/security-tokens#user-access-tokens アクセストークンを生成した後、以下のコマンドを使用してGitリポジトリを更新できます: $: git remote set-url origin https://<user_name>:<token>@huggingface.co/<user_name>/<repo_name> $: git pull origin または新しいリポジトリをクローンする場合、Git認証情報を求められたときにパスワードの代わりにトークンを入力することもできます。 SSHキーへの切り替え SSHキーを生成し、アカウントに追加するためのガイドに従ってください:…

『AI入門』
「ここでは、AIの学び方についての私の以前の記事を読んでいることを前提としています再度お伝えしますが、機械学習を学ぶ際には、ドキュメンテーション以外の複数の情報源を参照することを強くお勧めします...」
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキュメントを迅速に処理するための方法を提供しますか?この記事では、トランスフォーマーを使用して、テーブルの存在だけでなく、テーブルの構造を画像から認識する方法を見ていきます。これは、2つの異なるモデルによって実現されます。1つはドキュメント内のテーブルの検出のためのもので、もう1つはテーブル内の個々の行と列を認識するためのものです。 学習目標 画像上のテーブルの行と列を検出する方法 Table TransformersとDetection Transformer(DETR)の概要 PubTables-1Mデータセットについて Table Transformerでの推論の実行方法 ドキュメント、記事、PDFファイルは、しばしば重要なデータを伝えるテーブルを含む貴重な情報源です。これらのテーブルから情報を効率的に抽出することは、異なるフォーマットや表現の間の課題により複雑になる場合があります。これらのテーブルを手動でコピーまたは再作成するのは時間がかかり、ストレスがかかることがあります。PubTables-1Mデータセットでトレーニングされたテーブルトランスフォーマーは、テーブルの検出、構造の認識、および機能分析の問題に対処します。 この記事はData Science Blogathonの一環として公開されました。 この方法はどのように実現されたのですか? これは、PubTables-1Mという名前の大規模な注釈付きデータセットを使用して、記事などのドキュメントや画像を検出するためのトランスフォーマーモデルであるTable Transformerによって実現されました。このデータセットには約100万のパラメータが含まれており、いくつかの手法を用いて実装されており、モデルに最先端の感触を与えています。効率性は、不完全な注釈、空間的な整列の問題、およびテーブルの構造の一貫性の課題に取り組むことで達成されました。モデルとともに公開された研究論文では、テーブルの構造認識(TSR)と機能分析(FA)のジョイントモデリングにDetection Transformer(DETR)モデルを活用しています。したがって、DETRモデルは、Microsoft Researchが開発したTable Transformerが実行されるバックボーンです。DETRについてもう少し詳しく見てみましょう。 DEtection TRansformer(DETR) 前述のように、DETRはDEtection TRansformerの略であり、エンコーダーデコーダートランスフォーマーを使用したResNetアーキテクチャなどの畳み込みバックボーンから構成されています。これにより、オブジェクト検出のタスクを実行する潜在能力を持っています。DETRは、領域提案、非最大値抑制、アンカー生成などの複雑なモデル(Faster…

「Snorkel AI x Hugging Face 企業向けの基盤モデルを解放する」
この記事は、2023年4月6日にSnorkelのブログでFriea Bergによって最初に公開された記事をクロスポストしています。 OpenAIがGPT-4をリリースし、Googleがベータ版でBardを導入するにつれて、世界中の企業は基盤モデルの力を活用することに興奮しています。この興奮が高まるにつれて、ほとんどの企業や組織が基盤モデルを適切に活用するための準備ができていないことが明らかになっています。 基盤モデルは企業にとって独自の課題を提供します。これまで以上に大きくなったサイズのため、自社でホストすることは困難で高額になります。また、製品の使用ケースにオフシェルフのFMsを使用することは、パフォーマンスの低下やガバナンスとコンプライアンスのリスクの増加を意味する可能性があります。 Snorkel AIは、基盤モデルと実際の企業の使用ケースとのギャップを埋める役割を果たしており、PixabilityなどのAIイノベーターによって印象的な結果をもたらしています。我々は、大量の使いやすいオープンソースモデルのリポジトリで最もよく知られているHugging Faceと提携し、AIアプリケーションの開発に柔軟性と選択肢を提供します。 Snorkel Flowにおける基盤モデル Snorkel Flow開発プラットフォームを使用すると、ユーザーは基盤モデルを特定の使用ケースに適応させることができます。アプリケーションの開発は、データ上の選択した基盤モデルの予測を「そのまま」検査することから始まります。これらの予測は、それらのデータポイントのトレーニングラベルの初期バージョンとなります。Snorkel Flowは、そのモデルのエラーモードを特定し、プログラムによるラベリングを効率的に修正するためのユーザーを支援します。これには、ヒューリスティックやプロンプトを使用したトレーニングラベルの更新が含まれる場合もあります。基盤モデルは、更新されたラベルで微調整され、再評価されます。この反復的な「検出と修正」プロセスは、適応された基盤モデルが十分な品質に達するまで続きます。 Hugging Faceは、この強力な開発プロセスを可能にするために、150,000以上のオープンソースモデルを1つのソースから直ちに利用できるようにしています。これらのモデルの多くは、BioBERTやSciBERTなどの特定のドメインのデータに特化しています。これらのモデルの1つ、あるいはさらに良い場合は複数の特化したベースモデルは、ユーザーに初期予測やラベルの改善のためのプロンプト、または展開用の最終モデルの微調整のスタートを与えることができます。 Hugging Faceはどのように役立ちますか? Snorkel AIのHugging Faceとのパートナーシップにより、Snorkel Flowの基盤モデルの機能が強化されます。最初はわずかな数の基盤モデルのみを提供していました。それぞれが専用のサービスを必要とし、費用対効果が低く、急速に増え続けるさまざまなモデルを提供することが難しかったため、企業が柔軟に利用できるようにすることは困難でした。Hugging FaceのInference Endpointサービスを採用することで、ユーザーが利用できる基盤モデルの数を拡大することができました。 Hugging Faceのサービスを使用すると、ユーザーは数回のクリックでモデルAPIを作成し、すぐに使用することができます。重要なのは、この新しいサービスには「一時停止と再開」の機能があり、クライアントが必要な場合にモデルAPIをアクティブにし、必要ない場合には休眠させることができる点です。…

Databricks ❤️ Hugging Face 大規模言語モデルのトレーニングとチューニングが最大40%高速化されました
生成AIは世界中で大きな注目を集めています。データとAIの会社として、私たちはオープンソースの大規模言語モデルDollyのリリース、およびそれを微調整するために使用した研究および商用利用のための内部クラウドソーシングデータセットであるdatabricks-dolly-15kのリリースと共にこの旅に参加してきました。モデルとデータセットはHugging Faceで利用可能です。このプロセスを通じて多くのことを学びましたが、今日はApache Spark™のデータフレームから簡単にHugging Faceデータセットを作成できるようにするHugging Faceコードベースへの初めての公式コミットの1つを発表することを喜んでお知らせします。 「Databricksがモデルとデータセットをコミュニティにリリースしてくれたのを見るのは素晴らしいことでしたが、それをHugging Faceへの直接のオープンソースコミットメントにまで拡張しているのを見るのはさらに素晴らしいことです。Sparkは、大規模なデータでの作業に最も効率的なエンジンの1つであり、その技術を使用してHugging Faceのモデルをより効果的に微調整できるようになったユーザーを見るのは素晴らしいことです。」 — Clem Delange、Hugging Face CEO Hugging Faceが一流のSparkサポートを受ける 過去数週間、ユーザーから、SparkのデータフレームをHugging Faceデータセットに簡単にロードする方法を求める多くのリクエストを受け取りました。今日のリリースよりも前は、SparkのデータフレームからHugging Faceデータセットにデータを取得するために、データをParquetファイルに書き込み、それからHugging Faceデータセットをこれらのファイルに指定して再ロードする必要がありました。たとえば: from datasets import load_dataset train_df…

ELT vs ETL 違いと類似点の明らかに
はじめに 現代のデータ駆動型の世界では、シームレスなデータ統合がビジネスの意思決定とイノベーションに重要な役割を果たしています。このプロセスを容易にするために、2つの主要な方法論が登場しています:Extract, Transform, Load(ETL)とExtract, Load, Transform(ELT)。この記事では、ELTとETLを比較し、それぞれの特徴、利点、およびさまざまなユースケースへの適用性について説明します。 ETLとは何ですか? ETLは、抽出(Extraction)、変換(Transformation)、ローディング(Loading)の3つの連続したステップを含む従来のデータ統合プロセスです。抽出フェーズでは、データがさまざまなシステムやデータベースから取得されます。この生データは、ターゲットスキーマに合わせてクリーニング、フォーマット変換、集計処理などの変換が行われます。最後に、変換されたデータは分析とレポートのための中央データウェアハウスにロードされます。ETLは、異なるソースからのデータの統合を中央リポジトリに行う場合に適しています。変換やクレンジングにより、データの品質を向上させ、正確なレポートと分析を実現します。また、ETLはトレンド分析や規制の遵守のための歴史的データの保存も可能にします。 ELTとは何ですか? ELTは、生データのローディングが変換よりも前に行われる、より現代的なデータ統合アプローチです。ELTでは、データがまずデータレイクやクラウドベースのストレージなどの宛先ストレージシステムにロードされ、必要に応じて変換が行われます。 ELTは、リアルタイムモニタリング、異常検知、予測分析などの迅速なデータ洞察が必要なシナリオに非常に適しています。クラウドベースのストレージと処理のスケーラビリティを活用して、ビジネスが大量のデータを処理しながらもレスポンシブ性を維持できるようにします。 ELT vs ETL:プロセス ETLプロセス ETLプロセスは、さまざまなソースからデータを中央データウェアハウスに移動するための伝統的なデータ統合方法です。抽出、変換、ローディングの3つの明確なフェーズが含まれます。 抽出: データはさまざまなシステム、データベース、API、フラットファイルから取得されます。これらのソースは構造化または非構造化の場合があります。データはソースシステムからステージングエリアに抽出およびコピーされます。 変換: このフェーズでは、抽出されたデータはクリーニング、バリデーション、エンリッチメント、集計、フォーマット変換などの変換が行われます。目的は、データが正確で一貫性があり、分析に適した状態になることです。データは共通の形式と構造に変換されます。 ローディング: 変換されたデータは中央データウェアハウスにロードされ、レポートと分析のために整理、インデックス作成、保存されます。ローディングは増分(新しいデータまたは変更されたデータのみ)またはフル(全データセット)で行われる場合があります。 ELTプロセス ELTは、データのローディングが変換よりも前に行われる、より現代的なデータ統合アプローチです。このアプローチは、データレイク、クラウドベースのストレージ、分散システムと共に使用されることがよくあります。…

「AutoGPTQとtransformersを使ってLLMsを軽量化する」
大規模な言語モデルは、人間のようなテキストの理解と生成能力を示し、さまざまなドメインでのアプリケーションを革新しています。しかし、訓練と展開における消費者ハードウェアへの要求は、ますます困難になっています。 🤗 Hugging Faceの主なミッションは、良い機械学習を民主化することであり、これには大規模モデルを可能な限りアクセスしやすくすることも含まれます。bitsandbytesコラボレーションと同じ精神で、私たちはTransformersにAutoGPTQライブラリを統合しました。これにより、ユーザーはGPTQアルゴリズム(Frantar et al. 2023)を使用して8、4、3、または2ビット精度でモデルを量子化して実行できるようになりました。4ビットの量子化ではほとんど精度の低下はなく、推論速度は小規模なバッチサイズの場合にはfp16ベースラインと比較可能です。GPTQメソッドは、校正データセットのパスを必要とする点で、bitsandbytesによって提案された事後トレーニング量子化手法とは若干異なります。 この統合はNvidiaのGPUとRoCm-powered AMDのGPUの両方で利用可能です。 目次 リソース GPTQ論文の簡潔な要約 AutoGPTQライブラリ – LLMの効率的なGPTQの活用のためのワンストップライブラリ 🤗 TransformersでのGPTQモデルのネイティブサポート Optimumライブラリを使用したモデルの量子化 テキスト生成推論を介したGPTQモデルの実行 PEFTを使用した量子化モデルの微調整 改善の余地 サポートされているモデル 結論と最終的な言葉 謝辞…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.